
Вы ведь замечали, что соцсети предлагают добавить в друзья тех, с кем мы когда-либо пересекались, маркетплейсы рекомендуют товары, на которые мы точно обратим внимание, а рекламные объявления точно подстраиваются под наши запросы. Всё это стало возможным благодаря Big Data.
Наука о больших данных используется практически во всех сферах: медицина, бизнес, банковское дело, спортивная индустрия, промышленность, политика, маркетинг и др. Big Data — это важнейший технологический тренд последнего времени, который кардинально изменил возможности использования информации.
В материале расскажем, зачем нужны большие данные и как они помогают компаниям выходить на новый уровень, а специалистам больше зарабатывать.
Содержание статьи скрыть
Что такое Big Data
Объёмные массивы структурированной и неструктурированной информации называют Big Data, или большие данные. Любые наши действия, имеющие информационный след, лишь частичка в бесконечном массиве данных. Банковские транзакции, переписки с друзьями, добавление понравившихся песен в плейлисты, заказы в онлайн-магазинах, пройденные шаги, которые зафиксировал трекер, — вся эта информация хранится в сети и никуда не исчезает.
Что такое Big Data
Большие данные накапливаются с космической скоростью. Одних электронных писем ежесекундно отправляется более трёх миллионов — и это только имейлы, без учёта переписок в мессенджерах и соцсетях. Чтобы в будущем получить полезный срез информации, любые данные нужно быстро обрабатывать и структурировать.
Big Data — это набор инструментов и способов для обработки больших и разнообразных объёмов данных, которые ежесекундно генерируют люди во всём мире.
Ежедневные советы от диджитал-наставника Checkroi прямо в твоем телеграме!
Подписывайся на канал
Подписаться
Основные принципы Big Data
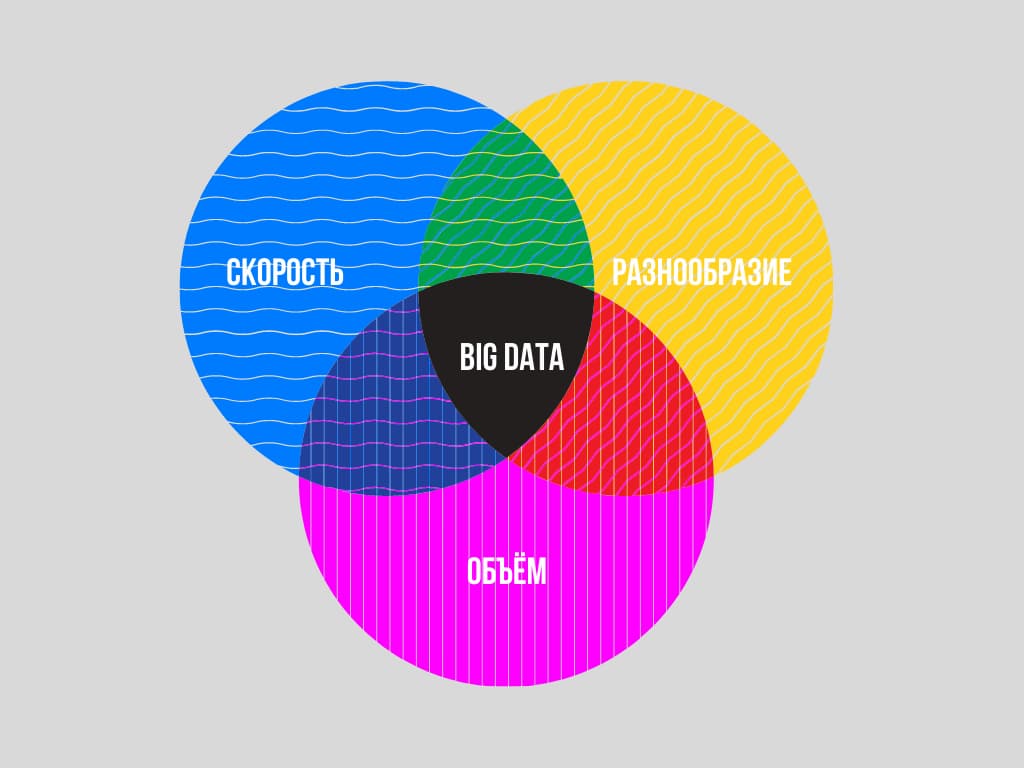
Довольно часто Big Data сравнивают с большой базой данных. Отчасти сравнение верное, но с одной поправкой — информация в такой базе должна соответствовать трём критериям: объём, скорость и разнообразие.
Вот что это значит:
- объём — к большим данным относят те массивы информации, чей объём ежедневного накопления превышает 150 Гб в сутки;
- скорость обновления — большие данные постоянно генерируются и обновляются, а для их обработки требуются высокие технологии;
- разнообразие — накопленные данные всегда неоднородны, они разного формата, могут содержать ошибки, быть структурированы или не структурированы.
Если информации много, но она единого формата и не обновляется, то это не Big Data, а просто объём данных, с обработкой которого сможет справиться обычный Excel
Сегодня Big Data помогает компаниям, корпорациям и целым институтам принимать стратегически правильные решения. Главная задача больших данных — максимально точно собирать и интерпретировать информацию. Поэтому помимо объёма, скорости и разнообразия, в современных системах учитывают ещё два фактора:
Что такое Big Data за 6 минут
- изменчивость — большие данные могут поступать с определённой периодичностью, в конкретные часы или сезоны. Управлять всплесками неструктурированных данных способны лишь сильные технологии обработки;
- ценность — чтобы грамотно структурировать большие массивы данных необходимы технологии, которые позволят определять степень важности поступающей информации.
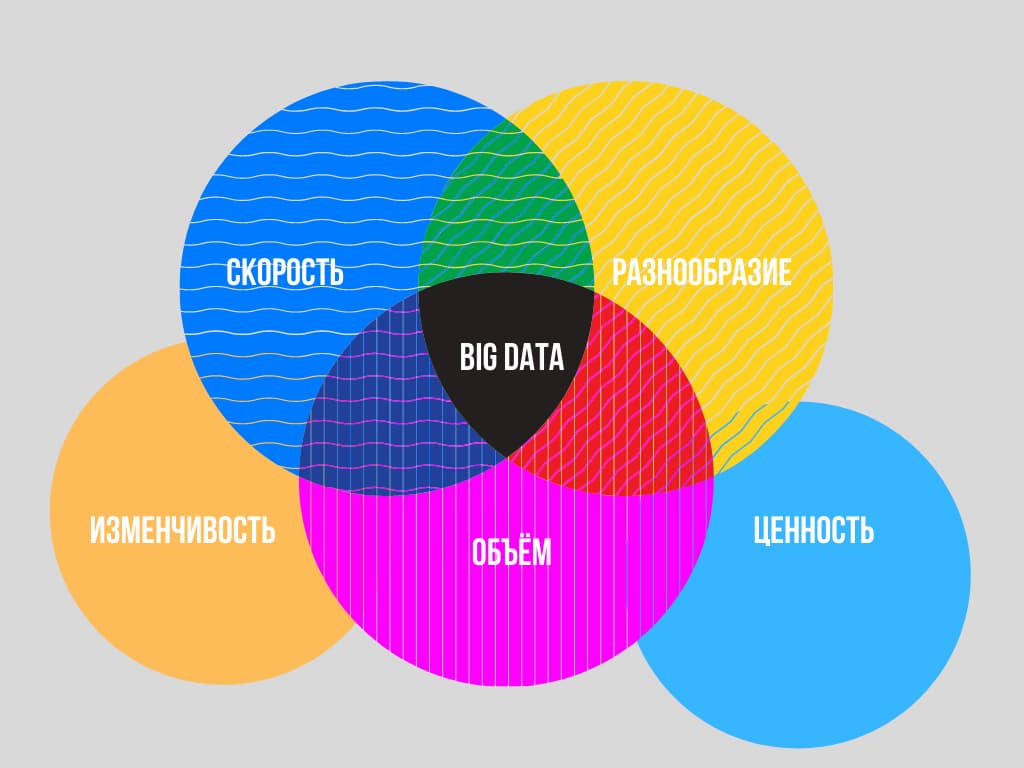
Подобную схему называют « правило 5V»: Volume, Velocity, Variety, Variability, Value
Как собираются и обрабатываются большие данные
Прежде чем получить какую-либо информацию, необходимо собрать данные. Основных источников сбора данных три:
- социальные — это соцсети, сайты, маркетплейсы, форумы и любые другие интернет-ресурсы, на которых пользователи совершают какие-либо действия. Также к социальным источникам стоит отнести статистику разных стран и городов: рождение детей, регистрация браков, медицинские записи и др.;
- машинные — вся информация, поступающая со смартфонов, трекеров, умных вещей, метеорологических станций, спутников и др.;
- транзакционные — к таким источникам относят банковские транзакции, денежные переводы и любые взаимодействия с банкоматами.
Все эти данные хранятся на жёстких дисках наших компьютеров, многочисленных серверах и облачных хранилищах, чтобы обработать такой массив информации необходимы сложные вычислительные системы, которые работают по модели MapReduce.
MapReduce построена на параллельном вычислении, когда все задачи распределяются между разными компьютерами, которые одновременно обрабатывают данные и ищут решение этих задач.
Примерно так устроена модель параллельных вычислений:

Алгоритм MapReduce лежит в основе различных ПО, например, Hadoop и Apache Spark
Какие задачи помогает решать Big Data
Нет ни одной сферы, где бы не пригодились большие данные: сельское хозяйство, государственное управление, медицина, наука, промышленность и др. Big Data позволяет собирать, анализировать и интерпретировать нужную информацию и устанавливать причинно-следственные связи.
Вот ещё несколько примеров, с чем помогает справиться биг дата:
- принимать решения — анализ больших данных позволяет опираться на реальные факты при решении стратегических вопросов. Так, бизнес может понять, стоит ли открывать новый филиал или готов ли потребитель к новому продукту. Представители государственного управления на основе Big Data могут принимать взвешенные решения в различных областях: безопасности, субсидирования, образования, медицины, транспортной логистики и др.;
- строить прогнозы — биг дата позволяет компаниям прогнозировать потребительский спрос, распределять бюджеты и понимать возможный расход ресурсов и потенциальную прибыль;
- находить новые способы решения задач — в больших данных хранятся подсказки для решения актуальных задач. Так, в будущем, массивы информации, собираемые медицинскими клиниками, лабораториями, больницами, фитнес-браслетами и трекерами, позволит ставить более точные диагнозы, изобретать лекарства и быстрее бороться с болезнями;
- оптимизировать процессы — уже сегодня Big Data позволяет банкам, службам доставки, маркетплейсам и другим компаниям обучать чат-ботов и переносить часть обязанностей с реальных специалистов на виртуальных помощников;
- регулировать работу — большие данные позволяют управлять работу как отдельных сфер, так и конкретных предметов. Данные о дорожных происшествиях и ситуациях на дорогах позволяют перераспределять бюджеты и ресурсы сотрудников для обеспечения безопасной и комфортной езды на определённом участке дороги. Также активно развивается сфера интернет-вещей, позволяющая собирать данные о работе бытовых приборов — получив эти сведения, специалисты смогут регулировать и улучшать работу бытовой техники.
Big Data в мире
Благодаря большим данным международной платёжной компании MasterCard удаётся предотвращать действия мошенников и спасать от кражи более 3 млрд долларов на счетах клиентов.
Инструменты Big Data активно применяют не только крупные корпорации — IBM, Google, VISA, MasterCard, но государственные структуры. Так, Big Data помогла правительству Германии сократить количество пособий по безработице и вернуть в бюджет около 15 млрд евро.
Big Data в России
В России большие данные использует общественная организация «Лиза Алерт», специализирующаяся на поиске пропавших без вести людей. Чтобы поисковые операции проходили быстрее и эффективнее, компания «Билайн» разработала инновационную платформу. В ней задействованы решения в области биг дата, что позволяет находить людей, знающих что-либо о пропавшем человеке. По словам представителей «Лиза Алерт», в тех, случая, когда при поиске людей применялись большие данные, процент нахождения людей составлял 89%.
В сети супермаркетов «Лента» используют большие данные для анализа потребительского спроса. Специалисты собирают информацию о предпочтениях и покупках и на основе этих данных предлагают покупателям акционные товары и персонализированные скидки. Например, если вы решите стать веганом или начнёте вести здоровый образ жизни, система заметит изменения в вашей продуктовой корзине и будет предлагать только интересующие вас товары.
Какие специалисты работают с Big Data
Возможности больших данных помогают лучше работать разному кругу специалистов: маркетологам, аналитикам, финансистам, менеджерам и др. Но все они получат уже готовый срез данных, который могут использовать для своих целей.
Прямой же доступ к Big Data есть у тех, кто прошёл специальное обучение и владеет необходимыми инструментами по сбору, анализу и интерпретации огромных массивов информации.
Расскажем о специалистах, которые непосредственно работают с большими данными.
| Профессия | Чем занимается | Узнать подробнее |
| Data Scientist | Собирает и обрабатывает большие массивы данных, чтобы извлекать полезную информацию и строит прогнозы | Профессия «Data scientist» — зарплата, обязанности, необходимые навыки |
| Data-маркетолог | Анализирует данные о товарах, услугах, потребителях и конкурентах. Прогнозирует вероятность успеха маркетинговой кампании и определяет востребованность услуг или товаров на рынке | Профессия «Data-маркетолог» — чем занимается и сколько зарабатывает |
| Data Engineer | Создаёт инфраструктуру для работы с большими данными, систематизирует, перемещает и сохраняет массивы информации | Профессия «Data Engineer» — подробное описание и обзор |
| Аналитик данных | Собирает, изучает и анализирует данные, находит в них закономерности и делает выводы на основе проведённого анализа | Профессия «Аналитик данных» — навыки, обязанности, зарплата |
Где освоить Big Data
Чтобы начать работать с большими данными, потребуются знания математики, программирования и понимание алгоритмов. Освоить Big Data возможно и самостоятельно, но только если уже есть хотя бы небольшой опыт в сфере аналитики данных. Для этого потребуется довольно много времени и желания погружаться в тему методом проб и ошибок.
Если нужен более быстрый путь к большим данным, то стоит пройти обучение на одном из онлайн-курсов. Сегодня многие образовательные платформы предлагают курсы по работе с большими данными.
Big Data от А до Я. Часть 1: Принципы работы с большими данными, парадигма MapReduce

Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен.
Проблематику больших данных постараемся описывать с разных сторон: основные принципы работы с данными, инструменты, примеры решения практических задач. Отдельное внимание окажем теме машинного обучения.
Начинать надо от простого к сложному, поэтому первая статья – о принципах работы с большими данными и парадигме MapReduce.
История вопроса и определение термина
Термин Big Data появился сравнительно недавно. Google Trends показывает начало активного роста употребления словосочетания начиная с 2011 года (ссылка):
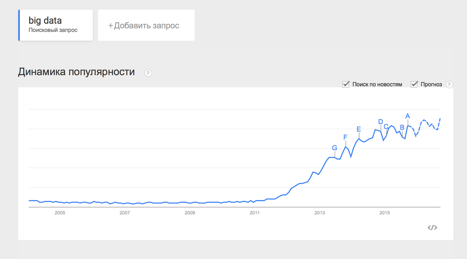
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и осветить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
В этом цикле статей я буду придерживаться определения с wikipedia:
Большие данные (англ. big data) — серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence.
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Принципы работы с большими данными
Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
2. Отказоустойчивость. Принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000 машин (по этой ссылке можно посмотреть размеры кластера в разных организациях). Это означает, что часть этих машин будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того, чтобы им следовать – необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных. Один из самых классических методов я разберу в сегодняшней статье.
MapReduce
Про MapReduce на хабре уже писали (раз, два, три), но раз уж цикл статей претендует на системное изложение вопросов Big Data – без MapReduce в первой статье не обойтись J
MapReduce – это модель распределенной обработки данных, предложенная компанией Google для обработки больших объёмов данных на компьютерных кластерах. MapReduce неплохо иллюстрируется следующей картинкой (взято по ссылке):

MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи.
Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce().
Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Примеры задач, эффективно решаемых при помощи MapReduce
Word Count
Начнём с классической задачи – Word Count. Задача формулируется следующим образом: имеется большой корпус документов. Задача – для каждого слова, хотя бы один раз встречающегося в корпусе, посчитать суммарное количество раз, которое оно встретилось в корпусе.
Раз имеем большой корпус документов – пусть один документ будет одной входной записью для MapRreduce–задачи. В MapReduce мы можем только задавать пользовательские функции, что мы и сделаем (будем использовать python-like псевдокод):
def map(doc): for word in doc: yield word, 1
def reduce(word, values): yield word, sum(values)
Функция map превращает входной документ в набор пар (слово, 1), shuffle прозрачно для нас превращает это в пары (слово, [1,1,1,1,1,1]), reduce суммирует эти единички, возвращая финальный ответ для слова.
Обработка логов рекламной системы
Второй пример взят из реальной практики Data-Centric Alliance.
Задача: имеется csv-лог рекламной системы вида:
,,,,, 11111,RU,Moscow,2,4,0.3 22222,RU,Voronezh,2,3,0.2 13413,UA,Kiev,4,11,0.7 …
Необходимо рассчитать среднюю стоимость показа рекламы по городам России.
def map(record): user_id, country, city, campaign_id, creative_id, payment = record.split(«,») payment=float(payment) if country == «RU»: yield city, payment
def reduce(city, payments): yield city, sum(payments)/len(payments)
Функция map проверяет, нужна ли нам данная запись – и если нужна, оставляет только нужную информацию (город и размер платежа). Функция reduce вычисляет финальный ответ по городу, имея список всех платежей в этом городе.
Резюме
В статье мы рассмотрели несколько вводных моментов про большие данные:
· Что такое Big Data и откуда берётся;
· Каким основным принципам следуют все средства и парадигмы работы с большими данными;
· Рассмотрели парадигму MapReduce и разобрали несколько задач, в которой она может быть применена.
Первая статья была больше теоретической, во второй статье мы перейдем к практике, рассмотрим Hadoop – одну из самых известных технологий для работы с большими данными и покажем, как запускать MapReduce-задачи на Hadoop.
В последующих статьях цикла мы рассмотрим более сложные задачи, решаемые при помощи MapReduce, расскажем об ограничениях MapReduce и о том, какими инструментами и техниками можно обходить эти ограничения.
Спасибо за внимание, готовы ответить на ваши вопросы.
Источник: habr.com
Топ 30 инструментов Big Data (Биг Дата) для анализа данных. Как анализировать данные?
На сегодняшний день существуют тысячи Big Data — инструментов для анализа данных. Анализ данных — это процесс проверки, очистки, преобразования и моделирования данных с целью получения полезной информации, выводов и обоснований для принятия решений. Чтобы сэкономить ваше время, в этой статье перечислю 30 лучших Big Data — инструментов для анализа данных в области инструментов с открытым исходным кодом, инструментов визуализации данных, инструментов анализа настроений, инструментов извлечения данных и баз данных.

Содержание скрыть
Open source инструменты для анализа данных
1. Knime
KNIME Analytics Platform — ведущий open source фреймворк для инноваций, зависящих от данных. Он поможет вам раскрыть скрытый потенциал ваших данных, найти новые свежие идеи, или предсказать будущие тенденции. KNIME Analytics Platform содержит в себе более 1000 модулей, сотни готовых к запуску примеров, широкий спектр интегрированных инструментов и широкий выбор современных доступных алгоритмов, определённо, это идеальный набор инструментов для любого специалиста в data science.
2. OpenRefine
OpenRefine (ранее Google Refine) — это мощный инструмент для работы с сырыми данными: их очистки, преобразования из одного формата в другой и расширения с помощью веб-сервисов и внешних данных. OpenRefine поможет вам с легкостью исследовать большие наборы данных.
3. R-Programming
Что если я скажу вам, что Project R это проект GNU, написанный на самом R? В первую очередь он написан на C и Fortran. И большинство его модулей написаны на самом R. Это открытая среда программирования для статистических вычислений и графики. Язык R широко используется среди майнеров данных для разработки статистического программного обеспечения и анализа данных. Простота его использования и расширяемость значительно повысили популярность R в последние годы. Помимо интеллектуального анализа данных, он предоставляет статистические и графические методы анализа, включая линейное и нелинейное моделирование, классические статистические тесты, анализ временных рядов, классификацию, кластеризацию и другое.
4. Orange
Orange это набор open source инструментов для анализа и визуализации результатов обработки данных, он прекрасно подходить как для экспертов, так и для новичков. Orange предоставляет большой набор инструментов для создания интерактивных рабочих процессов для анализа и визуализации данных. Orange предлагает пользователю различные способы визуализации — от точечных диаграмм, гистограмм, деревьев, до дендрограмм, сетей и тепловых карт.

₽ 0.00 – ₽ 1,499.00

₽ 0.00 – ₽ 9,700.00

₽ 0.00 – ₽ 1,299.00

₽ 0.00 – ₽ 1,999.00

₽ 0.00 – ₽ 1,999.00



₽ 0.00 – ₽ 1,299.00

₽ 0.00 – ₽ 999.00



₽ 0.00 – ₽ 799.00
5. RapidMiner
Как и KNIME, RapidMiner работает через визуальное программирование и способен обрабатывать, анализировать и моделировать данные. Благодаря открытому исходному коду платформы подготовки данных, машинного обучения и развертывания моделей RapidMiner дает командам, изучающим Data Science, больший простор для действий. Единая платформа для обработки данных ускоряет построение полных аналитических рабочих процессов — от подготовки данных и машинного обучения до проверки моделей и развертывания их в единой среде, что значительно повышает эффективность и сокращает время, затрачиваемое на проекты в сфере Data Science.
6. Pentaho
Pentaho уничтожает барьеры, которые мешают вашей компании получить всю выгоду от ваших данных. Платформа упрощает подготовку и трансформацию любых данных и включает в себя спектр инструментов для простого анализа, визуализации, исследования, составления отчетов и прогнозирования. Открытый, встраиваемый и расширяемый, Pentaho спроектирован так, чтобы любой член вашей команды — от разработчиков до бизнес-пользователей мог легко преобразовать данные в нечто стоящее.
7. Talend
Talend это ведущий поставщик программного обеспечения с открытым исходным кодом для компаний, управляющих данными. Наши клиенты подключаются в любом месте, при любой скорости соединения. От конкретного пользователя до облака, от пакетной до потоковой передачи и интеграции данных или интеграции приложений Talend подключается в масштабе больших данных, в 5 раз быстрее и за 20% от стоимости.
8. Weka
Weka, программное обеспечение с открытым исходным кодом, представляет собой набор алгоритмов машинного обучения для задач интеллектуального анализа данных. Алгоритмы могут быть применены непосредственно к набору данных или вызваны из вашего собственного Java-кода. Он также хорошо подходит для разработки новых схем машинного обучения, поскольку полностью реализован на языке программирования Java, а также поддерживает несколько стандартных задач интеллектуального анализа данных.Для тех, кто некоторое время не программировал, Weka с ее графическим интерфейсом, обеспечивает самый простой переход в мир Data Science. Для пользователей с опытом программирования на Java есть возможность встраивать в библиотеку свой собственный код.
9. NodeXL
NodeXL — это программное обеспечение для анализа данных и визуализации, зависимостей и сетей. NodeXL предоставляет точные расчеты. Это бесплатное (но не профессиональное) программное обеспечение для анализа и визуализации сети с открытым исходным кодом. Это один из лучших статистических инструментов для анализа данных, который включает в себя расширенные сетевые метрики, доступ к импортерам данных в социальных сетях и автоматизацию.
10. Gephi
Gephi также представляет собой пакет программного обеспечения для сетевого анализа и визуализации с открытым исходным кодом, написанный на Java на платформе NetBeans. Подумайте об огромных картах дружбы, которые вы видите на LinkedIn или Facebook. Gephi развил это дальше, предоставляя точные расчеты.
Какие существуют программы для для визуализации собранных данных?
11. Datawrapper
Datawrapper — это интерактивный онлайн сервис для создания графиков и таблиц. После того, как вы загрузите данные из файла CSV, PDF или Excel или вставите их непосредственно в поле загрузки, Datawrapper генерирует гистограммы, графики, карты или любую другую связанную визуализацию. Графики Datawrapper можно встроить в любой веб-сайт или CMS с готовым для интеграции кодом. Многие журналисты и новостные организации используют Datawrapper для встраивания графиков в свои статьи. Он очень прост в использовании и создаёт эффективное и понятное визуальное представление информации.
12. Solver
Solver специализируется на предоставлении финансовой отчетности, составлении бюджета и анализа мирового уровня с помощью кнопки доступа ко всем источникам данных, которые обеспечивают рентабельность всей компании. Solver предоставляет инструмент BI360, который доступен как для облачного, так для и локального развертывания, с акцентом на четыре ключевых области аналитики.
13. Qlik
Qlik позволяет создавать визуализации, информационные панели и приложения, которые отвечают на самые важные вопросы вашей компании. Теперь вы можете увидеть всю историю, которая живет в ваших данных.
14. Tableau Public
Tableau демократизирует визуализацию с помощью элегантного, простого и интуитивно понятного инструмента. Он исключительно мощный в бизнесе, потому что он передает информацию через визуализацию данных. В процессе аналитики визуальные эффекты Tableau позволяют вам быстро исследовать гипотезу, верифицировать и просто исследовать данные, прежде чем отправиться в коварное статистическое путешествие.
15. Google Fusion Tables
Fusion Tables работает с Google Spreadsheets гораздо лучше и быстрее, чем его двоюродный брат . Google Fusion Tables — это невероятный инструмент для анализа данных, визуализации больших наборов данных и составления карт. Неудивительно, что невероятное картографическое программное обеспечение Google играет большую роль в продвижении этого инструмента в рейтинге ПО. Возьмите, к примеру, эту карту, которую я сделал, чтобы посмотреть на нефтедобывающие платформы в Мексиканском заливе
16. Infogram
Infogram предлагает более 35 интерактивных диаграмм и более 500 карт, которые помогут вам красиво визуализировать ваши данные. Создайте различные диаграммы, включая гистограммы, круговые диаграммы или облако слов. Добавьте карту к своей инфографике или отчету, чтобы произвести неизгладимое впечатление на вашу аудиторию.
Сентимент-инструменты
17. Opentext
Модуль OpenText Sentiment Analysis — это специализированный механизм классификации, используемый для идентификации и оценки субъективных моделей и выражений настроений в текстовом контенте. Анализ выполняется на уровне темы, предложения и документа и настроен на распознавание того, являются ли части текста фактическими или субъективными, если мнение, выраженное в этих частях контента, является положительным, отрицательным, смешанным или нейтральный.
18. Semantria
Semantria — это инструмент, который предлагает уникальный сервисный подход, собирая тексты, твиты и другие комментарии от клиентов и тщательно их анализируя, чтобы получить действенные и очень ценные идеи. Semantria предлагает анализ текста через API и плагин Excel. Он отличается от Lexalytics тем, что предлагается через API и плагин Excel, и включает в себя большую базу знаний и использует глубокое обучение.
19. Trackur
Автоматический анализ настроений Trackur анализирует конкретное ключевое слово, которое вы отслеживаете, а затем определяет, является ли мнение по этому ключевому слову положительным, отрицательным или нейтральным по отношению к документу. Это основная функция в алгоритме Trackur. Его можно использовать для мониторинга всех социальных сетей и основных новостей, чтобы получить представление руководителей о тенденциях, обнаружении ключевых слов, автоматическом анализе настроений.
20. SAS Sentiment Analysis
Анализ настроений SAS автоматически извлекает настроения в режиме реального времени или в течение определенного периода времени с помощью уникальной комбинации статистического моделирования и методов обработки естественного языка на основе правил. Встроенные отчеты показывают шаблоны и подробные реакции. Таким образом, вы можете отточить выраженные чувства. С помощью текущих оценок вы уточните модели и скорректируете классификации, чтобы отразить возникающие темы и новые термины, относящиеся к вашим клиентам, компании или отрасли.
21. Opinion Crawl
Opinion Crawl — это онлайн-анализ настроений в отношении текущих событий, компаний, продуктов и людей. Opinion Crawl позволяет посетителям оценить настроение в сети по темам: человек, событие, компания или продукт. Выберите тему и вы получите оценку настроения для каждого конкретного случая.
Для каждой темы вы получаете круговую диаграмму, показывающую текущее настроение в режиме реального времени, список заголовков последних новостей, несколько миниатюрных изображений и облако тегов ключевых семантических концепций, которые публика связывает с субъектом. Концепции позволяют вам увидеть, какие проблемы или события положительно влияют на настроение. Для более глубокой оценки веб-сканеры будут находить последние опубликованные материалы по многим популярным темам и текущим публичным вопросам и рассчитывать настроения для них на постоянной основе. Затем в постах блога будет показана тенденция настроений с течением времени, а также соотношение «положительный/отрицательный».
Какие существуют программы для парсинга данных в Интернете?
Отдельно отмечу наш сервис парсинга сайтов и мониторинга цен xmldatafeed.com. Мы на ежедневной основе парсим более 500 крупнейших сайтов России и наши клиенты могут использовать данные для аналитики и более точного ценообразования.

22. Octoparse
Octoparse — это бесплатный и мощный сканер веб-сайтов, используемый для извлечения практически всех видов данных с веб-сайта, которые Вас интересуют. Вы можете использовать Octoparse для копирования веб-сайта с его обширными функциями и возможностями. Его удобный интерфейс помогает людям без опыта программирования быстро привыкнуть к Octoparse. Он позволяет вам парсить весь текст с сайтов использующих AJAX, JavaScript, файлы cookie и, таким образом, вы можете загрузить практически весь контент веб-сайта и сохранить его в структурированном формате, таком как EXCEL, TXT, HTML или в ваши базы данных. Будучи усовершенствованным, он поддерживает запланированный облачный парсинг, позволяющий Вам извлекать динамические данные в режиме реального времени и вести лог-файл.
23. Content Grabber
Content Graber — это программное обеспечение для парсинга в Интернете, предназначенное для компаний. Он может извлекать контент практически с любого веб-сайта и сохранять его в виде структурированных данных в формате по вашему выбору, включая отчеты Excel, XML, CSV и большинство баз данных. Он больше подходит для людей с продвинутыми навыками программирования, поскольку предлагает множество мощных сценариев редактирования, отладки интерфейсов для продвинутых пользователей. Пользователи могут использовать C # или VB.NET для отладки или написания сценариев по управлению процессом парсинга.
24. Import.io
Import.io — это платный веб-инструмент для парсинга данных, позволяющий извлекать информацию с веб-сайтов, что раньше было доступно только специалистам в области программирования. Просто выделите то, что вы хотите, и Import.io пройдёт по сайту и «изучит» то, что вас интересует. Import.io будет парсить, очищать и извлекать данные для анализа или экспорта.
25. Parsehub
Parsehub — это отличный веб-сканер, который поддерживает сбор данных с сайтов, использующих технологии AJAX, JavaScript, файлы cookie и т.д. Его технология машинного обучения позволяет считывать, анализировать а затем преобразовывать веб-документы в готовые данные. В бесплатной версии Parsehub вы можете настроить не более пяти публичных проектов. Платные планы подписки позволяют вам создать как минимум 20 частных проектов для парсинга веб-сайтов.
26.Mozenda
Mozenda — это облачный сервис парсинга. Он предоставляет множество полезных утилит для извлечения данных. Пользователи могут загружать извлеченные данные в облачное хранилище
Базы данных
27. Data.gov
Правительство США пообещало в прошлом году сделать все правительственные данные свободно доступными в интернете. Этот сайт является первым этапом и служит порталом для получения всевозможной удивительной информации обо всем — от климата до преступности.
28. US Census Bureau
Бюро переписи и статистики США — это обширная информация о жизни граждан США, охватывающая данные о населении, географические данные и информацию по образованию.
29. The CIA World Factbook
Общемировая книга фактов, выпускаемая ЦРУ, предоставляет информацию по истории, людям, правительству, экономике, географии, коммуникациям, транспорту, военным и транснациональным проблемам для 267 мировых юридических лиц.
30. PubMed
PubMed, разработанный Национальной медицинской библиотекой (NLM), предоставляет бесплатный доступ к MEDLINE, базе данных из более чем 11 миллионов библиографических ссылок и рефератов из почти 4500 журналов в области медицины, сестринского дела, стоматологии, ветеринарной медицины, фармации, системы здравоохранения и доклинической науки. PubMed также содержит ссылки на полнотекстовые версии статей на веб-сайтах партнерских издателей. Кроме того, PubMed обеспечивает доступ и ссылки на интегрированные базы данных молекулярной биологии, которые ведет Национальный центр биотехнологической информации (NCBI). Эти базы данных содержат последовательности ДНК и белка, данные о трехмерной структуре белка, наборы данных исследования населения и сборки полных геномов в интегрированной системе. Дополнительные библиографические базы данных NLM, такие как AIDSLINE, добавляются в PubMed. PubMed включает в себя «Old Medline». «Old Medline» охватывает промежуток 1950-1965 гг. (Обновляется ежедневно.)
Источник: xmldatafeed.com