
Что такое Apache Kafka и как он работает
Apache Kafka — это распределенное хранилище данных, которое оптимально подходит для приема и обработки потоковых сообщений в режиме реального времени. Платформа может последовательно и поэтапно справляться с информацией, поступающей из тысяч источников. В статье расскажем, как это работает и кому может быть полезным.
Что такое Apache Kafka
Данная платформа применяется для создания конвейеров потоковой передачи данных в реальном времени и приложений, которые адаптируются к потокам данных. В ней объединены обмен сообщениями, хранение и потоковая обработка информации. Благодаря этому можно хранить и анализировать как старые данные, так и те, что поступают в реальном времени.
Kafka даёт пользователям три основные функции:
- Публиковать и подписываться на потоки записей
- Эффективно хранить потоки записей в порядке их создания
- Обрабатывать потоки записей в режиме реального времени
Как работает Kafka?
В Kafka сочетаются две модели обмена сообщениями: очередь и публикация-подписка. Таким образом потребителям получают преимущества обеих. Благодаря очереди обработка данных распределяется по множеству потребителей, а это ведёт к высокой масштабируемости. Но в отличие от традиционных очередей (не многоабонентским), модель «публикация-подписка» позволяет работать с множеством подписчиков.
Что такое Apache Kafka за 200 секунд
Метод «публикация-подписка» предусматривает несколько подписчиков, но так как сообщение отправляется каждому подписчику, он не подходит для организации работы между разными рабочими процессами. В Kafka применяется модель поделенного на секции журнала, благодаря чему можно объединить оба решения.
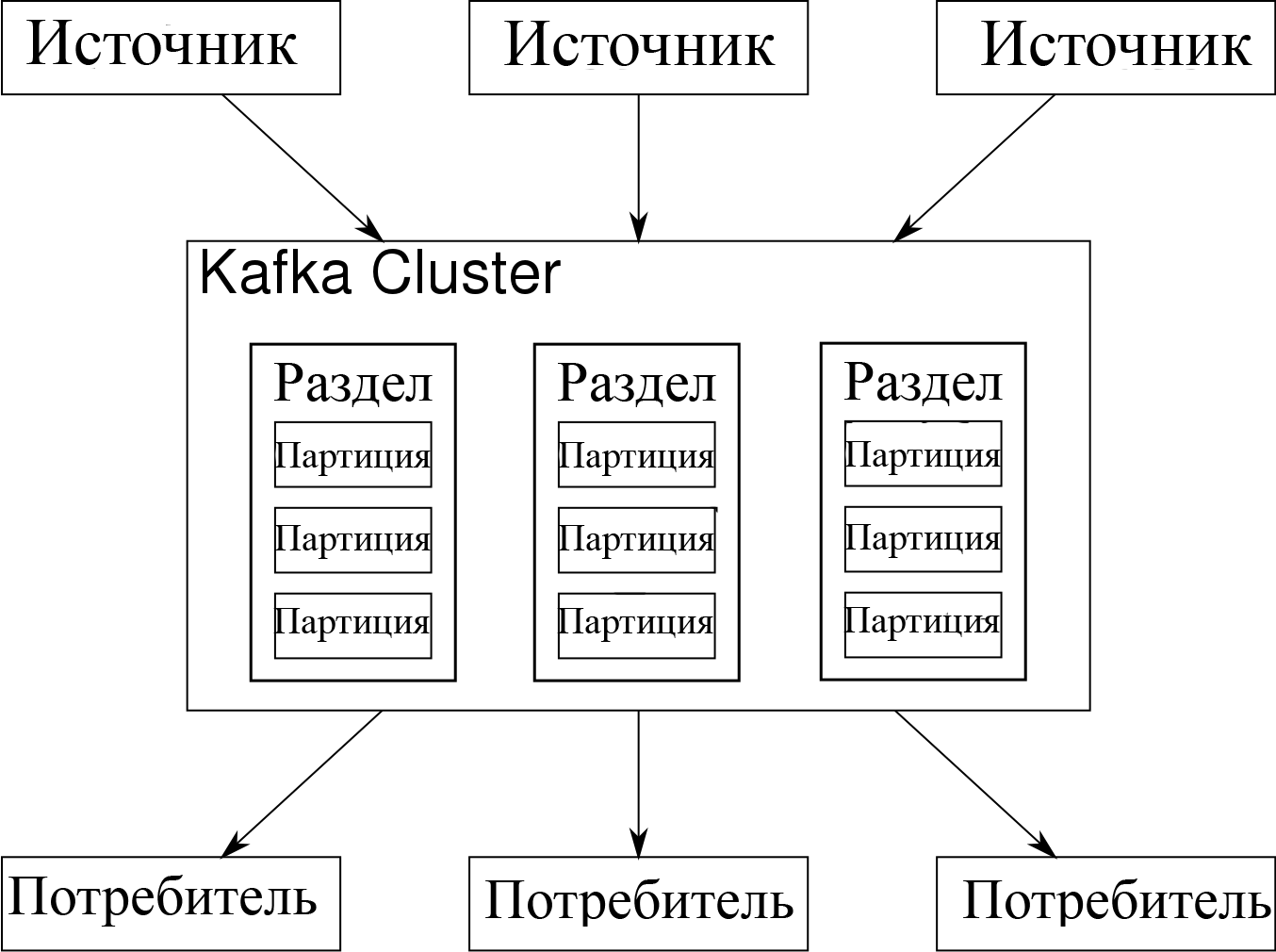
Журнал – это упорядоченная последовательность записей. Сам журнал разбит на сегменты или разделы, которые соответствуют разным подписчикам. То есть на одну и ту же тему может быть несколько подписчиков, и каждому назначается раздел, что даёт возможности для масштабируемости.
Бесплатный тестовый доступ к облаку на 30 днейПолучить
Преимущества Apache Kafka
- Масштабируемость. Модель разделенного журнала Kafka позволяет распределять данные по нескольким серверам, что делает их масштабируемыми, в отличие от модели размещения на одном сервере.
- Скорость. Kafka разделяет потоки данных, поэтому задержки минимальны.
- Надёжность. Разделы распределяются и реплицируются на множество серверов, а все данные записываются на диск. Это помогает защититься от сбоев сервера, позволяя добиться высокой надёжности и отказоустойчивости.
Зачем использовать Apache Kafka
Данная система отлично подходит для задач, в рамках которых требуется собирать, хранить и обрабатывать большие неструктурированные данные. Например, это могут быть платформы, аккумулирующие данные из множества источников, сервисы, которые занимаются стриминговой аналитикой.
Что такое Apache Kafka и зачем это нужно
Изначально Apache Kafka была разработана под собственные цели LinkedIn, а именно, обмена данными между службами, создания бэкапов, потоковой передачи информации о деятельности приложений. Для других организаций она может стать средством обмена сообщениями между микросервисами, обрабатывать потоковые данные, перемещать Big data из одного источника в другой.
В сфере Интернета вещей, Kafka также может быть незаменима. Платформы IoT собирают огромное количество данных с разных устройств, и северы получают возможность обрабатывать их в реальном времени.
Таким образом Apache Kafka может оказаться полезной практически в любой отрасли от транспортной сферы до разработки программного обеспечения.
Источник: www.cloud4y.ru
Видео: основы Apache Kafka

Основная задача, которую выполняет Apache Kafka, — это передача данных из системы источника в целевую систему. При такой схеме всё просто. Но что если у вас 4 source-системы и 6 target-систем?
В таком случае вам придётся реализовать 24 интеграции. Каждая интеграция требует протокола взаимодействия, формата данных и валидации по схеме. Также нам необходимо выполнить нефункциональные требования, такие как:
- надёжность и гарантия доставки;
- подключение новых получателей (target систем);
- интеграция разных стеков.
Такая задача уже не кажется простой.
Почему стоит использовать Apache Kafka
Apache Kafka — это распределённое, отказоустойчивое решение с гибкой архитектурой. Скейлится до 100 брокеров и миллиона запросов в секунду, по опыту удавалось выжать 550-600 тысяч сообщений в секунду, до миллиона не доходил. Есть возможность обрабатывать данные с задержкой менее чем 10 ms, то есть в реальном времени.
Apache Kafka создали в компании LinkedIn. С 2012 года это Open Source проект в составе Apache Foundation. Kafka написан на Scala и Java, а своё название получил в честь писателя Франца Кафки.
Для чего можно использовать Kafka:
- Система обмена сообщений в микросервисной архитектуре.
- Сбор журналов событий, логов и метрик с различного ПО и оборудования.
- Stream processing — возможность потоковой обработки данных хранящихся в Кафке.
- Интеграция с Apache Spark, Storm, Hadoop и другими технологиями, использующимися для Big Data и Machine Learning-решений.
Kafka используют в 2000+ компаниях — то есть это очень распространённое программное обеспечение.
- Netflix применяет для онлайн-рекомендаций, пока вы смотрите кино.
- Uber собирает всю информацию о такси и поездках в реальном времени, также высчитывает маршрут, прогнозирует загруженность и считает цену поездки.
- LinkedIn использует для спама и сбора данных о действиях пользователей в режиме реального времени.
Во всех этих кейсах Kafka выступает в роли транспорта.
Основные сущности Apache Kafka
Основными сущностями для Apache Kafka являются:
- Broker — часть, отвечающая за приём, передачу и хранение сообщений.
- ZooKeeper — отдельный вспомогательный продукт для хранения состояния кластера, конфигурации и метаданных.
- Message или Record — сами данные.
- Producer — информационная система, которая отправляет данные в Kafka.
- Topic — то, куда попадают данные. Отправляются они в том же порядке что и прилетели (FIFO).
- Consumer — тот, кто получает данные из Kafka.
Record состоит из полей Key — опциональное поле для распределения сообщений по кластеру, Value — массив байт, Timestamp — время сообщения в формате Unix time, Headers — key-value пары с пользовательскими атрибутами.
Topic может быть разделён на партиции для организации высокопроизводительной работы. Партиции могут быть распределены между узлами кластера, но Kafka может это сделать неравномерно.
Например, у вас три топика с тремя партициями. Один топик очень нагруженный, а два — не очень. Kafka может все партиции нагруженного топика распределить на один узел, и он будет очень нагружен. Это решается ручным конфигурированием.
Данные топика или партиции хранятся в log-файлах. Обычно там три файла: .log, .index и .timeindex. Они хранят в себе всю информацию по сообщениям.
В .log хранятся данные, offset, position и timestamp. В index хранится маппинг offset на position, а в timeindex — маппинг timestamp на offset. Максимальный размер .log-файла — 1GB. Когда этот размер превышен, создаются новые три файла log, index и timeindex. Эти три файла называются сегментами.
Особенности Kafka
Kafka не поддерживает ручное удаление данных из топика. Только автоматическая чистка по времени, которая настраивается через параметр Time-To-Live.
Kafka поддерживает репликацию, чтобы при потере узла кластера не потерялись данные. За это отвечает параметр replication-factor, который говорит, сколько копий партиций будет на разных узлах кластера.
Kafka обеспечивает согласованность данных при помощи master-slave кластеризации партиций топика. Например, топик делится на три партиции и одну из них Kafka назначает лидером. Остальные являются фолловерами.
Все операции чтения и записи происходят через лидер-реплику партиции. Поэтому если все лидер-реплики партиций окажутся на одном узле кластера, то этот узел станет самым нагруженным, а остальные будут просто отдыхать. В этом случае надо вручную перебалансировать кластер.
Если лидер-реплика умерла, нужно выбрать нового лидера. В дефолтной конфигурации фолловеры могут не обладать всеми данными. Это плохие кандидаты для лидеров.
Для исключения такой ситуации в Kafka есть механизм insync-реплик. Их количество задаётся в конфигурации. В таком случае при записи данных в лидер-реплику происходит синхронная запись в ISR-реплики-фолловеры. Такие ISR-реплики являются кандидатами на нового лидера. Внимание, это драматично влияет на производительность.
Producer отправляет сообщения только в лидер-реплик партиции. У отправителя есть опции отправки — acks. Она принимает параметры 0, 1 и −1 или all.
- Если acks = 0, значит отправителя не интересует подтверждение доставки и сообщения могут теряться. Этот режим нужен при огромных объемах данных и в специальных случаях.
- Если acks=1, значит отправитель ожидает подтверждения доставки сообщения от лидер-реплики.
- Если acks=all или −1, то отправитель ждёт синхронизации сообщения между всеми ISR-репликами лидер-реплики.
Также producer поддерживает все известные семантики доставки: at most once, at least once, exactly once (idempotence).
Consumer читает пачки сообщений только из лидер-реплики партиции. Их можно объединять в группы, чтобы в несколько потоков читать данные. Это делается при помощи параметра group.id. Consumer должен закоммитить получение данных из Kafka. Есть 2 вида коммитов: автоматические и ручные.
Если после получения данных при автокоммите consumer упал, то он не получит эти данные повторно.
Kafka — очень популярна, это проверенное, высокопроизводительное и очень гибкое решение. Но при его использовании нужно понимать нюансы.
Источник: tproger.ru
Apache Kafka для аналитика: ТОП-7 требований к интеграционной шине

Apache Kafka часто используется в качестве средства интеграции информационных систем, выполняя роль посредника при обмене сообщениями. Поэтому, чтобы сформулировать требования к подсистеме интеграции на основе Kafka, аналитику следует понимать ключевые принципы работы этой распределенной платформы потоковой передачи событий. Именно это рассмотрим далее, а также разберем, как требования определяют значения конфигураций топиков, продюсеров и потребителей.
Что такое Apache Kafka и как это работает: краткий обзор
Apache Kafka часто называют брокером сообщений, но это скорее гибрид распределенного лога и key-value базы данных. Эта распределенная платформа потоковой передачи событий часто используется в качестве шины обмена сообщениями при интеграции нескольких систем. При этом Kafka реализует принцип «издатель/подписчик», когда приложения-продюсеры отправляют сообщения в топик, откуда их считывают приложения-потребители, подписанные на этот топик. Все это происходит в режиме почти реального времени, т.е. соответствует парадигме потоковой обработки информации.
Топик в Kafka – это не физическое, а логическое хранилище сообщений, которые публикует продюсер, чтобы их считали потребители. Топик позволяет сгруппировать потоки сообщений по категориям, например, по сущностям домена: в один топик будут отправляться события пользовательского поведения, в другой – системные данные с «умных часов» или других устройств носимой электроники и т.д.
Каждый топик может быть разбит на разделы (партиции, partition). Раздел является единицей параллелизма и представляет собой журнал (лог) сообщений от одного и только одного приложения-продюсера, упорядоченных в порядке их поступления в Kafka. Порядковый номер сообщения под названием смещение (offset) определяет, когда приложения-потребители считают данные. Лог устроен по принципу FIFO (First In, First Out): первыми считываются сообщения, которые отправлены в Kafka раньше. Подробнее об этом здесь.
Разделение топика на разделы позволяет выровнять нагрузку в кластере Apache Kafka благодаря их равномерному распределению по нескольким узлам, которые называются брокеры. Кроме того, количество разделов определяет количество потоков данных, которые могут обрабатываться параллельно. При отправке данных в Apache Kafka приложение-продюсер назначает сообщение какому-то из разделов топика на основе настраиваемой стратегии, по умолчанию по ключу разделения, т.е. какому-то полю входящего сообщения.
Каждый топик может иметь один или несколько разделов, распараллеленных на разные брокеры, чтобы сразу несколько потребителей могли считывать данные из одного топика одновременно. Если количество потребителей меньше числа разделов, одно приложение-потребитель считывает сообщения из нескольких разделов.
Если потребителей больше, чем разделов, некоторые приложения-потребители не могут считывать сообщения, пока их общее количество не снизится до количества разделов. Хотя в теории разделов может быть сколько угодно, на практике их количество ограничено размером сохраняемых сообщений, которые могут поместиться на одном брокере.
Обычно на одном брокере рекомендуется держать не более 1000 разделов, включая реплики. Если в топике больше данных, чем фактически может вместить брокер, надо увеличить количество разделов. Когда приложении-потребитель подписывается на какой-то топик, он потребляет сообщения из всех разделов этого топика. Чтобы потребитель не «захлебнулся» от данных, в Kafka есть механизм объединения потребителей в группы для равномерного распределения разделов между несколькими приложениями-потребителями. А порядок чтения сообщений из раздела гарантируется тем, что Kafka дает доступ к разделу только одному потребителю из группы потребителей.
Также разделение является механизмом обеспечивается отказоустойчивости этой распределенной системы за счет копирования (реплицирования) данных на несколько брокеров. При этом «права и обязанности» брокеров, которые содержат фактически одни и те же данные, т.е. данные реплицированного раздела, разделяются:
- есть брокер-лидер (leader), который принимает запросы на чтение и запись данных от приложения-продюсера;
- есть брокеры-подписчики (followers), которые только реплицируют данные лидера и принимают запросы только на чтение сообщений.
Количество брокеров-подписчиков определяется значением фактора репликации минус один. Фактор репликации задает общее количество копий данных раздела во всем кластере, включая размещение на брокере-лидере.
Чтобы клиенты Kafka, т.е. приложения-продюсеры и потребители знали, к какому брокеру нужно подключиться, в кластере используется внешний (по отношению к Kafka) сервис синхронизации метаданных Apache ZooKeeper. Он хранит метаданные о разделах топиков и брокерах. С весны 2021 года вышло важное обновление Kafka 2.8, где на замену ZooKeeper предлагается внутренний механизм Quorum Controller, который использует новый протокол KRaft (Kafka Raft) для обеспечения точной репликации метаданных в кворуме. Однако, он все еще не рекомендуется для реальных высоконагруженных проектов. Подробнее об этом здесь и здесь.
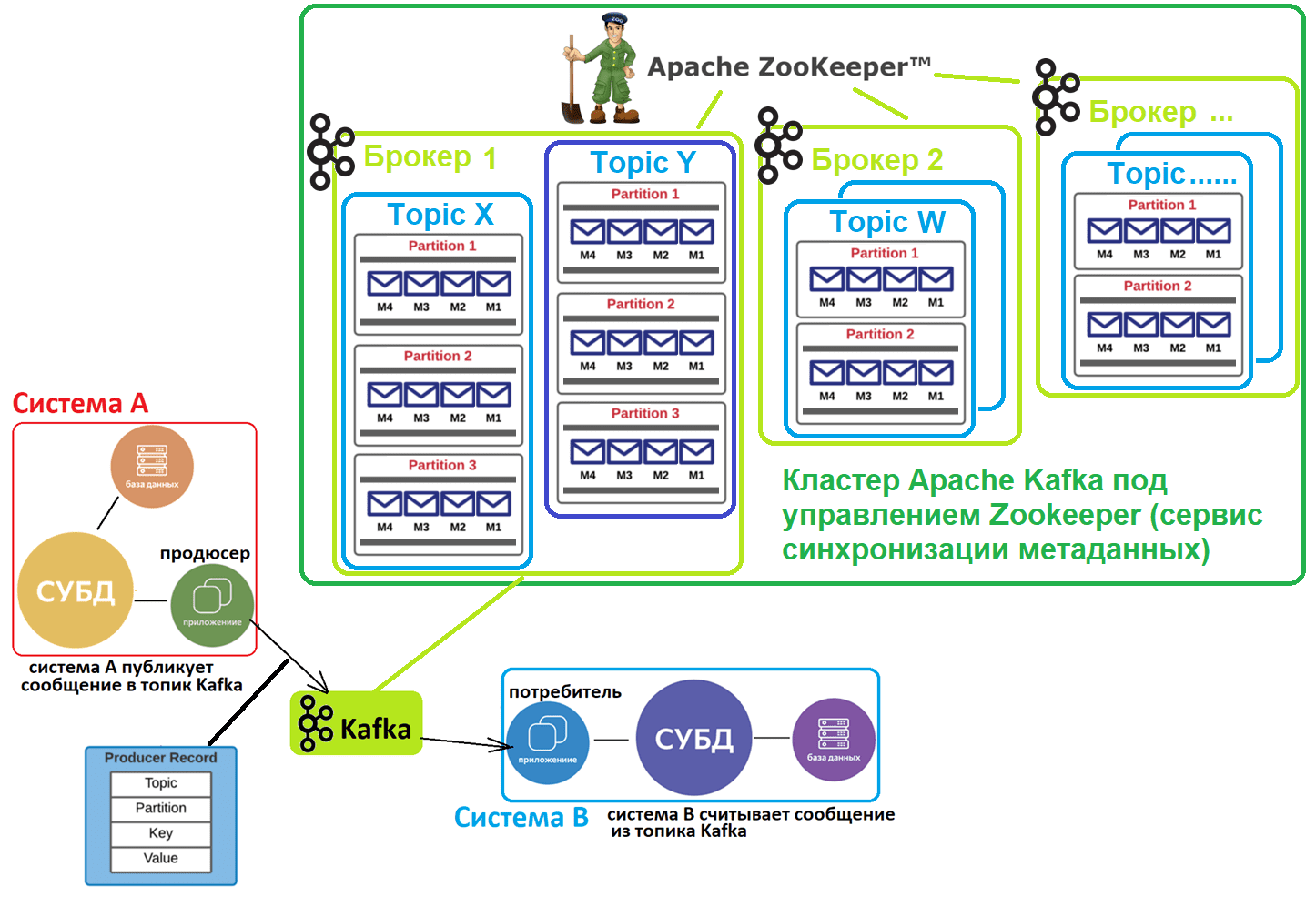
В отличие от популярного JMS-брокера сообщений Rabbit MQ, Kafka работает по принципу вытягивания (pull), когда приложения-потребители сами считывают из топиков нужные им данные. По сути, это соответствует концепции «тупой сервер, умный клиент», когда логика работы с сообщениями реализуется на клиентской стороне.
Kafka не следит, какие сообщения прочитаны потребителями, а просто хранит их на жестком диске в течение заданного периода времени или до момента превышения заданного лимита. Потребители сами опрашивают топик Kafka на предмет новых сообщений и указывают, какие сообщения нужно считать, увеличивая или уменьшая смещение. Из одного топика данные могут считывать несколько приложений-потребителей, тогда как отправлять сообщения в топик может только один продюсер, чтобы не нарушать упорядоченность событий. Подробнее про отличия Kafka и Rabbit MQ, а также разницу с другими JMS-брокерами, смотрите здесь и здесь.
Потоковая парадигма означает бесконечное поступление сообщений и их обработку в режиме реального времени, тогда как при пакетной обработке итоговое значение создается только после полной обработки всех связанных данных. Поэтому для потоковой обработки особенно важны полнота, доступность и упорядоченность сообщений, чтобы исключить дублирование и потерю данных. Для этого в Apache Kafkaгарантия доставки сообщений, реализующая семантику строго один раз (exactly once). Это значит, что если приложение-продюсер из-за сбоя сети или какой-то внутренней ошибки повторно отправит одни и те же данные в Kafka, сообщение будет записано в топик только один раз.
За реализацию этой семантики доставки сообщений отвечает свойство идемпотентности в настройках продюсера и число подтверждений об успешной записи (acknowledge, acks). Например, если параметр acks равен 0, приложение-продюсер не ждет от Kafka подтверждения об успешной записи сообщения в топик: сообщение считается отправленным в любом случае, т.е. даже при фактическом сбое записи.
Если acks равно 1, отправленное сообщение записывается в локальный лог брокера-лидера, не ожидая полного подтверждения от всех подписчиков. При этом сообщение может быть потеряно в случае сбоя лидера до репликации по всему кластеру. Если параметр acks равен -1 (all), приложение-продюсер ждет полной репликации сообщения по всем серверам кластера. Это повышает надежность системы интеграции, предотвращая потерю данных, но увеличивает задержку их обработки и снижает пропускную способность. Подробнее смотрите здесь, здесь и здесь.
Приложение-продюсер отправляет в Kafka сообщение, которое имеет следующую структуру:
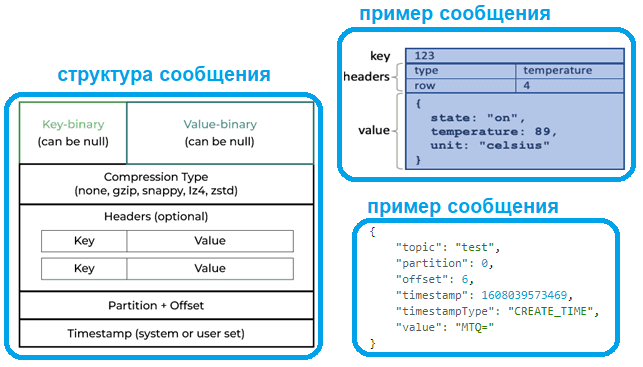
- ключ — двоичное поле, которое может быть нулевым;
- значение, которое является содержимым сообщения, и оно также может быть нулевым;
- тип сжатия сообщения – без сжатия (none) или один из кодеков (gzip, snappy, lz4, zstd);
- дополнительные заголовки, пары ключ-значение, которые содержат метаданные.
- номер раздела и идентификатор смещения, которые становятся частью сообщения, как только приложение-продюсер отправило сообщение в Kafka;
- отметка времени происхождения события, данные о котором зашиты в полезную нагрузку, т.е. значение сообщения.
Обычно полезная нагрузка представляет собой некоторое сообщение в JSON-формате, структура которого может быть задана в виде JSON-схемы, что хранится в реестре схем (Schema registry). Реестр схем – это модуль платформы Kafka от компании Confluent, что занимается коммерциализацей этой технологии. Реестр схем особенно полезен в случае множества приложений-продюсеров, которые могут посылать данные разных структур. Такое часто бывает в проектах интернета вещей (Internet of Things).
Впрочем, Kafka поддерживает не только JSON, но и другие форматы сообщений: бинарные Apache AVRO и Protobuf, текст и т.д. В любом случае, какой бы формат данных не был у исходного сообщения, в топике оно хранится в виде набора байтов. Этот процесс перевода структурированных данных в набор байтов называется сериализацией и нужен для передачи данных по сети и их хранения на жестком диске.
Для этого исходные данные сериализуются, т.е. переводятся в массив байтов с помощью сериализаторов ключей и значений. Kafka отлично работает с огромным количеством сообщений, но они должны быть небольшого размера. Максимальный размер сообщения, отправленных в топик Kafka, определяется конфигурацией message.max.bytes и по умолчанию не превышает 1 МБ.
При отправке сообщения большего размера, приложение-продюсер получит от брокера Кафка уведомление об ошибке, а само сообщение не будет принято к записи. Важно также, сколько сообщений укладывается в пакет — хотя Kafka и реализует потоковую парадигму обработки данных, сообщения от приложения продюсера отправляются в топик не сразу.
Сперва они добавляются в пакет – внутренний буфер, размер которого по умолчанию равен 32 МБ. Если продюсер отправляет сообщения быстрее, чем их можно передать брокеру, или случились проблемы с сетью, этот внутренний буфер переполняется. Тогда метод продюсера, запускающий непосредственную отправку в топик, будет заблокирован на время, указанное в конфигурации max.block.ms (по умолчанию 1 минута). Подробно об этом читайте здесь.
Поскольку сообщения в Kafka отправляются в виде пакета записей, он имеет так называемые накладные расходы: 61 байт метаданных, где указываются версия сообщения, количество записей, алгоритм сжатия, транзакция и пр. Эти накладные расходы на пакетную запись постоянны и не поддаются уменьшению. Но можно оптимизировать размер пакета, объединяя несколько сообщений в 1 пакет, сжимая данные с помощью кодеков и/или используя более экономные форматы сериализации данных, например, AVRO вместо JSON. Подробнее об этом здесь.
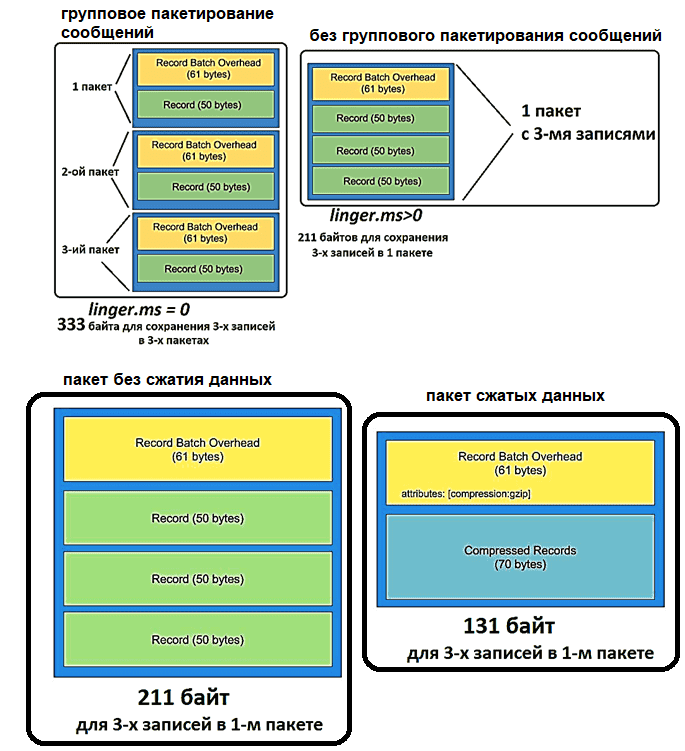
Также за задержку отправки пакета сообщений отвечают конфигурации linger.ms и batch.size. linger.ms. Увеличение linger.ms, по умолчанию равного 0, снижает количество запросов и повышает пропускную способность шины, но увеличивает задержку перед отправкой данных.
Batch.size определяет максимальный размер одного пакета сообщений: чем больше значение этого параметра, тем больше сообщений группируются в один пакет, что тоже увеличивает задержку. Конфигурации linger.ms и batch.size дополняют друг друга: пакет данных отправляется при достижении любого из этих 2 лимитов. Подробности здесь и здесь.
Источник: babok-school.ru
Краткое введение в Apache Kafka

Официальное определение для Apache Kafka — распределённая стриминговая платформа. Это одно из тех прекрасных определений, которые не имеют никакого смысла до тех пор, пока не посидишь хорошенько с документацией. На самом деле идея Кафки очень простая.
В большой распределенной системе обычно много сервисов, которые генерируют разные события: логи, данные мониторинга, замеченные попытки доступа к секретным ресурсам, и т. п. С другой стороны, есть сервисы, которым эти данные очень нужны. И тут появляется Kafka: он сидит между продюсерами и консьюмерами данных (producer https://dotsandbrackets.com/quick-intro-to-apache-kafka-ru/» target=»_blank»]dotsandbrackets.com[/mask_link]
Краткий обзор Apache Kafka
Apache Kafka — брокер сообщений, реализующий паттерн Producer-Consumer с хорошими способностями к горизонтальному масштабированию. Это Open Source разработка, созданная компанией LinkedIn на JVM стеке (Scala). 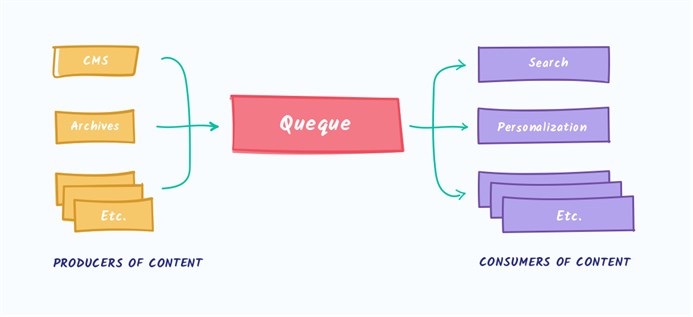 Горизонтально масштабируя какую-либо систему, вы поневоле делаете её распределённой, а работа с распределённой системой имеет свои особенности. Формально, для описания свойств распределённых систем существует CAP-теорема. В распределённой системе невозможно обеспечить одновременное выполнение всех трёх свойств: консистентности, доступности, устойчивости к сбоям узлов. Что это за свойства: Консистентность (Consistency) Говорит о том, что система всегда выдаёт только логически непротиворечивые ответы. Не бывает такого, что вы добавили в корзину товар, а после рефреша страницы его там не видите. Доступность (Availability) Означает, что сервис отвечает на запросы, а не выдаёт ошибки о том, что он недоступен. Устойчивость к сбоям сети (Partition tolerance) Означает, что распределённая по кластеру система работает в расчёте на случаи произвольной потери пакетов внутри сети. С точки зрения CAP-теоремы, Kafka имеет CA*, т.е. выполняются условия консистентности и доступности, но не гарантируется устойчивость к сбоям в сети — по отзывам пользователей, Kafka не очень устойчива к netsplit (моменту, когда ваш кластер, например, разваливается пополам), хотя официальной документации на этот счёт мы не нашли. На самом низком уровне Kafka — это просто распределённый лог-файл. То есть, по сути, файл, разбитый на несколько частей (партиций) и «раскатанный» на несколько узлов кластера. Запись в этот файл всегда происходит в конец. Разделение файла на части необходимо для ускорения чтения из очереди и горизонтального масштабирования. Ваш Topic (тема) может быть «порезан» на сколько угодно частей. Соответственно, вы можете разделить Topic на сколько угодно серверов. Из каждой партиции может читать не более одного Consumer (читатель). Это значит, что максимальное число параллельных читателей равно количеству частей, на которые разбит ваш Topic.
Горизонтально масштабируя какую-либо систему, вы поневоле делаете её распределённой, а работа с распределённой системой имеет свои особенности. Формально, для описания свойств распределённых систем существует CAP-теорема. В распределённой системе невозможно обеспечить одновременное выполнение всех трёх свойств: консистентности, доступности, устойчивости к сбоям узлов. Что это за свойства: Консистентность (Consistency) Говорит о том, что система всегда выдаёт только логически непротиворечивые ответы. Не бывает такого, что вы добавили в корзину товар, а после рефреша страницы его там не видите. Доступность (Availability) Означает, что сервис отвечает на запросы, а не выдаёт ошибки о том, что он недоступен. Устойчивость к сбоям сети (Partition tolerance) Означает, что распределённая по кластеру система работает в расчёте на случаи произвольной потери пакетов внутри сети. С точки зрения CAP-теоремы, Kafka имеет CA*, т.е. выполняются условия консистентности и доступности, но не гарантируется устойчивость к сбоям в сети — по отзывам пользователей, Kafka не очень устойчива к netsplit (моменту, когда ваш кластер, например, разваливается пополам), хотя официальной документации на этот счёт мы не нашли. На самом низком уровне Kafka — это просто распределённый лог-файл. То есть, по сути, файл, разбитый на несколько частей (партиций) и «раскатанный» на несколько узлов кластера. Запись в этот файл всегда происходит в конец. Разделение файла на части необходимо для ускорения чтения из очереди и горизонтального масштабирования. Ваш Topic (тема) может быть «порезан» на сколько угодно частей. Соответственно, вы можете разделить Topic на сколько угодно серверов. Из каждой партиции может читать не более одного Consumer (читатель). Это значит, что максимальное число параллельных читателей равно количеству частей, на которые разбит ваш Topic. 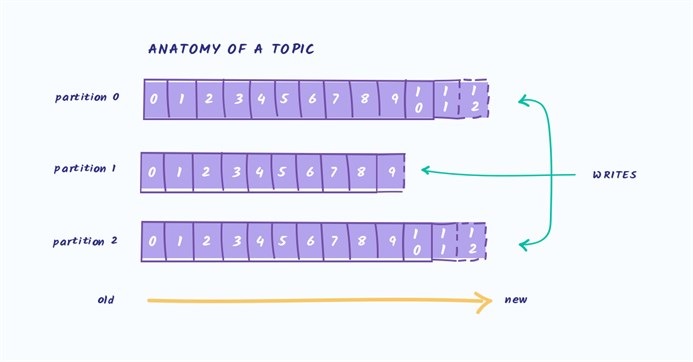 Соответственно, для одной партиции топика гарантируется очерёдность сообщений, так как из каждой партиции может читать не более одного читателя. У каждого сообщения есть свой сквозной номер внутри патриции. В терминах Kafka это называется offset. При чтении из партиции читатель делает коммит оффсета. Это необходимо для того, чтобы, если, например, текущий читатель упадёт, то следующий (новый читатель) начнёт с последнего коммита.
Соответственно, для одной партиции топика гарантируется очерёдность сообщений, так как из каждой партиции может читать не более одного читателя. У каждого сообщения есть свой сквозной номер внутри патриции. В терминах Kafka это называется offset. При чтении из партиции читатель делает коммит оффсета. Это необходимо для того, чтобы, если, например, текущий читатель упадёт, то следующий (новый читатель) начнёт с последнего коммита. 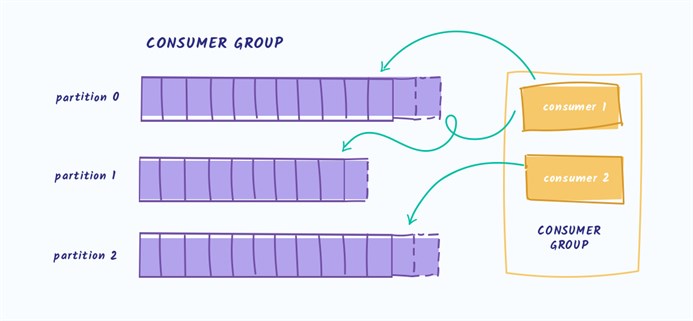 Читатели объединяются в группы, что так и называется — consumer group. При добавлении нового читателя или падении текущего, группа перебалансирутся. Это занимает какое-то время, поэтому лучший способ чтения — подключить читателя и не переподключать его без необходимости. Что касается доступности, Kafka обеспечивает репликацию сообщений и disk persistence, сохраняя сообщения на диск.
Читатели объединяются в группы, что так и называется — consumer group. При добавлении нового читателя или падении текущего, группа перебалансирутся. Это занимает какое-то время, поэтому лучший способ чтения — подключить читателя и не переподключать его без необходимости. Что касается доступности, Kafka обеспечивает репликацию сообщений и disk persistence, сохраняя сообщения на диск. 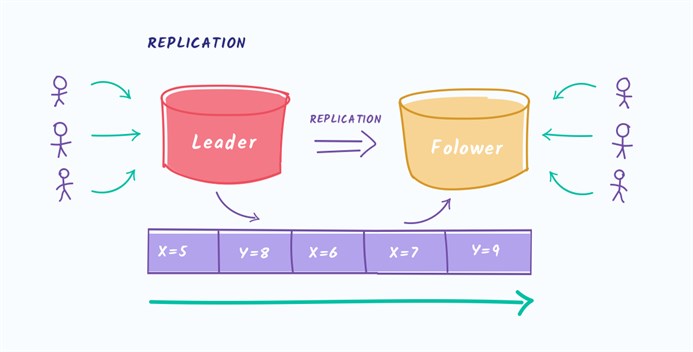 Формат репликации называется InSync. Это значит, что слейвы (в терминах Kafka это фолловеры) сами постоянно спрашивают мастера о новых сообщениях. Это pull-модель. Синхронностью/асинхронностью репликации вы можете управлять сами, указывая какие гарантии (acknowledgement) вы хотите получить при записи в очередь. Kafka поддерживает три режима:
Формат репликации называется InSync. Это значит, что слейвы (в терминах Kafka это фолловеры) сами постоянно спрашивают мастера о новых сообщениях. Это pull-модель. Синхронностью/асинхронностью репликации вы можете управлять сами, указывая какие гарантии (acknowledgement) вы хотите получить при записи в очередь. Kafka поддерживает три режима:
- отправить и не дожидаться подтверждения записи;
- отправить и дождаться подтверждения на мастер-ноде;
- отправить и дождаться подтверждения на всех репликах.
Вы должны найти компромисс между возможностью потери сообщений и минимальным откликом приложения. Чем выше гарантии доставки, тем, соответственно, дольше запись в очередь.
Поскольку Kafka гарантирует консистентность, для читателей сообщение будет видно только после записи по всем репликам. Репликация происходит отдельно для каждой партиции в топике.
Если вспомнить про disk persistence, то он вытекает из устройства Kafka. Так как вся система — это просто лог, то все сообщения в любом случае попадают на диск и это невозможно выключить, но в конфигурации можно подкрутить ручку, какими периодами сообщения падают на диск. Что, соответственно, уменьшит ваши гарантии на потерю сообщений, но увеличит производительность.
Клиенты для Kafka достаточно интеллектуальные и работают на уровне TCP. В коробке с Kafka лежит клиент на Java (так как сама Kafka написана на Scala) и библиотека на C.
Для тех, кто пишет на .NET или, например, Python, существуют open source биндинги к этой библиотеке на С. Так как это open source разработки, исходный код у вас на руках. Другое дело, что и патчить иногда придётся вам.
Мы работаем на платформе .NET, поэтому примеры кода выкладываю под .NET: примеры простой записи-чтения из шины.
Выводы: Apache Kafka менее удобна, чем тот же RabbitMQ, но если вы не можете терять сообщения, то вариант с Kafka подходит больше. К тому же у Kafka гораздо больше scalability (расширяемость).
Источник: fuse8.ru