
Introduction to Apache Spark
Apache Spark is an open-source, distributed processing system used for big data workloads. It utilizes in-memory caching, and optimized query execution for fast analytic queries against data of any size. It provides development APIs in Java, Scala, Python and R, and supports code reuse across multiple workloads—batch processing, interactive queries, real-time analytics, machine learning, and graph processing. You’ll find it used by organizations from any industry, including at FINRA, Yelp, Zillow, DataXu, Urban Institute, and CrowdStrike. Apache Spark has become one of the most popular big data distributed processing framework with 365,000 meetup members in 2017.
What is the history of Apache Spark?
Apache Spark started in 2009 as a research project at UC Berkley’s AMPLab, a collaboration involving students, researchers, and faculty, focused on data-intensive application domains. The goal of Spark was to create a new framework, optimized for fast iterative processing like machine learning, and interactive data analysis, while retaining the scalability, and fault tolerance of Hadoop MapReduce. The first paper entitled, “Spark: Cluster Computing with Working Sets” was published in June 2010, and Spark was open sourced under a BSD license. In June, 2013, Spark entered incubation status at the Apache Software Foundation (ASF), and established as an Apache Top-Level Project in February, 2014. Spark can run standalone, on Apache Mesos, or most frequently on Apache Hadoop.
Что такое Apache Spark
Today, Spark has become one of the most active projects in the Hadoop ecosystem, with many organizations adopting Spark alongside Hadoop to process big data. In 2017, Spark had 365,000 meetup members, which represents a 5x growth over two years. It has received contribution by more than 1,000 developers from over 200 organizations since 2009.
How does Apache Spark work?
Hadoop MapReduce is a programming model for processing big data sets with a parallel, distributed algorithm. Developers can write massively parallelized operators, without having to worry about work distribution, and fault tolerance. However, a challenge to MapReduce is the sequential multi-step process it takes to run a job. With each step, MapReduce reads data from the cluster, performs operations, and writes the results back to HDFS. Because each step requires a disk read, and write, MapReduce jobs are slower due to the latency of disk I/O.
Spark was created to address the limitations to MapReduce, by doing processing in-memory, reducing the number of steps in a job, and by reusing data across multiple parallel operations. With Spark, only one-step is needed where data is read into memory, operations performed, and the results written back—resulting in a much faster execution. Spark also reuses data by using an in-memory cache to greatly speed up machine learning algorithms that repeatedly call a function on the same dataset. Data re-use is accomplished through the creation of DataFrames, an abstraction over Resilient Distributed Dataset (RDD), which is a collection of objects that is cached in memory, and reused in multiple Spark operations. This dramatically lowers the latency making Spark multiple times faster than MapReduce, especially when doing machine learning, and interactive analytics.
Apache Spark vs. Apache Hadoop
Outside of the differences in the design of Spark and Hadoop MapReduce, many organizations have found these big data frameworks to be complimentary, using them together to solve a broader business challenge.
Hadoop is an open source framework that has the Hadoop Distributed File System (HDFS) as storage, YARN as a way of managing computing resources used by different applications, and an implementation of the MapReduce programming model as an execution engine. In a typical Hadoop implementation, different execution engines are also deployed such as Spark, Tez, and Presto.
Spark is an open source framework focused on interactive query, machine learning, and real-time workloads. It does not have its own storage system, but runs analytics on other storage systems like HDFS, or other popular stores like Amazon Redshift, Amazon S3, Couchbase, Cassandra, and others. Spark on Hadoop leverages YARN to share a common cluster and dataset as other Hadoop engines, ensuring consistent levels of service, and response.
What are the benefits of Apache Spark?
There are many benefits of Apache Spark to make it one of the most active projects in the Hadoop ecosystem. These include:
Fast
Through in-memory caching, and optimized query execution, Spark can run fast analytic queries against data of any size.
Developer friendly
Apache Spark natively supports Java, Scala, R, and Python, giving you a variety of languages for building your applications. These APIs make it easy for your developers, because they hide the complexity of distributed processing behind simple, high-level operators that dramatically lowers the amount of code required.
Multiple workloads
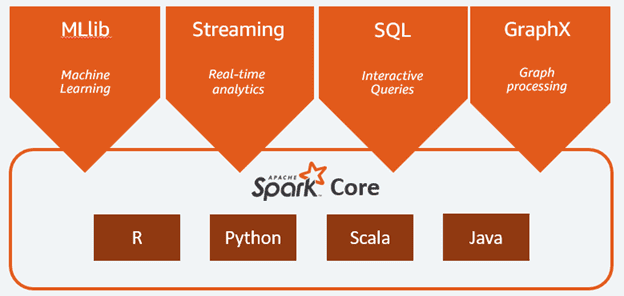
Apache Spark comes with the ability to run multiple workloads, including interactive queries, real-time analytics, machine learning, and graph processing. One application can combine multiple workloads seamlessly.
Apache Spark Workloads
The Spark framework includes:
- Spark Core as the foundation for the platform
- Spark SQL for interactive queries
- Spark Streaming for real-time analytics
- Spark MLlib for machine learning
- Spark GraphX for graph processing

Spark Core
Spark Core is the foundation of the platform. It is responsible for memory management, fault recovery, scheduling, distributing Spark distributions with the scale, simplicity, and cost effectiveness of the cloud. It allows you to launch Spark clusters in minutes without needing to do node provisioning, cluster setup, Spark configuration, or cluster tuning. EMR enables you to provision one, hundreds, or thousands of compute instances in minutes. You can use Auto Scaling to have EMR automatically scale up your Spark clusters to process data of any size, and back down when your job is complete to avoid paying for unused capacity.
You can lower your bill by committing to a set term, and saving up to 75% using Amazon EC2 Reserved Instances, or running your clusters on spare AWS compute capacity and saving up to 90% using EC2 Spot. Learn more.
Источник: aws.amazon.com
Обзор архитектуры Spark
Чёткая многоуровневая архитектура Spark со слабосвязанными компонентами основывается на двух главных абстракциях:
- Устойчивые распределённые наборы данных (RDD – Resilient Distributed Datasets)
- Направленный ациклический граф (DAG – Directed Acyclic Graph)
Устойчивые распределённые наборы данных
RDD – строительные блоки Spark: всё состоит из них. Даже высокоуровневые Spark API (DataFrames, Datasets) состоят из RDD под капотом. Что значит быть устойчивым распределённым набором данных?
- Resilient – Устойчивый: поскольку Spark работает на кластере компьютеров, потеря данных из-за аппаратного сбоя представляет собой серьёзную проблему, поэтому RDD отказоустойчивые и восстанавливаются в случае сбоя.
- Distributed – Распределённый: один RDD хранится на нескольких узлах кластера, которые не принадлежат одному источнику (и одной точке отказа). Таким образом, кластер оперирует RDD параллельно.
- Dataset – Набор данных: коллекция значений – вы наверняка уже знали это.
Данные, с которыми мы работаем в Spark, хранятся в той или иной форме в RDD, поэтому понимать их – необходимость.
Spark предлагает API «высшего уровня», разработанные на основе RDD для абстрагирования сложности: DataFrame и Dataset. Если сосредоточиться на циклах «чтение – вычисление – вывод» (REPL), Spark-Submit и Spark-Shell в Scala и Python ориентируются на экспертов по аналитическим данным, которым часто требуется повторный анализ набора данных. Без понимания RDD по-прежнему не обойтись, так как это базовая структура всех данных в Spark.
Разговорный эквивалент RDD: «Распределённая структура данных». JavaRDD – это, по сути, List , рассредоточенный по узлам в нашем кластере, причём каждый узел получает разные порции списка. Фреймворк Spark побуждает мыслить в распределённом контексте, постоянно.
RDD работают путём разделения данных на несколько разделов (Partition), которые хранятся на каждом узле-исполнителе. Каждый узел выполняет работу только на собственных разделах. В этом и заключается мощь Spark: если исполнитель выходит из строя, или не удаётся выполнить задачу, Spark восстанавливает только необходимые разделы из источника и повторно отправляет задачу для завершения.
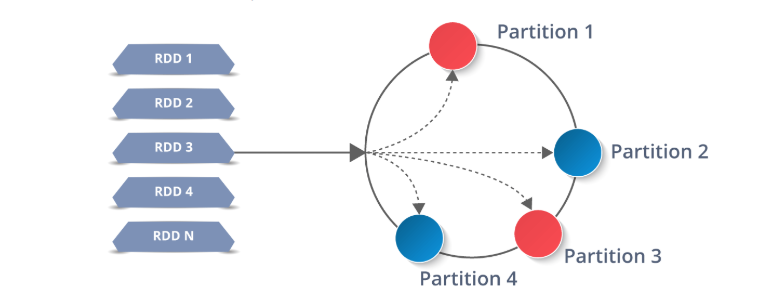
Операции с RDD
RDD Immutable , это означает, что после создания эти наборы никак не изменяются, а только трансформируются ( transformed ). Идея трансформации RDD лежит в основе Spark, и задания Spark рассматриваются как комбинация этих шагов:
- Загрузка данных в RDD
- Трансформация RDD
- Выполнение действия над RDD
Spark определяет набор API для работы с RDD, которые разбиты на две большие группы: Трансформации и Действия .
Трансформации создают новый RDD из существующего.
Действия возвращают значение или значения программе-драйверу после выполнения вычисления над RDD.
Например, map-функция weatherData.map() – это трансформация, которая передаёт каждый элемент RDD в функцию.
Reduce – это действие RDD, которое объединяет все элементы RDD с использованием некоторой функции и возвращает конечный результат в программу-драйвер.
Ленивые вычисления
«Я выбираю ленивого человека для выполнения трудной работы. Потому что ленивый человек найдёт простой способ решения задачи.» – Билл Гейтс
Трансформации в Spark «ленивые». Это означает, что когда сообщаем Spark о создании RDD с помощью трансформаций существующего RDD, он не будет генерировать этот набор данных, пока не выполнится действие над ним или его дочерним элементом. Затем Spark выполнит трансформацию и действие, которое её запустило. Поэтому Spark работает намного эффективнее.
Ещё раз рассмотрим объявления функций из нашего предыдущего примера Spark, чтобы определить, какие функции – действия, а какие – трансформации:
16: JavaRDD weatherData = sc.textFile(inputPath);
Строка 16 – не действие и не трансформация; это функция sc , нашего JavaSparkContext.
17: JavaPairRDD tempsByCountry = weatherData.mapToPair(new Func.
Строка 17 – трансформация RDD WeatherData , в которой преобразовываем каждую строку WeatherData в пару (Город, Температура)
26: JavaPairRDD maxTempByCountry = tempsByCountry.reduce(new Func.
Строка 26 – также трансформация, потому что перебираем пары ключ-значение. Это трансформация tempsByCountry , в которой происходит свёртка данных каждого города до его наивысшей зарегистрированной температуры.
31: maxTempByCountry.saveAsHadoopFile(destPath, String.class, Integer.class, TextOutputFormat.class);
Наконец, в строке 31 запускаем действие Spark: сохраняем RDD в файловой системе. Поскольку у Spark ленивая модель выполнения, только после этой строки Spark генерирует weatherData , tempsByCountry и maxTempsByCountry , прежде чем окончательно сохранить результат.
Направленный ациклический граф
Каждый раз, когда выполняется действие над RDD, Spark создает DAG, конечный граф без направленных циклов (в противном случае наше задание будет выполняться вечно). Помните, что граф – набор связанных вершин и рёбер, и этот граф ничем не отличается. Каждая вершина в DAG – функция Spark, некоторая операция, которая выполняется над RDD ( map , mapToPair , reduByKey и т. д.).
В MapReduce DAG состоит из двух вершин: Map → Reduce .
В приведённом выше примере с MaxTemperatureByCountry граф посложнее:
parallelize → map → mapToPair → reduce → saveAsHadoopFile
С помощью DAG Spark оптимизирует план выполнения и минимизирует перемешивание. Рассмотрение DAG выходит за рамки этого обзора Spark.
Циклы выполнения
Используя наш новый словарь, ещё раз рассмотрим определение проблемы с MapReduce, данное в первой части и приведенное ниже:
«MapReduce справляется с пакетной обработкой данных. Однако отстаёт, когда дело доходит до повторного анализа и небольших циклов обратной связи. Единственный способ повторно использовать данные между вычислениями – записать их во внешнюю систему хранения (например, HDFS).»
«Повторно использовать данные между вычислениями»? Звучит так, будто над RDD совершается несколько действий! Предположим, хотим выполнить два вычисления над фалом «data.txt»:
- Общая длина всех строк в файле
- Длина самой длинной строки в файле
В MapReduce каждая задача требует отдельного задания или мудрёной реализации MulitpleOutputFormat . Spark превращает это в пустяк с четырьма лёгкими шагами:
- Загружаем содержимое data.txt в RDD
JavaRDD lines = sc.textFile(«data.txt»);
2. Применяем функцию вычисления длины к каждой строке из lines с помощью map (лямбда-функции используются для краткости)
JavaRDD lineLengths = lines.map(s -> s.length());
3. Для определения общей длины выполним reduce для lineLengths , чтобы найти сумму длин строк, в нашем случае сумму всех элементов в RDD.
int totalLength = lineLengths.reduce((a, b) -> a + b);
4. Чтобы вычислить наибольшую длину, применяем reduce к lineLengths
int maxLength = lineLengths.reduce((a, b) -> Math.max(a,b));
Обратите внимание, что шаги 3 и 4 – действия RDD, поэтому они возвращают результат программе-драйверу, в данном случае Java int . Также помните, что Spark ленив и отказывается выполнять работу, пока не увидит действие. В этом случае он не начнёт ничего делать до шага 3.
Заключение
К этому моменту мы представили проблему с данными и её решение: фреймворк Apache Spark. Теперь рассмотрели архитектуру и workflow Spark, его главную внутреннюю абстракцию (RDD) и модель выполнения.
Источник: proglib.io
Spark
Apache Spark – это Big Data фреймворк с открытым исходным кодом для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных, входящий в экосистему проектов Hadoop [1].
История появления Спарк и сравнение с Apache Hadoop
Основным автором Apache Spark считается Матей Захария (Matei Zaharia), румынско-канадский учёный в области информатики. Он начал работу над проектом в 2009 году, будучи аспирантом Университета Калифорнии в Беркли. В 2010 году проект опубликован под лицензией BSD, в 2013 году передан фонду Apache Software Foundation и переведён на лицензию Apache 2.0, а в 2014 году принят в число проектов верхнего уровня Apache. Изначально Спарк написан на Scala, затем была добавлена существенная часть кода на Java, что позволяет разрабатывать распределенные приложения непосредственно на этом языке программирования [1].
Классический MapReduce, Apache компонент Hadoop для обработки данных, проводит вычисления в два этапа:
- Map, когда главный узел кластера (master) распределяет задачи по рабочим узлам (node)$
- Reduce, когда данные сворачиваются и передаются обратно на главный узел, формируя окончательный результат вычислений.
Пока все процессы этапа Map не закончатся, процессы Reduce не начнутся. При этом все операции проходят по циклу чтение-запись с жесткого диска. Это обусловливает задержки в обработке информации. Таким образом, технология MapReduce хорошо подходит для задач распределенных вычислений в пакетном режиме, но из-за задержек (latency) не может использоваться для потоковой обработки в режиме реального времени [2]. Для решения этой проблемы был создан Apache Spark и другие Big Data фреймворки распределенной потоковой обработки (Storm, Samza, Flink).
В отличие от классического обработчика ядра Apache Hadoop c двухуровневой концепцией MapReduce на базе дискового хранилища, Spark использует специализированные примитивы для рекуррентной обработки в оперативной памяти. Благодаря этому многие вычислительные задачи реализуются в Спарк значительно быстрее. Например, возможность многократного доступа к загруженным в память пользовательским данным позволяет эффективно работать с алгоритмами машинного обучения (Machine Learning) [1].

Как устроен Apache Spark: архитектура и принцип работы
Спарк состоит из следующих компонентов:
- Ядро (Core);
- SQL – инструмент для аналитической обработки данных с помощью SQL-запросов;
- Streaming – надстройка для обработки потоковых данных, о которой подробно мы рассказывали здесь и здесь;
- MLlib – набор библиотек машинного обучения;
- GraphX – модуль распределённой обработки графов.
Spark может работать как в среде кластера Hadoop под управлением YARN, так и без компонентов ядра хадуп, например, на базе системы управления кластером Mesos. Спарк поддерживает несколько популярных распределённых систем хранения данных (HDFS, OpenStack Swift, Cassandra, Amazon S3) и языков программирования (Java, Scala, Python, R), предоставляя для них API-интерфейсы.
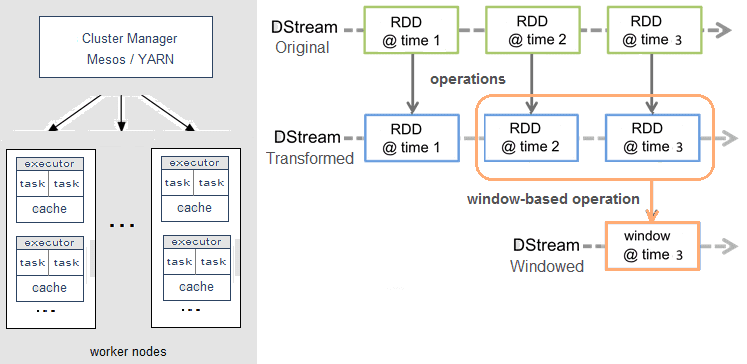
Справедливости ради стоит отметить, что Spark Streaming, в отличие от, например, Apache Storm, Flink или Samza, не обрабатывает потоки Big Data целиком. Вместо этого реализуется микропакетный подход (micro-batch), когда поток данных разбивается на небольшие пакеты временных интервалов. Абстракция Spark для потока называется DStream (discretized stream, дискретизированный поток) и представляет собой микро-пакет, содержащий несколько отказоустойчивых распределенных датасетов, RDD (resilient distributed dataset) [3].
Именно RDD является основным вычислительным примитивом Спарк, над которым можно делать параллельные вычисления и преобразования с помощью встроенных и произвольных функций, в том числе с помощью временных окон (window-based operations) [3]. Подробнее про временные окна мы рассказывали здесь на примере Apache Kafka Streams.
Где и как используется Apache Spark
Благодаря наличию разнопрофильных инструментов для аналитической обработки данных «на лету» (SQL, Streaming, MLLib, GraphX), Спарк активно используется в системах интернета вещей (Internet of Things, IoT) на стороне IoT-платформ, а также в различных бизнес-приложениях, в т.ч. на базе методов Machine Learning. Например, Спарк применяется для прогнозирования оттока клиентов (Churn Predict) и оценки финансовых рисков [4]. Однако, если временная задержка обработки данных (latency) – это критичный фактор, Apache Spark не подойдет и стоит рассмотреть альтернативу в виде клиентской библиотеки Kafka Streams или фреймворков Storm, Flink, Samza.
По набору компонентов и функциональным возможностям Spark можно сравнить с другим Big Data инструментом распределенной потоковой обработки – Apache Flink. Этому детальному сравнению в части потоковых вычислений мы посвятили отдельную статью. А о проблемах Спарк читайте здесь.
Источники
- https://ru.wikipedia.org/wiki/Apache_Spark
- https://dis-group.ru/company-news/articles/6-faktov-ob-apache-spark-kotorye-nuzhno-znat-kazhdomu/
- http://datareview.info/article/obrabotka-potokovyx-dannyx-storm-spark-i-samza/
- https://www.cloudera.com/developers/how-tos/apache-spark-how-tos.html
Источник: www.bigdataschool.ru
Apache Spark: из open source в индустрию
Алёна Лазарева, редактор-фрилансер, специально для блога Нетологии написала обзорную статью об одном из популярных инструментов специалиста по Big Data — фреймворке Apache Spark.
Люди часто не догадываются о том, как Big Data влияет на их жизнь. Но каждый человек — источник больших данных. Специалисты по Big Data собирают и анализируют цифровые следы: лайки, комментарии, просмотры видео на Youtube, данные GPS с наших смартфонов, финансовые транзакции, поведение на сайтах и многое другое. Их не интересует каждый человек, их интересуют закономерности.
Понимание этих закономерностей помогает оптимизировать рекламные кампании, предсказать потребность клиента в продукте или услуге, оценить настроение пользователей.
Согласно опросам и исследованиям, Big Data чаще всего внедряют в областях маркетинга и ИТ, и только после этого идут исследования, прямые продажи, логистика, финансы и так далее.
.png)
Для работы с большими данными были разработаны специальные инструменты. Наиболее популярный на сегодняшний день — Apache Spark.
Что такое Apache Spark
Apache Spark — это фреймворк с открытым исходным кодом для параллельной обработки и анализа слабоструктурированных данных в оперативной памяти.
Главные преимущества Spark — производительность, удобный программный интерфейс с неявной параллелизацией и отказоустойчивостью. Spark поддерживает четыре языка: Scala, Java, Python и R.
Фреймворк состоит из пяти компонентов: ядра и четырех библиотек, каждая из которых решает определенную задачу.
.png)
Spark Core — основа фреймворка. Оно обеспечивает распределенную диспетчеризацию, планирование и базовые функции ввода-вывода.
Spark SQL — одна из четырех библиотек фреймворка для структурированной обработки данных. Она использует структуру данных, называемую DataFrames и может выступать в роли распределенного механизма запросов SQL. Это позволяет выполнять запросы Hadoop Hive до 100 раз быстрее.
Spark Streaming — простой в использовании инструмент для обработки потоковых данных. Несмотря на название, Spark Streaming не обрабатывает данные в реальном времени, а делает это в режиме micro-batch. Создатели Spark утверждают, что производительность от этого страдает несильно, поскольку минимальное время обработки каждого micro-batch 0,5 секунды.
Библиотека позволяет использовать код приложений batch-анализа для потоковой аналитики, что облегчает реализацию λ-архитектуры.
Spark Streaming легко интегрируется с широким спектром популярных источников данных: HDFS, Flume, Kafka, ZeroMQ, Kinesis и Twitter.
MLlib — это распределенная система машинного обучения с высокой скоростью. Она в 9 быстрее своего конкурента — библиотеки Apache Mahout при тестировании бенчмарками на алгоритме чередующихся наименьших квадратов (ALS).
MLlib включает в себя популярные алгоритмы:
- классификация,
- регрессия,
- деревья принятия решений,
- рекомендация,
- кластеризация,
- тематическое моделирование.
GraphX — это библиотека для масштабируемой обработки графовых данных. GraphX не подходит для графов, которые изменяются транзакционным методом: например, базы данных.
- в среде кластеров Hadoop на YARN,
- под управлением Mesos,
- в облаке на AWS или других облачных сервисах,
- полностью автономно.
Он же поддерживает несколько распределенных систем хранения:
- HDFS,
- OpenStack Swift,
- NoSQL-СУБД,
- Cassandra,
- Amazon S3,
- Kudu,
- MapR-FS.
Как появился
Первым фреймворком для работы с Big Data был Apache Hadoop, реализованный на базе технологии MapReduce.
В 2009 году группа аспирантов из Калифорнийского университета Беркли разработала систему управления кластером с открытым исходным кодом — Mesos. Чтобы показать все возможности своего продукта и то, как легко управлять фреймворком на базе Mesos, всё та же группа аспирантов начала работу над Spark.
По задумке создателей, Spark должен был стать не просто альтернативой Hadoop, но и превзойти его.
Основное различие двух фреймворков — способ обращения к данным. Hadoop сохраняет данные на жесткий диск на каждом шаге алгоритма MapReduce, а Spark производит все операции в оперативной памяти. Благодаря этому Spark выигрывает в производительности до 100 раз и позволяет обрабатывать данные в потоке.
В 2010 году проект был опубликован под лицензией BSD, а в 2013 году перешел под лицензию Apache Software Foundation, который спонсирует и разрабатывает перспективные проекты. Mesos также привлек внимание Apache и перешел под его лицензию, но не стал таким же популярным, как Spark.
Как используется
По результатам опроса, который фонд Apache провел в 2016 году, более 1000 компаний используют Spark. Его применяют не только в маркетинге. Вот часть задач, которые компании решают при помощи Spark.
- Страховые компании оптимизируют процесс возмещения претензий.
- Поисковики выявляют фейковые аккаунты в социальных сетях и улучшают таргетинг.
- Банки прогнозируют востребованность определенных банковских услуг у своих клиентов.
- Службы такси анализируют время и геолокацию, чтобы спрогнозировать спрос и цены.
- Twitter анализирует большие объемы твитов, чтобы определить настроение пользователей и отношение к продукту или компании.
- Авиакомпании строят модели для прогнозирования задержек рейсов.
- Ученые анализируют погодные катаклизмы и предсказывают их появление в будущем.
Альтернативы
С развитием потребности к сбору, анализу и обработке больших данных появляются новые фреймворки. Некоторые большие корпорации разрабатывают собственный продукт с учетом внутренних задач и потребностей. Например, так появился Beam от Google и Kinesis от Amazon. Если говорить о фреймворках, популярных среди широкого круга пользователей, то кроме уже упомянутого Hadoop можно назвать Apache Flink, Apache Storm и Apache Samza.
Мы сравнили четыре фреймворка под лицензией Apache по ключевым показателям:
.png)
Каждый фреймворк имеет свои слабые и сильные стороны. Пока ни один из них не является универсальным и не может заменить остальные. Поэтому при работе с большими данными компании выбирают тот фреймворк, который лучше всего подходит для решения конкретной задачи. Некоторые компании одновременно используют несколько фреймворков, например, TripAdvisor и Groupon.
Подводя итог
Apache Spark — самый популярный и быстроразвивающийся фреймворк для работы с Big Data. Хорошие технические параметры и четыре дополнительных библиотеки позволяют использовать Spark для решения широкого круга задач.
Из неочевидных плюсов фреймворка — многочисленное Spark-комьюнити и большое количество информации о нем в открытом доступе. Из очевидных минусов — задержка обработки данных больше, чем у фреймворков с потоковой моделью.
Мнение автора и редакции может не совпадать. Хотите написать колонку для «Нетологии»? Читайте наши условия публикации.
Средняя оценка 0 / 5. Всего проголосовало 0
Источник: netology.ru