
Attention для чайников и реализация в Keras
О статьях по искусственному интеллекту на русском языке
Не смотря на то что механизм Attention описан в англоязычной литературе, в русскоязычном секторе достойного описание данной технологии я до сих пор не встречал. На нашем языке есть много статей по Искусственному Интеллекту (ИИ). Тем не менее, те статьи, которые удалось найти, раскрывают только самые простые модели ИИ, например, свёрточные сети, генеративные сети. Однако, по передовым новейшим разработками в области ИИ статей в русскоязычном секторе крайне мало.
Отсутствие статей на Русском языке по новейшим разработкам стали проблемой для меня, когда я входил в тему, изучал текущее состояние дел в области ИИ. Я хорошо знаю английский, читаю статьи на английском по тематике ИИ. Однако, когда выходит новая концепция или новый принцип ИИ, его понимание на не родном языке бывает мучительным и долгим.
Зная английский, вникнуть на неродном в сложный всё же предмет стоит значительно больше сил и времени. После прочтения описания задаёшь себе вопрос: на сколько процентов ты понял? Если бы была статья на Русском, то понял бы на 100% после первого прочтения. Так произошло с генеративными сетями, по которым есть великолепный цикл статей: после прочтения всё стало понятно. Но в мире сетей есть множество подходов, которые описаны только на английском и с которыми приходилось разбираться днями.
Как иммигрировать в Канаду? Учебная иммиграция и обучение. Новая программа иммиграции в Канаду
Я собираюсь периодически писать статьи на родном языке, привнося в нашу языковую область знания. Как известно, лучший способ разобраться в теме это объяснить её кому-нибудь. Так что кому как не мне начать цикл статей по самым современным, сложным, передовым архитектурном ИИ. К концу статьи сам пойму на 100% подход, и будет польза для кого-то, кто прочитает и улучшит своё понимание (кстати я люблю Gesser, но лучше **Blanche de bruxelles**).
Когда разбираешься в предмете можно выделить 4 уровня понимания:
- ты понял принцип и входы и выходы Алгоритма / Уровня
- ты понял сходы выходы и в общих чертах как оно работает
- ты понял всё вышеперечисленное, а также устройство каждого уровня сети (например, в модели VAE ты понял принцип, а ещё ты понял суть трюка с репараметризацией)
- понял всё включая каждый уровень, так ещё понял, за счёт чего это всё обучается, при чём так, что стал способен подбирать гиперпараметры под свою задачу, а не копипастить готовые решения.
Концепция Attention и применение
Выше приведён сценарий уровней понимания. Чтобы разобрать Attention, начнём с первого уровня. Перед описанием входов и выходов разберём суть: на какие базовые, понятные даже ребёнку, понятия опирается данная концепция. В статье будем использовать английский термин Attention, потому что в таком виде он является также вызовом функции библиотеки Keras (он не реализован в ней прямо, требуется дополнительный модуль, но об этом ниже). Чтобы читать дальше вы должны иметь понимание библиотеки Keras и python, потому что будет приводиться исходный код.

С английского языка Attention переводится как «внимание». Этот термин правильно описывает суть подхода: если вы автомобилист и на фотографии изображён генерал ГИБДД, вы интуитивно придаёте ему важность, вне зависимости от контекста фотографии. Вы скорее всего пристальнее взглянете на генерала. Вы напряжёте глаза, рассмотрите погоны внимательнее: сколько у него там конкретно звёзд.
Если генерал не очень высокий, проигнорируете его. В противном случае учтёте как ключевой фактор при принятии решений. Так работает наш мозг. В Русской культуре мы натренированы поколениями на внимание к высоким чинам, наш мозг автоматически ставит высокий приоритет таким объектам.
Attention представляет собой способ сообщить сети, на что стоит обратить больше внимания, то есть сообщить вероятность того или иного исхода в зависимости от состояния нейронов и поступающих на вход данных. Реализованный в Keras слой Attention сам выявляет на основе обучающей выборки факторы, обращение внимания на которые снижает ошибку сети. Выявление важных факторов осуществляется через метод обратного распространения ошибки, подобно тому как это делается для свёрточных сетей.
При обучении, Attention демонстрирует свою вероятностную природу. Сам по себе механизм формирует матрицу весов важности. Если бы мы не обучали Attention, мы могли бы задать важность, например, эмпирически (генерал важнее прапорщика). Но когда мы обучаем сеть на данных, важность становится функцией вероятности того или иного исхода в зависимости от поступивших на вход сети данных.
Например, если бы проживая в Царской России мы встретили генерала, то вероятность получить шпицрутенов была бы высока. Удостоверившийся в этом можно было бы через несколько личных встреч, собрав статистику. После этого наш мозг выставит соответствующий вес факту встречи данного субъекта и поставит маркеры на погоны и лампасы. Надо отметить, что выставленный маркер не является вероятностью: сейчас встреча генерала повлечёт для вас совершенно иные последствия чем тогда, кроме того вес может быть больше единицы. Но, вес можно привести к вероятности, нормировав его.
Вероятностная природа механизма Attention при обучении проявляется в задачах машинного перевода. Например, сообщим сети, что при переводе с русского на английский слово Любовь переводится в 90% случаев как Love, в 9% случаях как Sex, в 1% случаях как иное. Сеть сразу отметёт множество вариантов, показав лучшее качество обучения. При переводе мы сообщаем сети: «при переводе слова любовь обрати особое внимание на английское слово Love, также посмотри может ли это всё же быть Sex”.
Подход Attention применяться для работы с текстом, а также звуком и временными рядами. Для обработки текста широко используются рекуррентные нейронные сети (RNN, LSTM, GRU). Attention может либо дополнять их, либо заменять их, переводя сеть к более простым и быстрым архитектурам.
Одно из самых известных применений Attention это применение его для того, чтобы отказаться от рекуррентной сети и перейти к полносвязной модели. Рекуррентные сети обладают серией недостатков: невозможность осуществлять обучение на GPU, быстро наступающее переобучение. С помощью механизма Attention мы можем выстроить сеть способную к изучению последовательностей на базе полносвязной сети, обучить её на GPU, использовать droput.
Attention широко применяется для улучшения работы рекуррентных сетей, например, в области перевода с языка на язык. При использовании подхода кодирование / декодирование, которое достаточно часто применяется в современном ИИ (например, вариационные автокодировщики). При добавлении между кодировщиком и декодирокщиком слоя Attention результат работы сети заметно улучшается.
В этой статье я не привожу конкретные архитектуры сетей с использованием Attention, этому будут посвящены отдельные работы. Перечисление всех возможностей применения attention достойно отдельной статьи.
Реализация Attention в Keras из коробки
Когда разбираешься в каком-от подходе, усвоить базовый принцип очень полезно. Но, часто полное понимание приходит только посмотрев на техническую реализацию. Видишь потоки данных, составляющие функцию операции, становится ясно что именно вычисляется. Но сначала его нужно запустить и написать «Attention hello word».
В настоящее время механизм Attention не реализован в самом Keras. Но уже есть сторонние реализации, например attention-keras который можно установить с github. Тогда ваш код станет предельно простым:
from attention_keras.layers.attention import AttentionLayer attn_layer = AttentionLayer(name=’attention_layer’) attn_out, attn_states = attn_layer([encoder_outputs, decoder_outputs])
Данная реализация поддерживает функцию визуализации весов Attention. Обучив Attention можно получить матрицу, сигнализирующую, что по мнению сети особенно важно примерно такого вида (картинка с github со страницы библиотеки attention-keras).

В принципе вам больше ничего не нужно: включите этот код в вашу сеть как один из уровней и наслаждайтесь обучением вашей сети. Любая сеть, любой алгоритм проектируется на первых этапах на концептуальном уровне (как и база данных кстати), после чего реализация до воплощения уточняется в логическом и физическом представлении. Для нейросетей пока данного метода проектирования не разработано (о да, это будет тема моей следующей статьи). Вы же не разбираетесь, как внутри работают слои свёртки? Описан принцип, вы их используете.
Реализация Attention в Keras на низком уровне
Чтобы окончательно разобраться в теме, ниже подробно разберём реализацию Attention под капотом. Концепция хороша, но как именно это работает и почему результат получается именно таким как заявлено?
Простейшая реализация механизма Attention в Keras занимает всего 3 строки:
inputs = Input(shape=(input_dims,)) attention_probs = Dense(input_dims, activation=’softmax’, name=’attention_probs’)(inputs) attention_mul = merge([inputs, attention_probs], output_shape=32, name=’attention_mul’, mode=’mul’
В данном случае в первой строке декларируется слой Input, далее идёт полносвязный слой с функцией активации softmax с количеством нейронов равным количеству элементов в первом слое. Третий слой умножает результат полносвязного слоя на входные данные поэлементно.
Ниже приведён целый класс Attention, реализующий немного более сложный механизм self-attention, который может быть использован как полноценный уровень в модели, класс наследует класс Keras layer.
# Attention class Attention(Layer): def __init__(self, step_dim, W_regularizer=None, b_regularizer=None, W_constraint=None, b_constraint=None, bias=True, **kwargs): self.supports_masking = True self.init = initializers.get(‘glorot_uniform’) self.W_regularizer = regularizers.get(W_regularizer) self.b_regularizer = regularizers.get(b_regularizer) self.W_constraint = constraints.get(W_constraint) self.b_constraint = constraints.get(b_constraint) self.bias = bias self.step_dim = step_dim self.features_dim = 0 super(Attention, self).__init__(**kwargs) def build(self, input_shape): assert len(input_shape) == 3 self.W = self.add_weight((input_shape[-1],), initializer=self.init, name='<>_W’.format(self.name), regularizer=self.W_regularizer, constraint=self.W_constraint) self.features_dim = input_shape[-1] if self.bias: self.b = self.add_weight((input_shape[1],), initializer=’zero’, name='<>_b’.format(self.name), regularizer=self.b_regularizer, constraint=self.b_constraint) else: self.b = None self.built = True def compute_mask(self, input, input_mask=None): return None def call(self, x, mask=None): features_dim = self.features_dim step_dim = self.step_dim eij = K.reshape(K.dot(K.reshape(x, (-1, features_dim)), K.reshape(self.W, (features_dim, 1))), (-1, step_dim)) if self.bias: eij += self.b eij = K.tanh(eij) a = K.exp(eij) if mask is not None: a *= K.cast(mask, K.floatx()) a /= K.cast(K.sum(a, axis=1, keepdims=True) + K.epsilon(), K.floatx()) a = K.expand_dims(a) weighted_input = x * a return K.sum(weighted_input, axis=1) def compute_output_shape(self, input_shape): return input_shape[0], self.features_dim
Здесь мы видим примерно то же самое что было реализовано выше через полносвязный слой Keras, только выполненное через более глубокую логику на более низком уровне.
В функции создаётся параметрический уровень (self.W) который потом скалярно умножается (K.dot) на входной вектор. Логика зашитая в этом варианте немного более cложна: к входному вектору, помноженному на веса self.W, применяется сдвиг (если раскрыт параметр bias), гиперболический тангенс, экспонирование, маска (если она задана), нормирование, после чего входной вектор снова взвешивается по полученному результату. У меня нет описания логики заложенной в этом примере, воспроизвожу операции по чтению кода. Кстати, напишите пожалуйста в комментариях, если вы узнали в этой логике какую-то математическую высокоуровневую функцию.
У класса есть параметр «bias» т.е. предвзятость. Если параметр активирован, то после применения Dense слоя итоговый вектор будет сложен с вектором параметров слоя «self.b» что даст возможность не только определять «веса» для нашей функции внимания, но также смещать уровень внимания на число. Пример из жизни: мы боимся привидений, но ни разу не встречали их. Таким образом мы вносим поправку на страх -100 баллов. То есть только если страх зашкалит за 100 баллов, мы примем решения о защите от привидений, вызове агентства ловцов привидений, покупке отпугивающих устройства и т.д.
Заключение
У механизма Attention есть вариации. Самый простой вариант Attention, реализованный в классе, приведённом выше, называется Self-Attention. Self-attention это механизм предназначенный для обработки последовательных данных с учётом контекста каждой метки времени. Он чаще всего применяется для работы с текстовой информацией.
Реализацию self-attention можно взять из коробки, импортировав библиотеку keras-self-attention. Есть и другие вариации Attention. Изучая англоязычные материалы удалось насчитать более 5 вариаций.
При написании даже этой относительно короткой статьи я изучил более 10 англоязычных статей. Безусловно мне не удалось загрузить все данные из всех этих статей в 5 страниц, я сделал лишь выжимку, с целью создать «руководство для чайников». Чтобы разобрать все нюансы механизма Attention потребуется книжечка страниц на 150-200. Очень надеюсь, мне удалось раскрыть базовую сущность этого механизма чтобы те, кто только начинает разбираться в машинному обучении, поняли как это всё работает.
Источники
- Attention mechanism in Neural Networks with Keras
- Attention in Deep Networks with Keras
- Attention-based Sequence-to-Sequence in Keras
- Text Classification using Attention Mechanism in Keras
- Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-Sequence Prediction
- How to implement the Attention Layer in Keras?
- Attention? Attention!
- Neural Machine Translation with Attention
Источник: habr.com
Система контроля усталости водителя (Attention Assist Mercedes): принцип работы
Работа над повышением уровня безопасности автомобиля не прекращается: ведущие мировые производители постоянно тестируют новые разработки, стремясь свести к минимуму риски для здоровья и жизни людей, находящихся в машине.
Система контроля усталости водителя – одна из мер, положительно сказывающихся на безопасности. Наибольшего успеха в её внедрении добились специалисты компании Mercedes.

Attention Assist: что это?
Кратковременные засыпания водителя во время движения автомобиля – одна из нередко встречающихся причин ДТП (около 25% всех аварий случается именно из-за этого). Особенную опасность представляют длительные монотонные поездки, когда усталость и переутомление от продолжительного вождения накапливаются, но водители стараются не обращать на это внимания, стремясь быстрее добраться до пункта назначения. Как показывает практика, для выхода ситуации на дороге из-под контроля достаточно засыпания всего на пару секунд.

Принцип работы устройства, придуманного инженерами Мерседес, заключается в выявлении симптомов усталости водителя и побуждении его сделать остановку. В ходе исследований было установлено, что реакция снижается более чем у половины людей, проведших за рулем 4 часа без отдыха.
Высокочувствительные устройства контролируют и непрерывно анализируют около 70 параметров (характер использования поворотников, силу нажатия на педали, реакцию на состояние дорожного покрытия и пр.), чтобы вовремя выявить проблему. Крайне важно, чтобы наблюдение за человеком, управляющим автомобилем, велось непрерывно.
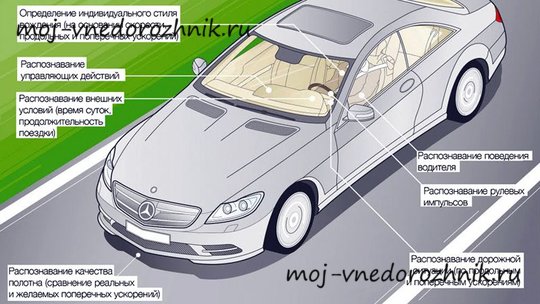
Attention Assist: как работает
Для контроля состояния человека первостепенное значение имеют особенности его поведения за рулем. Как работает система контроля усталости водителя? При помощи датчика, фиксирующего угол поворота руля, система Attention Assist во время первых нескольких минут поездки создает базовый профиль, который в дальнейшем сопоставляется с текущими особенностями управления авто в соответствии с обстановкой на дороге.
Исходя из этого, Attention Assist будет предупреждать водителя при первых признаках усталости громким звуком и текстовым сообщением на экране, сообщая тем самым о необходимости остановки и отдыха.
В настоящее время базовой опцией является Attention Assist в Мерседесах S и E классов. Анализ статистики и проведенные испытания уже неоднократно подтвердили уменьшение числа аварий с участием авто, на которых установлено устройство слежения за состоянием управляющего транспортным средством человека.
Источник: moj-vnedorozhnik.ru
Attention
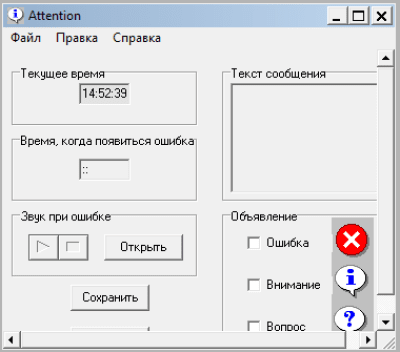
Attention — это программа-розыгрыш. В заданное время появляется ошибка с заданным текстом. Скачивайте Attention с нашего сайта freesoft.ru без смс и регистрации. На сайте расположены программы на различные операционные системы.
Версии
x32/x64 (0.15 МБ)
Нет официального представителя разработчика на сайте
Стать представителем
Рейтинг
Нажмите, для быстрой оценки
Оставить отзыв
Отзывы
Похожие приложения
Alcohol 120%
Версия: 2.1.1.61
Версия: 8.91.0.4 (84.95 МБ)
Версия: 4.0 Buil (10.46 МБ)
Источник: freesoft.ru
Как удалить Attention
Если вы видите Attention Вы используете устаревшую версию Chrome поп-вверх, будьте осторожны. Ита€™s ложь! Возлюбленная€™т верю в это! Предупреждение фиктивных, так и выдуманные. И настоящий знак беды.
Если он появляется на экране, у вас есть рекламное на вашем компьютере. Ита€™s, что Adware, который заставляет всплывающее на Вы, нон-стоп. Все, в надежде, что вы в еще худшие беды. Это может показаться немного запутанным, так что давайте€™s уточнил. Рекламное приложение утянул свой путь в ваш компьютер незаметно. Оказавшись внутри, инструмент распространяет свою злобность во всем.
И вы начинаете осознавать последствия своего пребывания, в кратчайшие сроки. Первоначальные понятия-это отображение Attention Вы используете устаревшую версию Chrome всплывающее окно. Thatâ€™С В infection’с пути, объявив о своем существовании. Он начинает принудительно оповещение о тебе весь день, каждый день, на каждом шагу.
Делайте все возможное, чтобы игнорировать его, и возлюбленная€™т нажмите на нее! Если вы это сделаете, Вы не будете обновлять свой Chrome! Вы уже имеете представление о€™ЛЛ предложить больше вредоносных программ в вашу систему. Так, сделайте себе одолжение, и возлюбленная€™т сделать это. Ита€™s ошибку, вы пожалеете.
Или, даже лучше, чем игнорирование предупреждений, чтобы сделать их остановить. Избавиться от неудобств, которые эти нарушения путем удаления рекламного за ними. Удалить преступника, и you’ЛЛ избежать предупреждения, житья экране. В infection’немедленного удаления с является лучшим курс Вы можете принять. Итак, возьмите его сейчас.
Как я могла заразиться?
Рекламные инструменты подлый. Они€™повторно хорошо разбирались в искусстве обмана. И, удастся проскользнуть на ваш компьютер, необнаруженным. Они делают это, несмотря на то, чтобы просить вашего разрешения, чтобы установить себя. That’с правильным. Инструмент испрашивает вашего разрешения на его допуск.
И, до сих пор умудряется держать вас не обращая внимания на его существование. Как? Ну, просто. Он превращается в хитрость и тонкость. Он использует старый, но золото означает вторжения. Похоже, спам-Сообщений, поддельные обновления, бесплатные программы, поврежденные ссылки.
Доступные способы достаточно плодовитый. Рекламное, за Attention Вы используете устаревшую версию Chrome, ничем не отличается. Он прибегает к обычным выходками, когда дело доходит до вторжения. Да, он по-прежнему добивается Вашего согласия. Но он делает это с таким изяществом, что если you’повторно не достаточно внимательны, that’с его.
Она скользит прямо на вас, незаметно. И, that’с, что эти инфекции рассчитывать. Ваша невнимательность. Так, возлюбленная€™т обеспечить его! Возлюбленная€™т пик, или пропустить делаете вашу должной осмотрительности. Возлюбленная€™т дать в доверчивости.
Возлюбленная€™т бросить предостережение в ветер. Осторожность-это важно, если вы хотите инфекция-бесплатная ПК. Помните, что когда вы что-то разрешить из интернета на ваш компьютер.
Почему эти объявления опасен?
В Attention Вы используете устаревшую версию Chrome всплывающее исна€™т только заражения, с которыми вы сталкиваетесь. Рекламное, за ним стоит, чрезвычайно назойливым. Это не только заставляет предупредить вас, что в любой момент. Но, также наводнение ваш экран с текстом, баннеров и всплывающих окон. А также перенаправить вас на подозрительных сайтах.
Это мешает каждый ваш шаг в интернете. Инфекция doesn’т упустите возможность вмешатся. Это doesn’т займет много времени, прежде чем, что влияет на вашу систему. Он начинает испытывать частые сбои. Ваш компьютер также замедляется к ползанию. Просмотр становится довольно кошмарный опыт. И ваши обиды возлюбленная€™т тебя.
Рекламное doesn’т только пытаться убедить вас, чтобы загрузить обновление, что doesn’т работы. Он делает больше, что прерываю вашу деятельность в интернете. Он также записывает их. Право that’с. Инфекция программирования, чтобы шпионить за вами с момента, когда она вторгается.
Поэтому, когда он решает, он начинает его в шпионаже. Приложение отслеживает каждое ваше движение, в то время как веб-серфинг. И хранит его. Когда она решит, что она собрала достаточно данных, он отправляет его. Да, после того, как он украдет достаточно информации, он подвергает его. Кому?
Ну, вредоносных третьим сторонам, которые опубликовали его. Кибер-преступники с сомнительными намерениями. Возлюбленная€™т позволить. Сохранить, что сценарий разворачивается. Защитите себя и вашей системы.
Удалить Adware, за Attention Вы используете устаревшую версию Chrome всплывающее окно.

Предупреждение, множественные антивирусные сканеры обнаружили возможные вредоносные программы в Attention.
| NANO AntiVirus | 0.26.0.55366 | Trojan.Win32.Searcher.bpjlwd |
| Qihoo-360 | 1.0.0.1015 | Win32/Virus.RiskTool.825 |
| Malwarebytes | v2013.10.29.10 | PUP.Optional.MalSign.Generic |
| Baidu-International | 3.5.1.41473 | Trojan.Win32.Agent.peo |
| Kingsoft AntiVirus | 2013.4.9.267 | Win32.Troj.Generic.a.(kcloud) |
| VIPRE Antivirus | 22224 | MalSign.Generic |
| Tencent | 1.0.0.1 | Win32.Trojan.Bprotector.Wlfh |
| ESET-NOD32 | 8894 | Win32/Wajam.A |
| VIPRE Antivirus | 22702 | Wajam (fs) |
| K7 AntiVirus | 9.179.12403 | Unwanted-Program ( 00454f261 ) |
| McAfee | 5.600.0.1067 | Win32.Application.OptimizerPro.E |
| Malwarebytes | 1.75.0.1 | PUP.Optional.Wajam.A |
| McAfee-GW-Edition | 2013 | Win32.Application.OptimizerPro.E |
поведение Attention
- Перенаправление браузера на зараженных страниц.
- Attention подключается к сети Интернет без вашего разрешения
- Крадет или использует ваши конфиденциальные данные
- Изменяет пользователя Главная страница
- Устанавливает себя без разрешений
- Показывает поддельные предупреждения системы безопасности, всплывающих окон и рекламы.
- Распределяет через платить за установку или в комплекте с программным обеспечением сторонних производителей.
- Интегрируется в веб-браузере через расширение браузера Attention
- Attention показывает коммерческой рекламы
Attention осуществляется версий ОС Windows
- Windows 10 25%
- Windows 8 39%
- Windows 7 22%
- Windows Vista 5%
- Windows XP 9%
География Attention
Ликвидации Attention от Windows
Удалите из Windows XP Attention:
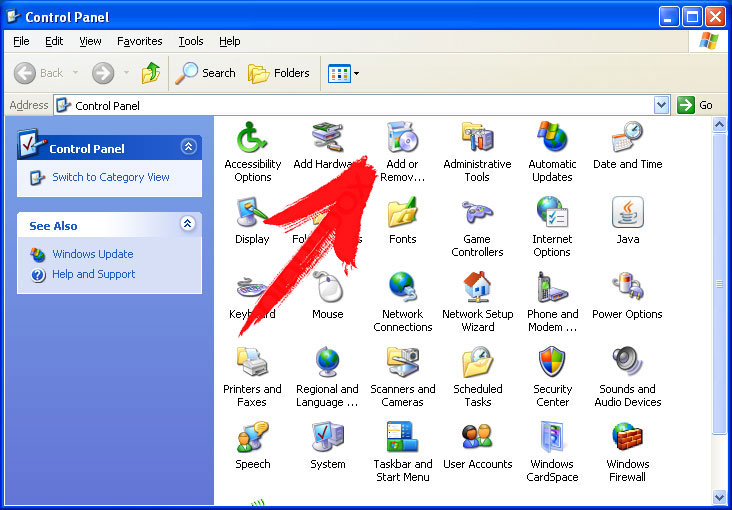
- Нажмите на начать , чтобы открыть меню.
- Выберите Панель управления и перейти на Установка и удаление программ.
- Выбрать и Удалить нежелательные программы.
Удалить Attention от вашего Windows 7 и Vista:
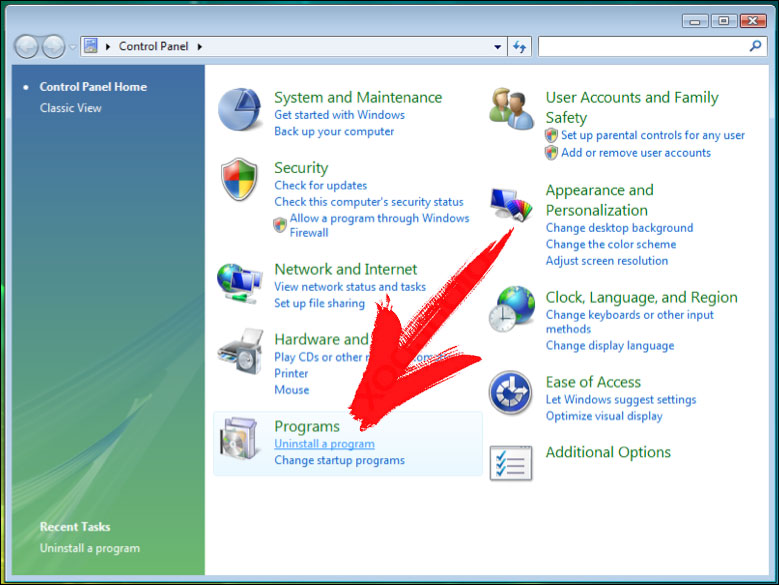
- Откройте меню Пуск и выберите Панель управления.
- Перейти к Удаление программы
- Щелкните правой кнопкой мыши нежелательное приложение и выбрать Удалить.
Стереть Attention от Windows 8 и 8.1:
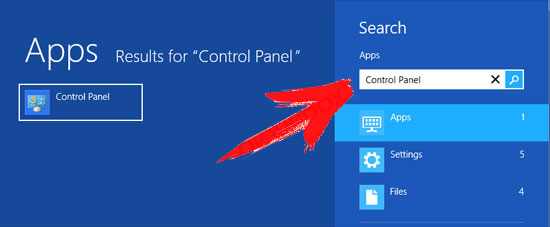
- Щелкните правой кнопкой мыши в нижнем левом углу и выберите Панель управления.
- Выберите удалить программу и щелкните правой кнопкой мыши на нежелательные приложения.
- Нажмите кнопку Удалить .
Удалить из вашего браузеров Attention
Attention Удаление от Internet Explorer
- Нажмите на значок шестеренки и выберите пункт Свойства обозревателя.
- Перейдите на вкладку Дополнительно и нажмите кнопку Сброс.
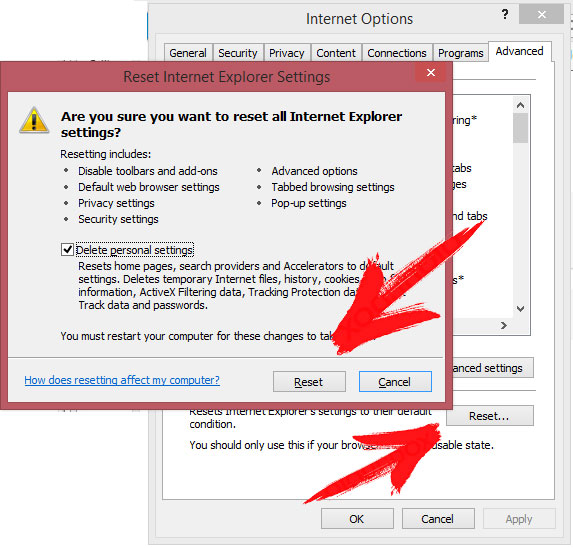
- Проверить, Удалить личные настройки и снова нажмите кнопку Сброс .
- Нажмите кнопку Закрыть и нажмите кнопку OK.
- Вернуться к значок шестеренки, выбрать надстройки → панели инструментов и расширенияи удалить нежелательные расширений.
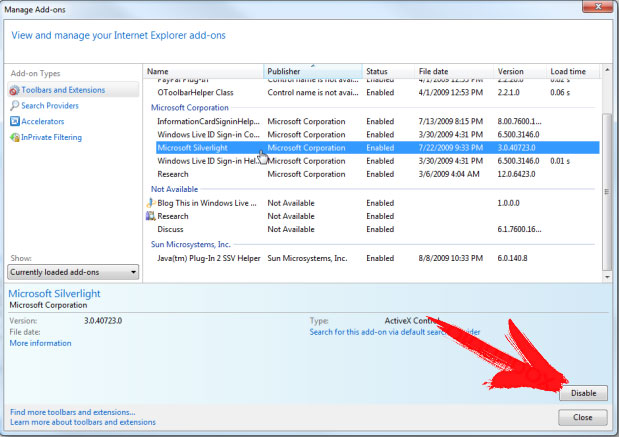
- Перейти к Поставщиков поиска и выбрать новый по умолчанию поисковой системы
Стереть Attention от Mozilla Firefox
- В поле URL введите «about:addons».
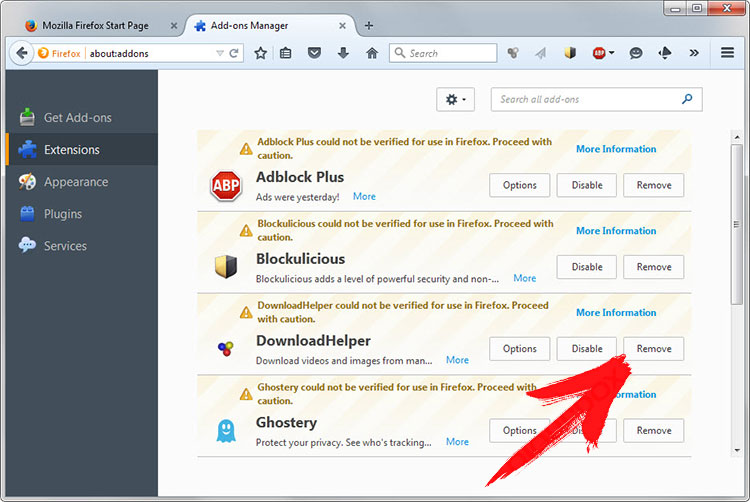
- Перейти к расширения и удалить расширений подозрительных браузера
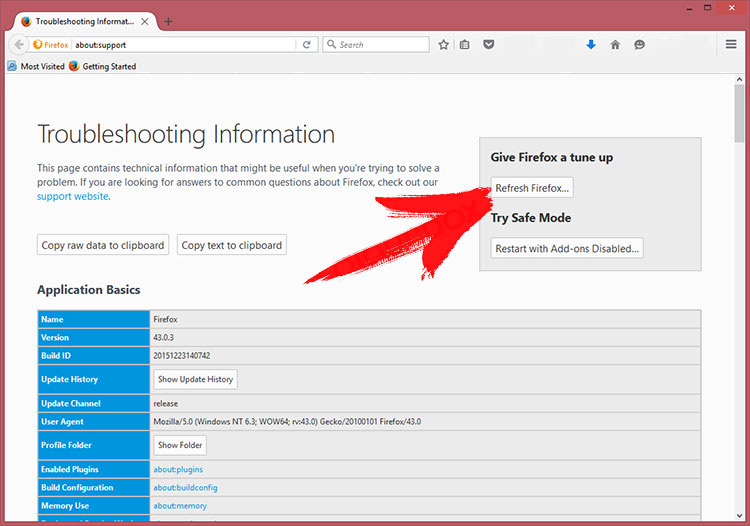
- Нажмите на меню, нажмите кнопку с вопросительным знаком и открыть справку Firefox. Нажмите на Firefox кнопку Обновить и выберите Обновить Firefox для подтверждения.
Прекратить Attention от Chrome
- В «chrome://extensions» введите в поле URL-адрес и нажмите Enter.
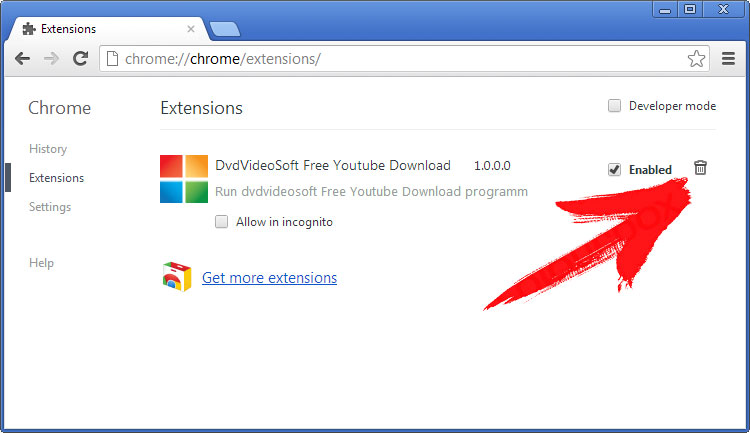
- Прекратить ненадежных браузера расширений
- Перезапустить Google Chrome.
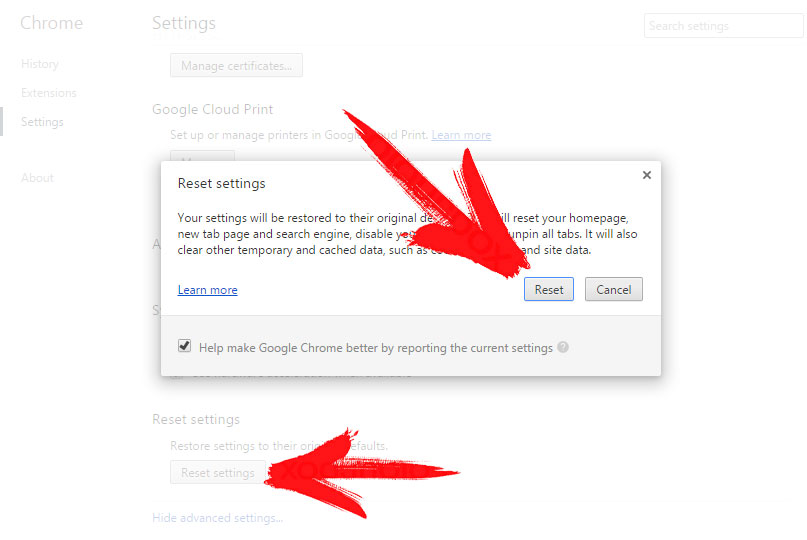
- Откройте меню Chrome, нажмите кнопку Параметры → Показать дополнительные параметры, выберите Сброс настроек браузера и нажмите кнопку Сброс (необязательно).
Скачать утилиту чтобы удалить Attention
Источник: www.2-delete-spyware.com
Attention для чайников и реализация в Keras
О статьях по искусственному интеллекту на русском языке
Не смотря на то что механизм Attention описан в англоязычной литературе, в русскоязычном секторе достойного описание данной технологии я до сих пор не встречал. На нашем языке есть много статей по Искусственному Интеллекту (ИИ). Тем не менее, те статьи, которые удалось найти, раскрывают только самые простые модели ИИ, например, свёрточные сети, генеративные сети. Однако, по передовым новейшим разработками в области ИИ статей в русскоязычном секторе крайне мало.
Отсутствие статей на Русском языке по новейшим разработкам стали проблемой для меня, когда я входил в тему, изучал текущее состояние дел в области ИИ. Я хорошо знаю английский, читаю статьи на английском по тематике ИИ. Однако, когда выходит новая концепция или новый принцип ИИ, его понимание на не родном языке бывает мучительным и долгим.
Зная английский, вникнуть на неродном в сложный всё же предмет стоит значительно больше сил и времени. После прочтения описания задаёшь себе вопрос: на сколько процентов ты понял? Если бы была статья на Русском, то понял бы на 100% после первого прочтения. Так произошло с генеративными сетями, по которым есть великолепный цикл статей: после прочтения всё стало понятно. Но в мире сетей есть множество подходов, которые на описаны только английском и с которыми приходилось разбираться днями.
Я собираюсь периодически писать статьи на родном языке, привнося в нашу языковую область знания. Как известно, лучший способ разобраться в теме это объяснить её кому-нибудь. Так что кому как не мне начать цикл статей по самым современным, сложным, передовым архитектурном ИИ. К концу статьи сам пойму на 100% подход, и будет польза для кого-то, кто прочитает и улучшит своё понимание (кстати я люблю Gesser, но лучше Blanche de bruxelles).
Когда разбираешься в предмете можно выделить 4 уровня понимания:
- ты понял принцип и входы и выходы Алгоритма / Уровня
- ты понял сходы выходы и в общих чертах как оно работает
- ты понял всё вышеперечисленное, а также устройство каждого уровня сети (например, в модели VAE ты понял принцип, а ещё ты понял суть трюка с репараметризацией)
- понял всё включая каждый уровень, так ещё понял, за счёт чего это всё обучается, при чём так, что стал способен подбирать гиперпараметры под свою задачу, а не копипастить готовые решения.
По новым архитектурам переход от уровня 1 к уровню 4 часто сложен: авторы делают упор на то, что им ближе описывая разные важные детали поверхностно (поняли ли они их сами?). Или твой мозг не содержит какие-то конструкции, так что даже прочитав описание оно не расшифровалось и не перешло в навыки. Это бывает, если ты в студенческие годы спал на том самом уроке матана, после ночной вечерники где давали нужный мат. аппарат. И как раз тут нужны статьи на родном языке, раскрывающие нюансы и тонкости каждой операции.
Концепция Attention и применение
Выше приведён сценарий уровней понимания. Чтобы разобрать Attention, начнём с первого уровня. Перед описанием входов и выходов разберём суть: на какие базовые, понятные даже ребёнку, понятия опирается данная концепция. В статье будем использовать английский термин Attention, потому что в таком виде он является также вызовом функции библиотеки Keras (он не реализован в ней прямо, требуется дополнительный модуль, но об этом ниже). Чотбы читать дальше вы должны иметь понимание библиотеки Keras и python, потому что будет приводиться исходный код.
С английского языка Attention переводится как «внимание». Этот термин правильно описывает суть подхода: если вы автомобилист и на фотографии изображён генерал ГИБДД, вы интуитивно придаёте ему важность, вне зависимости от контекста фотографии. Вы скорее всего пристальнее взглянете на генерала. Вы напряжёте глаза, рассмотрите погоны внимательнее: сколько у него там конкретно звёзд.
Если генерал не очень высокий, проигнорируете его. В противном случае учтёте как ключевой фактор при принятии решений. Так работает наш мозг. В Русской культуре мы натренированы поколениями на внимание к высоким чинам, наш мозг автоматически ставит высокий приоритет таким объектам.
Attention представляет собой способ сообщить сети, на что стоит обратить больше внимания, т.е. сообщить вероятность того или ионного исхода в зависимости от состояния нейронов и поступающих на вход данных. Реализованный в Keras слой Attention сам выявляет на основе обучающей выборки факторы, обращение внимания на которые снижает ошибку сети. Выявление важных факторов осуществляется через метод обратного распространения ошибки, подобно тому как это делается для свёрточной сетей.
При обучении, Attention демонстрирует свою вероятностную природу. Сам по себе механизм формирует матрицу весов важности. Если бы мы не обучали Attention, мы могли бы задать важность, например, эмпирически (генерал важнее прапорщика). Но когда мы обучаем сеть на данных, важность становится функцией вероятности того или иного исхода в зависимости от поступивших на вход сети данных.
Например, если бы проживая в Царской России мы встретили генерала, то вероятность получить шпицрутенов была бы высока. Удостоверившийся в этом можно было бы через несколько личных встреч, собрав статистику. После этого наш мозг выставит соответствующий вес факту встречи данного субъекта и поставит маркеры на погоны и лампасы. Надо отметить, что выставленный маркер не является вероятностью: сейчас встреча генерала повлечёт для вас совершенно иные последствия чем тогда, кроме того вес может быть больше единицы. Но, вес можно привести к вероятности, нормировав его.
Вероятностная природа механизма Attention при обучении проявляется в задачах машинного перевода. Например, сообщим сети, что при переводе с русского на английский слово Любовь переводится в 90% случаев как Love, в 9% случаях как Sex, в 1% случаях как иное. Сеть сразу отметёт множество вариантов, показав лучшее качество обучения. При переводе мы сообщаем сети: «при переводе слова любовь обрати особое внимание на английское слово Love, также посмотри может ли это всё же быть Sex”.
Подход Attention применяться для работы с текстом, а также звуком и временными рядами. Для обработки текста широко используются рекуррентные нейронные сети (RNN, LSTM, GRU). Attention может либо дополнять их, либо заменять их, переводя сеть к более простым и быстрым архитектурам.
Одно из самых известных применений Attention это применение его для того, чтобы отказаться от рекуррентной сети и перейти к полносвязной модели. Рекуррентные сети обладают серией недостатков: невозможность осуществлять обучение на GPU, быстро наступающее переобучение. С помощью механизма Attention мы можем выстроить сеть способную к изучению последовательностей на базе полносвязной сети, обучить её на GPU, использовать droput.
Attention широко применяется для улучшения работы рекуррентных сетей, например, в области перевода с языка на язык. При использовании подхода кодирование / декодирование, которое достаточно часто применяется в современном ИИ (например, вариационные автокодировщики). При добавлении между кодировщиком и декодирокщиком слоя Attention результат работы сети заметно улучшается.
В этой статье я не привожу конкретные архитектуры сетей с использованием Attention, этому будут посвящены отдельные работы. Attention применяется в работе со звуком, с временными последовательностями. Перечисление всех возможностей применения attention достойно отдельной статьи.
Реализация Attention в Keras из коробки
Когда разбираешься каком-от подходе, усвоить базовый принцип очень полезно. Но, часто полное понимание приходит только посмотрев на техническую реализацию. Видишь потоки данных, составляющие функцию операции, становится ясно что именно вычисляется. Но сначала его нужно запустить и написать «Attention hello word».
В настоящее время механизм Attention не реализован в самом Keras. Но уже есть сторонние реализации, например attenytion-keras который можно установить с github. Тогда ваш код станет предельно простым:
from attention_keras.layers.attention import AttentionLayer attn_layer = AttentionLayer(name=’attention_layer’) attn_out, attn_states = attn_layer([encoder_outputs, decoder_outputs])
Данная реализация поддерживает функцию визуализации весов Attention. Обучив Attention можно получить матрицу, сигнализирующую, что по мнению сети особенно важно примерно такого вида (картинка с github со страницы библиотеки attenytion-keras).
В принципе вам больше ничего не нужно: включите этот код вашу сеть как один из уровней и наслаждайтесь обучение вашей сети. Любая сеть, любой алгоритм проектируется на первых этапах на концептуальном уровне (как и база данных кстати), после чего реализация до воплощения уточняется в логическом и физическом представлении. Для нейросетей пока данного метода проектирования не разработано (о да, это будет тема моей следующей статьи). Вы же не разбираетесь, как внутри работают слои свёртки? Описан принцип, вы их используете.
Реализация Attention в Keras на низком уровне
Чтобы окончательно разобраться в теме, ниже подробно разберём реализацию Attention под капотом. Концепция хороша, но как именно это работает и почему результат получается именно таким как заявлено?
Простейшая реализация механизма Attention в Keras заминает всего 3 строки:
inputs = Input(shape=(input_dims,)) attention_probs = Dense(input_dims, activation=’softmax’, name=’attention_probs’)(inputs) attention_mul = merge([inputs, attention_probs], output_shape=32, name=’attention_mul’, mode=’mul’
В данном случае в первой строке декларируется слой Input, далее идёт полносвязный слой с функцией активации softmax с количеством нейронов равным количеству элементов в первом слое. Третий слой умножает результат полносвязного слоя на входные данные поэлементно.
Ниже приведён целый класс Attention, реализующий немного более сложный механизм self-attention, который может быть использован как полноценный уровень в модели, класс наследует класс Keras layer.
# Attention class Attention(Layer): def __init__(self, step_dim, W_regularizer=None, b_regularizer=None, W_constraint=None, b_constraint=None, bias=True, **kwargs): self.supports_masking = True self.init = initializers.get(‘glorot_uniform’) self.W_regularizer = regularizers.get(W_regularizer) self.b_regularizer = regularizers.get(b_regularizer) self.W_constraint = constraints.get(W_constraint) self.b_constraint = constraints.get(b_constraint) self.bias = bias self.step_dim = step_dim self.features_dim = 0 super(Attention, self).__init__(**kwargs) def build(self, input_shape): assert len(input_shape) == 3 self.W = self.add_weight((input_shape[-1],), initializer=self.init, name='<>_W’.format(self.name), regularizer=self.W_regularizer, constraint=self.W_constraint) self.features_dim = input_shape[-1] if self.bias: self.b = self.add_weight((input_shape[1],), initializer=’zero’, name='<>_b’.format(self.name), regularizer=self.b_regularizer, constraint=self.b_constraint) else: self.b = None self.built = True def compute_mask(self, input, input_mask=None): return None def call(self, x, mask=None): features_dim = self.features_dim step_dim = self.step_dim eij = K.reshape(K.dot(K.reshape(x, (-1, features_dim)), K.reshape(self.W, (features_dim, 1))), (-1, step_dim)) if self.bias: eij += self.b eij = K.tanh(eij) a = K.exp(eij) if mask is not None: a *= K.cast(mask, K.floatx()) a /= K.cast(K.sum(a, axis=1, keepdims=True) + K.epsilon(), K.floatx()) a = K.expand_dims(a) weighted_input = x * a return K.sum(weighted_input, axis=1) def compute_output_shape(self, input_shape): return input_shape[0], self.features_dim
Здесь мы видим примерно то же самое что было реализовано выше через полносвязный слой Keras, только выполненное через более глубокую логику на более низком уровне.
В функции создаётся параметрический уровень (self.W) который потом скалярно умножается (K.dot) на входной вектор. Логика зашитая в этом варианте немного более cложна: к входному вектору, помноженному на веса self.W, применяется сдвиг (если раскрыт параметр bias), гиперболический тангенс, экспонирование, маска (если она задана), нормирование, после чего входной вектор снова взвешивается по полученному результату. У меня нет описания логики заложенной в этом примере, воспроизвожу операции по чтению кода. Кстати, напишите пожалуйста в комментариях, если вы узнали в этой логике какую-то математическую высокоуровневую функцию.
У класса есть параметр «bias» т.е. предвзятость. Если параметр активирован, то после применения Dense слоя итоговый вектор будет сложен с вектором параметров слоя «self.b» что даст возможность не только определять «веса» для нашей функции внимания, но также смещать уровень внимания на число. Пример из жизни: мы боимся привидений, но ни разу не встречали их. Таким образом мы вносим поправку на страх -100 баллов. То есть только если страх зашкалит за 100 баллов, мы примем решения о защите от привидений, вызове агентства ловцов привидений, покупке отпугивающих устройства и т.д.
Заключение
У механизма Attention есть вариации. Самый простой вариант Attention, реализованный в классе, приведённом выше, называется Self-Attention. Self-attention это механизм предназначенный для обработки последовательных данных с учётом контекста каждой метки времени. Он чаще всего применяется для работы с текстовой информацией.
Реализацию self-attention можно взять из коробки, импортировав библиотеку keras-self-attention. Есть и другие вариации Attention. Изучая англоязычные материалы удалось насчитать более 5 вариаций.
При написании даже этой относительно короткой статьи я изучил более 10 англоязычных статей. Безусловно мне не удалось загрузить все данные из всех этих статей в 5 страниц, я сделал лишь выжимку, с целью создать «руководство для чайников». Чтобы разобрать все нюансы механизма Attention потребуется книжечка страниц на 150-200. Очень надеюсь, мне удалось раскрыть базовую сущность этого механизма чтобы те, кто только начинает разбираться в машинному обучении, поняли как это всё работает.
Источники
- Attention mechanism in Neural Networks with Keras
- Attention in Deep Networks with Keras
- Attention-based Sequence-to-Sequence in Keras
- Text Classification using Attention Mechanism in Keras
- Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-Sequence Prediction
- How to implement the Attention Layer in Keras?
- Attention? Attention!
- Neural Machine Translation with Attention
Источник: temofeev.ru