
Автоматизация временного анализа в Analysis Services 2005
Служба Analysis Services в SQL Server 2005 подверглась коренной переработке, и, на наш взгляд, в настоящее время это самая мощная платформа бизнес-аналитики в мире. Многочисленные функции и встроенные усовершенствования Analysis Services 2005 обеспечивают автоматическое, интеллектуальное решение многих типичных задач бизнеса. Не нужно быть специалистом в программировании OLAP или многоразмерных выражений Multidimensional Expressions (MDX), чтобы строить полнофункциональные аналитические приложения.
Последние усовершенствования Analysis Services 2005 в области временного анализа позволяют быстро выполнять расчеты, учитывающие временные факторы. Для начала рассмотрим, каким образом новый мастер Business Intelligence Wizard облегчает временной анализ. Затем будут даны ответы на вопросы «как» и «почему», касающиеся внутренних механизмов мастера. И наконец, мы проанализируем методы моделирования, используемые во временном анализе, и исходный текст, генерируемый мастером, чтобы показать оптимальные приемы моделирования как метаданных, так и MDX. Данная статья представляет собой лишь краткий обзор, поэтому содержащаяся в ней информация будет полезна в первую очередь специалистам, знакомым с SQL Server 2000 Analysis Services.
Uma visão prática e básica sobre o Analysis Services
Временной анализ
Как правило, предприятиям требуется проанализировать временной ряд для данной точки в определенном наборе временных интервалов. Analysis Services позволяет выполнять вычисления на основе временных показателей — рассчитывать значения конкретной величины в течение времени, например в периоды до конкретной даты и различные формы скользящего среднего. Существует много методов моделирования этой задачи, но каждый из них требует подготовки потенциально сложного исходного текста MDX и принятия важных решений о моделировании метаданных. Последствия неоптимального решения могут быть серьезными; например, модель может оказаться значительно менее дружественной (из-за чрезмерного увеличения размерности показателей), а расчеты могут производиться слишком медленно (из-за избыточных вычислений на этапе выполнения).
В настоящее время составить удачную модель несложно. Благодаря ряду улучшений мастера Business Intelligence Wizard можно расширить и углубить модель. Для организации временных расчетов с помощью Analysis Services 2005 достаточно просто задействовать аналитические возможности Business Intelligence Wizard.
Использование мастера BI Wizard
Для временного анализа конкретного куба следует запустить Business Intelligence Wizard из контекстного меню Business Intelligence Developer Studio в Solution Explorer для размерности (dimension) или куба разработки Analysis Services 2005. На экране Choose Enhancement мастера (экран 1) перечислены усовершенствования, применимые к текущему объекту.
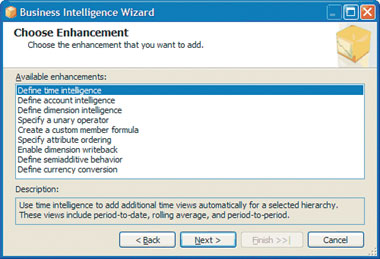 |
| Экран 1. Окно Choose Enhancement мастера Business Intelligence Wizard |
Serviços do SQL Server: O que é o Analysis Services (SSAS)?
В большинстве случаев операции временного анализа вводятся на поздних стадиях цикла разработки, после того как будет завершена работа над базовой структурой метаданных и вычислениями, не связанными со временем. Важно завершить структуру размерности дат (или времени) базы данных до добавления временной аналитики, так как в будущем на ее основе будут строиться вычисления, генерируемые мастером. Также важно принять решение о вводе в целевой куб одного или нескольких экземпляров (ролей) размерности даты (например, Ship Date — дата отгрузки, Order Date — дата заказа), так как мастер изменяет структуру этих ролей. А поскольку временная аналитика может применяться как к физическим, так и к расчетным показателям, необходимо завершить проектирование размерности показателей (в том числе расчетных показателей), чтобы иметь полный набор параметров при запуске мастера.
Перед применением временной аналитики необходимо выбрать целевую иерархию и генерируемые расчеты. На экране Choose Target Hierarchy and Calculations (экран 2) можно задать иерархию размерностей куба для анализа с использованием временного ряда и временных расчетов. Как правило, назначается пользователь или многоуровневая иерархия в размерности, чтобы обеспечить анализ на различных временных уровнях (например, Years — годы, Semesters — семестры, Quarters — кварталы). Сначала выбирается иерархия, а потом вычисления, которые должен произвести мастер. Важно обратить внимание на то, что используемый мастером шаблон вычислений — полностью расширяемый, поэтому его легко настроить в соответствии с нуждами любого потребителя, местности или отрасли.
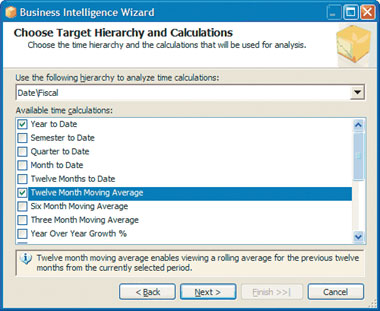 |
| Экран 2. Окно Choose Target Hierarchy and Calculations |
Первое решение — выбор иерархии для использования в качестве основы для анализа временных расчетов — заслуживает подробного объяснения, так как существенно отличается от модели Analysis Services 2000. В Analysis Services 2000 каждая размерность содержит единственную иерархию; в Analysis Services 2005 одна размерность может содержать (и чаще всего содержит) много иерархий.
Поскольку мы имеем дело со временем, велика вероятность, что целевой куб будет иметь более одной роли. Каждая роль основывается на одной размерности базы данных, но несет уникальное значение через различное отношение внешнего ключа к таблице фактов. Например, размерность базы данных Date может выполнять различные роли (Ship Date, Bill Date, Order Date) в контексте одного куба.
Размерность может иметь (и часто имеет) несколько иерархий, охватывающих различные типы календарей, например Fiscal (финансовый), Reporting (отчетный), Manufacturing (производственный) и ISO 8601. В таких случаях следует запустить мастер несколько раз, чтобы охватить несколько иерархий в различных ролях размерности. В Analysis Services 2005 мастер Dimension Wizard может за один проход автоматически генерировать размерность, которая будет содержать любые или все перечисленные типы календарей.
Затем определяется диапазон вычислений (экран 3) с указанием показателей, к которым следует применить вычисления. Мастер составляет список всех показателей куба (как физических, так и расчетных). При принятии решения о показателях следует учитывать как логическое соответствие, так и ожидания пользователей из сферы бизнеса. Выбрав показатели, нужно щелкнуть на кнопке Next, чтобы просмотреть результат выбора, а затем щелкнуть Finish, чтобы применить изменения. После этого можно исследовать куб, чтобы убедиться в его расширенных аналитических возможностях.
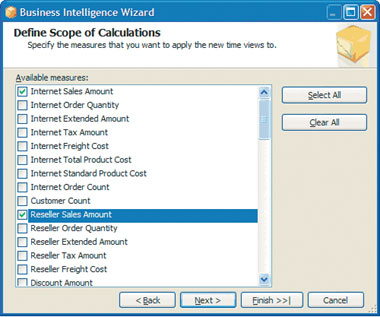 |
| Экран 3. Задание диапазона вычислений с указанием нужных показателей |
Изменения в структуре базы данных и метаданных
Теперь обратимся к внутренним механизмам и ответим на вопросы «как» и «почему» в области функционирования Business Intelligence Wizard, рассмотрим базовые структурные и невычислительные изменения метаданных, соответствующие различным этапам работы мастера.
Первым делом мастер генерирует новый именованный расчет (named calculation) в таблице временной размерности в Data Source View (DSV). Именованный расчет — это вычисляемый столбец, расположенный исключительно внутри DSV; в базовый источник данных никаких изменений не записывается. Именованный расчет служит источником для вычисленной иерархии атрибутов.
Вычисленный атрибут содержит одно невычисляемое значение (на основе именованного расчета) в дополнение ко всем выбранным пользователем вычислениям. Мастер использует константу в качестве основы для вычислений, применяя ее ко всем строкам в таблице размерностей. Этот столбец возвращает натуральные значения в качестве выбираемой по умолчанию величины и для сравнения с расчетными представлениями.
Построив столбец, мастер создает атрибут размерности, который указывает на вычисленный столбец. Поскольку иерархия данного атрибута содержит в основном вычисления, логически агрегировать эти члены нельзя. Чтобы отметить иерархию как неаддитивную, блокируется системно-генерируемый уровень All. Свойство IsAggregatable атрибута размерности управляет существованием уровня All; поскольку нам не нужно агрегировать членов в вычисленную иерархию, ему присвоено значение False.
На следующем этапе мастер назначает выбираемым по умолчанию членом вычисленного атрибута единственный невычисленный член, указанный при создании именованного расчета. Разработчики куба часто недооценивают роль выбираемых по умолчанию членов. Каждый атрибут в кубе, в том числе Measures, имеет выбираемый по умолчанию член. В отсутствие явного фильтра, задающего иное условие, выбираемый по умолчанию член иерархии автоматически включается в каждый запрос к кубу.
В нашем примере назначение выбираемого по умолчанию члена критически важно, так как требуется избежать возвращения к расчетному виду спустя какое-то время, если только не поступит явный запрос от пользователя. Чтобы подготовить точку для сравнения, нужно предоставить натуральное значение данного показателя наряду с различными расчетными. Для этого необходим наш единственный физический член. Определение члена существует во всех строках, что равносильно отсутствию фильтрационного условия.
После создания атрибута базы данных мастер анализирует структуру куба, определяя наличие нескольких ролей для размерности целевого куба. Как отмечалось ранее, в каждом проходе мастер обрабатывает одну размерность куба, и в результате появляется один расчетный атрибут. Поскольку вычисления в контексте нецелевых ролей не используются, расчетный атрибут блокируется для ролей, к которым он не применяется.
Моделирование вычислений
После того как сформирована необходимая структура куба и размерностей, можно составить собственно вычисления. В зависимости от местонахождения куба, каждый временной расчет может существовать в одном из трех состояний.
- Состояние 1. Вычисление производится над текущей координатой и имеется достаточно данных для расчета. В этих случаях применяется само выражение.
- Состояние 2. Не существует достаточных данных для вычислений. Например, выполняется сравнение периодов, и текущий период — первый в иерархии (типичный случай, когда запрошено сравнение период/период для первого периода доступных данных в кубе). Поскольку данных недостаточно, вычисления явно возвращают нулевое значение.
- Состояние 3. Вычисление неприменимо к текущей координате. Например, если текущая координата относится к Year to Date для члена All Years или Month to Date при просмотре данных за текущий год. В этих случаях вычисления, генерируемые мастером, просто возвращают строку NA или ее локализованный эквивалент.
Чтобы выяснить, к какому состоянию относится текущая координата, обычно используется функция IIF (в Analysis Services 2000); также можно использовать оператор CASE (новшество Analysis Services 2005). Однако данный подход приводит к динамическим проверкам в ходе оценки каждой ячейки на этапе выполнения, и результирующие выражения MDX быстро становятся громоздкими, а сложность отладки повышается по мере увеличения числа вложений.
В мастере Business Intelligence Wizard реализован гораздо более эффективный и изящный подход. Мастер использует новые синтаксические конструкции сценариев MDX для определения конкретных диапазонов, к которым применяются вычисления. Analysis Services оценивают операторы SCOPE статистически (один раз) при выполнении сценария MDX, поэтому данный метод исключает необязательные проверки ячеек на этапе выполнения.
Для иллюстрации этого подхода предположим, что пользователь запросил три вычисления: Year to Date, Year Over Year Growth и Twelve Month Moving Average. В листингах 1-3 показаны фрагменты сценария MDX, генерируемого мастером для этих вычислений.
Листинг 1 строит расчетных членов. Мастер присваивает значение NA учетной записи для состояния 3, к текущей координате вычисление не применяется. Специалисты, знакомые с MDX, могут отметить новый, упрощенный синтаксис оператора CREATE.
На следующем этапе (листинг 2) устанавливается диапазон вычислений для выбранных пользователем показателей. Все показатели, не попавшие в оператор SCOPE, сохраняют значение NA, так как пользователь указал, что выбранные временные аналитические вычисления неприменимы.
После того как будет указан диапазон для корректных показателей, можно назначить более значимые выражения для расчетных членов. В листинге 3 показан пример присвоений MDX, соответствующих выбранным вычислениям. Присвоения, важнейшее усовершенствование MDX в Analysis Services 2005, позволяют применять выражения MDX к существующим ячейкам в пространстве куба; результирующие значения затем агрегируются так же, как это делается при отсутствии выражений.
Полезные приемы
Рассмотрим исходный текст MDX, генерируемый мастером, и ряд специальных приемов, которые можно задействовать при подготовке собственных вычислений в Analysis Services 2005.
Как показано в листинге 3, удобно использовать иерархии атрибутов в левой стороне операции присваивания. В Analysis Services 2005 пространство куба целиком определяется атрибутами, поэтому пространство, к которому применяются вычисления, лучше всего описать иерархиями входящих в него атрибутов. И наоборот, указание диапазона для определяемых пользователем иерархий может привести к чрезмерному ограничению области вычислений. Вычисление Year to Date иллюстрирует оптимальный метод через использование иерархии атрибута Fiscal Year, которая исключает член All (где вычисление неприменимо). Данный подход охватывает все остальные атрибуты в иерархии, независимо от того, являются ли они членами All.
Следует отметить, что в правой стороне операции приравнивания используются многоуровневые пользовательские иерархии (а не иерархии атрибутов), что позволяет применить такие иерархически ориентированные функции MDX, как ParallelPeriod и PeriodsToDate.
Еще один удобный прием — задействовать функцию Aggregate (а не Sum) в вычислении Year to Date. В Analysis Services 2005 функция Aggregate применима для обработки неаддитивных разнородных счетных и полуаддитивных показателей, а также других неаддитивных величин, таких как размерности «многие ко многим» и выражения с вычислениями. Функцию Aggregate можно применять даже поверх некоторых расчетных показателей, таких как отношения.
Изучив внутренние механизмы мастера Business Intelligence Wizard, можно развернуть модифицированный куб и взглянуть на него с точки зрения конечного пользователя. На экране 4 показан Cube Browser среды развертывания с построенными вычислениями нашего примера.
Временной анализ — это просто
Как мы видим из данного примера, усовершенствованная процедура временного анализа, SQL Server 2005 Analysis Services, со множеством функций и встроенных улучшений, обеспечивает автоматическое, интеллектуальное решение типичных задач в сфере бизнеса. Благодаря этим функциям и значительно усовершенствованным графическим и аналитическим возможностям Analysis Services 2005 позволяет быстро развертывать (с быстрой окупаемостью затрат) BI-приложения, значительно превосходящие по своим возможностям прежние инструменты.
Моша Пасумански — Возглавляет группу разработчиков Microsoft Analysis Services, где отвечает за MDX, оптимизатор запросов, безопасность и программные интерфейсы. Соавтор Fast Track to MDX (издательство Springer). http://www.mosha.com/msolap
Источник: www.osp.ru
Microsoft sql Server Analysis Services
Другой значимой OLAP-технологией является BI-решение от компании Microsoft, построенное на платформе SQL Server и включающее компоненты Analysis Services и Integration Services. Это решение будет подробно рассмотрено во второй главе.
Технические аспекты многомерного хранения данных
OLAP-серверы скрывают от конечного пользователя способ реализации многомерной модели. Они формируют гиперкуб, с которым пользователи посредством OLAP-клиента выполняют необходимые манипуляции, анализируя данные. Однако способ реализации важен, поскольку от него зависят производительность решения и требуемые ресурсы.
Существует три основных способа реализации многомерной модели — MOLAP, ROLAP, HOLAP.
MOLAP (Multidimensional OLAP) — для реализации многомерной модели используются многомерные БД. При этом данные хранятся в виде упорядоченных многомерных массивов. Такие массивы подразделяются на гиперкубы, в которых все хранимые в БД ячейки имеют одинаковую мерность, и поликубы, в которых каждая ячейка хранится с собственным набором измерений. Физически данные хранятся в «плоских» файлах, при этом куб представляется в виде одной плоской таблицы, в которую построчно вписываются все комбинации элементов всех измерений с соответствующими им значениями мер (рисунок 1.10).
Преимущества использования многомерных БД в OLAP-системах:
- поиск и выборка данных осуществляется значительно быстрее, чем при многомерном концептуальном взгляде на реляционную БД, так как многомерная БД денормализована и содержит заранее агрегированные показатели, обеспечивая оптимизированный доступ к запрашиваемым ячейкам и не требуя дополнительных преобразований при переходе от множества связанных таблиц к многомерной модели;
- многомерные БД легко справляются с задачами включения в информационную модель разнообразных встроенных функций, тогда как объективно существующие ограничения языка SQL делают выполнение этих задач на основе реляционных БД достаточно сложным, а иногда и невозможным.
Недостатки MOLAP:
- за счет денормализации и предварительно выполненной агрегации объем данных в многомерной БД, как правило, соответствует (по оценке Кодда) в 2,5. 100 раз меньшему объему исходных детализированных данных;
- в подавляющем большинстве случаев информационный гиперкуб является сильно разреженным, а поскольку данные хранятся в упорядоченном виде, неопределенные значения удается удалить только за счет выбора оптимального порядка сортировки, позволяющего организовать данные в максимально большие непрерывные группы. Кроме того, оптимальный с точки зрения хранения разреженных данных порядок сортировки, скорее всего, не будет совпадать с порядком, который чаще всего используется в запросах. Поэтому в реальных системах приходится искать компромисс между быстродействием и избыточностью дискового пространства, занятого базой данных;
- многомерные БД чувствительны к изменениям в многомерной модели. Например, при добавлении нового измерения приходится изменять структуру всей БД, что влечет за собой большие затраты времени.
На основании анализа достоинств и недостатков многомерных БД можно выделить следующие условия, при которых их использование является эффективным:
- объем исходных данных для анализа не слишком велик (не более нескольких гигабайт), т. е. уровень агрегации данных достаточно высок;
- набор информационных измерений стабилен;
- время ответа системы на нерегламентированные запросы является наиболее критичным параметром;
- требуется широкое использование сложных встроенных функций для выполнения кроссмерных вычислений над ячейками гиперкуба, в том числе возможность написания пользовательских функций.
ROLAP ROLAP (Relational OLAP) — для реализации многомерной модели используются реляционные БД. В настоящее время распространены две основные схемы реализации многомерного представления данных с помощью реляционных таблиц: схема «звезда» (рисунок 1.16) и схема «снежинка» (рисунок 1.17). Если каждое измерение содержится в одной таблице, такая схема хранилища данных носит название «звезда» (star schema). Если же хотя бы одно измерение содержится в нескольких связанных таблицах, такая схема хранилища данных носит название «снежинка» (snowflake schema). Дополнительные таблицы измерений в такой схеме, обычно соответствующие верхним уровням иерархии измерения и находящиеся в соотношении «один ко многим» в главной таблице измерений, соответствующей нижнему уровню иерархии, иногда называют консольными таблицами (outrigger table).  Рис. 1.16. Пример схемы данных «звезда»
Рис. 1.16. Пример схемы данных «звезда»  Рис. 1.17. Пример схемы данных «снежинка» В сложных задачах с иерархическими измерениями целесообразно использование схемы «снежинка». В этих случаях отдельные таблицы фактов создаются для возможных сочетаний уровней обобщения различных измерений (рисунок 1.17). Это позволяет добиться лучшей производительности, но часто приводит к избыточности данных и к значительным усложнениям в структуре базы данных, в которой оказывается огромное количество таблиц фактов. Увеличение числа таблиц фактов в БД определяется не только множественностью уровней различных измерений, но и тем обстоятельством, что в общем случае факты имеют разные множества измерений. При абстрагировании от отдельных измерений пользователь должен получать проекцию максимально полного гиперкуба, причем не всегда значения показателей в ней должны являться результатом элементарного суммирования. Таким образом, при большом числе независимых измерений необходимо поддерживать множество таблиц фактов, соответствующих каждому возможному сочетанию выбранных в запросе измерений, что также приводит к неэкономному использованию внешней памяти, увеличению времени загрузки данных в БД со схемой «звезда» из внешних источников и сложностям администрирования. Использование реляционных БД в OLAP-системах имеет следующие достоинства:
Рис. 1.17. Пример схемы данных «снежинка» В сложных задачах с иерархическими измерениями целесообразно использование схемы «снежинка». В этих случаях отдельные таблицы фактов создаются для возможных сочетаний уровней обобщения различных измерений (рисунок 1.17). Это позволяет добиться лучшей производительности, но часто приводит к избыточности данных и к значительным усложнениям в структуре базы данных, в которой оказывается огромное количество таблиц фактов. Увеличение числа таблиц фактов в БД определяется не только множественностью уровней различных измерений, но и тем обстоятельством, что в общем случае факты имеют разные множества измерений. При абстрагировании от отдельных измерений пользователь должен получать проекцию максимально полного гиперкуба, причем не всегда значения показателей в ней должны являться результатом элементарного суммирования. Таким образом, при большом числе независимых измерений необходимо поддерживать множество таблиц фактов, соответствующих каждому возможному сочетанию выбранных в запросе измерений, что также приводит к неэкономному использованию внешней памяти, увеличению времени загрузки данных в БД со схемой «звезда» из внешних источников и сложностям администрирования. Использование реляционных БД в OLAP-системах имеет следующие достоинства:
- в большинстве случаев корпоративные ХД реализуются средствами реляционных СУБД, и инструменты ROLAP позволяют производить анализ непосредственно над ними. При этом размер хранилища не является таким критичным параметром, как в случае MOLAP;
- в случае переменной размерности задачи, когда изменения в структуру измерений приходится вносить достаточно часто, ROLAP-системы с динамическим представлением размерности являются оптимальным решением, т. к. в них такие модификации не требуют физической реорганизации БД;
- реляционные СУБД обеспечивают значительно более высокий уровень защиты данных и хорошие возможности разграничения прав доступа.
Главный недостаток ROLAP по сравнению с многомерными СУБД — меньшая производительность. Для обеспечения производительности, сравнимой с MOLAP, реляционные системы требуют тщательной проработки схемы базы данных и настройки индексов. Только при использовании схем типа «звезда» производительность хорошо настроенных реляционных систем может быть приближена к производительности систем на основе многомерных баз данных. HOLAP HOLAP (Hybrid OLAP) — для реализации многомерной модели используются и многомерные, и реляционные БД. HOLAP-серверы используют гибридную архитектуру, которая объединяет технологии ROLAP и MOLAP. В отличие от MOLAP, которая работает лучше, когда данные более-менее плотные, серверы ROLAP показывают лучшие параметры в тех случаях, когда данные довольно разрежены. Серверы HOLAP применяют подход ROLAP для разреженных областей многомерного пространства и подход MOLAP — для плотных областей. Серверы HOLAP разделяют запрос на несколько подзапросов, направляют их к соответствующим фрагментам данных, комбинируют результаты, а затем предоставляют результат пользователю.  Рис. 10. Гибридное ХДПример В супермаркете, ежедневно обслуживающем десятки тысяч покупателей, установлена регистрирующая OLTP-система. При этом максимальному уровню детализации регистрируемых данных соответствует покупка по одному чеку, в котором указываются общая сумма покупки, наименования или коды приобретенных товаров и стоимость каждого товара. Оперативная информация, состоящая из детализированных данных, консолидируется в реляционной структуре ХД. С точки зрения анализа представляют интерес обобщенные данные, например, по группам товаров, отделам или некоторым интервалам дат. Поэтому исходные детализированные данные агрегируются, и вычисленные агрегаты сохраняются в многомерной структуре гибридного ХД.
Рис. 10. Гибридное ХДПример В супермаркете, ежедневно обслуживающем десятки тысяч покупателей, установлена регистрирующая OLTP-система. При этом максимальному уровню детализации регистрируемых данных соответствует покупка по одному чеку, в котором указываются общая сумма покупки, наименования или коды приобретенных товаров и стоимость каждого товара. Оперативная информация, состоящая из детализированных данных, консолидируется в реляционной структуре ХД. С точки зрения анализа представляют интерес обобщенные данные, например, по группам товаров, отделам или некоторым интервалам дат. Поэтому исходные детализированные данные агрегируются, и вычисленные агрегаты сохраняются в многомерной структуре гибридного ХД.
Источник: studfile.net
Облачная аналитика с Azure Analysis Services
Azure Analysis Services — это полностью управляемая платформа как услуга (PaaS), которая предоставляет модели данных корпоративного уровня в облаке.
Расширенные функции mashups и моделирования используются для объединения данных из нескольких источников данных, определения показателей и защиты ваших данных в единой, доверенной табличной модели семантических данных.
Модель данных обеспечивает более простой и быстрый способ для пользователей просматривать огромные объемы данных для узкоспециализированного анализа данных.
Доверенная семантическая модель добавляет ценность и бизнес-логику к данным. Это делает современную аналитику доступной для конечных пользователей, чтобы использовать по максимуму свои массивные хранилища данных и извлекать выгоду из данных.
Особенности
Azure Analysis Services предлагает полный набор функций с некоторыми оговорками. Доступные функции будут зависеть от выбранного уровня (подробнее об уровнях позже).
На момент написания статьи модели Multidimensional и PowerPivot для Sharepoint не поддерживаются.
Табличные модели — это конструкции реляционного моделирования (модель, таблицы, столбцы), сформулированные в определениях объектов табличных метаданных в языке табличных моделей сценариев языка (TMSL) и табличной модели объекта (TOM). Поддерживаются разделы, перспективы, безопасность на уровне строк, двунаправленные отношения и переводы.
Поддерживаются режимы In-Memory и DirectQuery.
Режим In-Memory
Режим In-Memory является табличной моделью по умолчанию и поддерживает несколько источников данных. Поскольку данные модели сильно сжаты и кэшированы в памяти, этот режим обеспечивает самую быструю реакцию запроса на большие объемы данных. Он также обеспечивает максимальную гибкость для сложных наборов данных и запросов.
Разделение позволяет увеличивать нагрузку, увеличивает распараллеливание и снижает потребление памяти.
Поддерживаются другие расширенные функции моделирования данных, такие как рассчитанные таблицы и все функции DAX.
Модели памяти в памяти должны обновляться (обрабатываться) для обновления кэшированных данных из источников данных. Благодаря поддержке принципа обслуживания Azure автоматические операции обновления с использованием PowerShell, TOM, TMSL и REST обеспечивают гибкость в обеспечении того, чтобы данные модели всегда были актуальными.
Режим DirectQuery
Режим DirectQuery использует базовую реляционную базу данных для хранения и выполнения запросов.
Поддерживаются чрезвычайно большие наборы данных в одном SQL Server, хранилище данных SQL Server, база данных Azure SQL Database, Azure SQL Data Warehouse, Oracle и Teradata.
Наборы данных backend могут превышать доступную память ресурсов сервера.
Сложные сценарии обновления модели данных не требуются.
Существуют также некоторые ограничения, такие как ограниченные типы источников данных, ограничения формулы DAX и некоторые усовершенствованные функции моделирования данных не поддерживаются.
Серверы могут масштабироваться вертикально вверх или вниз, если требуется больше ресурсов.
Оба режима (в зависимости от уровня) предлагают возможность иметь до семи реплик запросов для масштабируемости.
При масштабировании клиентские запросы распределяются между несколькими репликами запросов в пуле запросов. Реплики запросов имеют синхронизированные копии ваших табличных моделей. Распространяя рабочую нагрузку на запрос, можно уменьшить время отклика при больших нагрузках запросов. Операции обработки модели могут быть отделены от пула запросов, при этом на запросы клиентов не оказывают негативного влияния операции обработки.
Интеграция
Azure Analysis Services имеет встроенную интеграцию в ряд локальных и облачных сервисов, включая:
- Azure SQLDB
- Azure SQLDW
- Azure Data Factory
- Hadoop
- Azure Data Lake
- Azure Data Gateway
Привычный набор инструментов также может использоваться для разработки и администрирования служб анализа Azure, включая:
- Visual Studio – SQL Server Data Tools
- Powershell
- SQL Server Management Studio
- Объектная модель и сценарии (TOM, открытые через JSON через TMSL)
Что касается инструментов конечного пользователя и уровня представления, службы Azure Analysis поддерживают новейшее и самое популярное программное обеспечение, в том числе:
- PowerBI
- Microsoft Excel
- Tableau
На момент написания SSRS не поддерживается, но можно проголосовать в его поддержку
Безопасность
На переднем крае всех облачных сервисов встает вопрос о безопасности. Услуги Azure Analysis предлагают полный набор функций безопасности, как описано ниже.
Брандмауэр
Брандмауэр Azure Analysis Services блокирует все клиентские соединения, отличные от тех IP-адресов, которые указаны в правилах. Это позволяет вашей компании контролировать тех, кто имеет доступ к какой услуге.
Правила настраиваются путем указания разрешенных IP-адресов отдельными клиентскими IP-адресами или диапазонами CIDR.
Соединения Power BI (службы) также могут быть разрешены или заблокированы. На портале есть удобный переключатель для включения или отключения этого.
Правила брандмауэра можно настроить на портале Azure или через PowerShell.
Аутентификация
Azure Active Directory (AAD) используется для обработки аутентификации пользователей. Пользователи, использующие идентификатор организации и ролевой доступ, используются для предоставления пользователям доступа к базе данных. Пользователи должны быть частью AAD для подписки, на которой находится сервер.
Защита данных и шифрование
Службы Azure Analysis Services используют хранилище Azure Blob для хранения хранилищ и метаданных для баз данных служб Analysis Services.
Файлы данных в хранилище Blob шифруются с использованием шифрования боковой стороны Azure Blob (SSE).
При использовании режима прямого запроса сохраняются только метаданные. Доступ к фактическим данным осуществляется через зашифрованный протокол из источника данных во время запроса.
Безопасный доступ к источникам данных в вашей организации возможен и достигается путем установки и настройки локального шлюза данных. Шлюзы обеспечивают доступ к данным для режимов DirectQuery и In-memory.
Роли
Служба Analysis Services использует авторизацию на основе ролей, которая предоставляет доступ к серверу, а также операции, объекты и данные базы данных модели.
Пользователи получают доступ к серверу или базе данных со своим пользователем Azure AD, которому назначена предопределенная роль. Это позволяет применять гранулярные разрешения на уровне ролей.
Роль администратора сервера находится на уровне ресурсов сервера. По умолчанию учетная запись, используемая при создании сервера, автоматически включается в роль админов сервера.
Дополнительные учетные записи пользователей и групп добавляются с помощью портала, SSMS или PowerShell.
Безопасность уровней строк и объектов
Табличная модель поддерживает безопасность на уровне строк и реализуется с использованием выражений DAX, которые определяют строки, которые пользователь может запросить. Фильтры строк с использованием выражений DAX определяются для разрешений Read и Read and Process.
Табличная модель SQL Server 2017 (уровень совместимости 1400) поддерживает защиту уровня объекта, и ее можно настроить в файле Model.bim с помощью TMSL или TOM.
Мониторинг и диагностика
Azure Analysis Services хорошо интегрирована с основными функциями мониторинга и диагностики Azure. Это включает в себя Azure Metrics, Event Hubs, Azure Storage и Log Analytics
Благодаря сочетанию этих технологий может быть построена полная и обширная платформа мониторинга, диагностики и оповещения на очень детализированном или высоком уровне.
Ценообразование и уровни
Общая стоимость зависит от ряда факторов. Включая выбранный вами регион, уровень, количество реплик запросов и графики приостановки / возобновления.
Используйте калькулятор калькуляции Azure Analysis Services для определения типичной цены для вашего региона. Этот инструмент вычисляет цену для односерверного экземпляра для одного региона. Имейте в виду, что реплики запросов тарифицируются с той же скоростью, что и сервер.
При выборе услуг Azure Analysis предлагается три уровня:
Developer
Этот уровень рекомендуется для сценариев оценки, разработки и тестирования. Один план включает те же функциональные возможности стандартного уровня, но ограничен в вычислительной мощности, QPU и объеме памяти. Шкала реплики запроса недоступна для этого уровня. Этот уровень не предлагает SLA.
Basic
Этот уровень рекомендуется для производственных решений с меньшими табличными моделями, ограниченным параллелизмом пользователей и простыми требованиями к обновлению данных. Шкала реплики запроса недоступна для этого уровня. Перспективы, множественные разделы и функции табличной модели DirectQuery не поддерживаются в этом уровне.
Standard
Этот уровень предназначен для критически важных производственных приложений, требующих эластичного параллелизма пользователей и быстро растущих моделей данных. Он поддерживает расширенное обновление данных для обновлений модели данных в режиме времени, близкого к реальному, и поддерживает все функции табличного моделирования.
Источник: www.spbdev.biz
Microsoft Analysis Services
Microsoft предлагает решение Microsoft Analysis Services, которое строится на базе MS SQL Server 2012. В отличие от специализированных решений, оно характеризуется неплохим соотношением цена-качество. Это промышленные технологии, которые могут быть использованы в банках с различными объемами бизнеса.
| — BNS Group (Мехх и Calvin Klein) БНС Групп | Корус Консалтинг | 2021.11 |  |
| — Maxxium Russia (Максиум Рус, АО Денвью Лимитэд) | Корус Консалтинг | 2017.04 | |
| — Р-Фарм | Navicon (Навикон) | 2017.03 | |
| — Heineken (Объединенные пивоварни Хейнекен) | Navicon (Навикон) | 2016.09 | |
| — Paulig Group (Паулиг РУС) | Cislink (Сислинк) | 2015.03 | |
| — Bosch в России (Роберт Бош) | Wone IT (ранее SoftwareONE Россия, СофтвэрУАН и Awara IT Russia, Авара Ай Ти Солюшенс) | 2013.01 | |
Источник: www.tadviser.ru
Работа с OLAP-системой Microsoft SQL Server Analysis Services при помощи внешних источников данных в «1С:Предприятии 8.3.5»
(бесплатная статья по Программированию в 1С)
В статье рассмотрена технология OLAP в части использовании ее как внешний источник данных для платформы «1С:Предприятие» редакции 8.3.5. Прочитав статью вы узнаете:
- Что такое технология OLAP и какие средства есть в платформе для работе с ней?
- Как опубликовать куб OLAP SQL Server с помощью Internet Information Service (IIS) и обращаться к нему из Excel?
- Как обратиться к кубу OLAP из системы «1С:Предприятие»?
Применимость
В статье используется Microsoft SQL Server 2008 R2, работающий под управлением Windows Server 2008 R2 и платформа «1С:Предприятие» редакции 8.3.5. Материал актуален и для текущих релизов платформы.
Работа с OLAP-системой Microsoft SQL Server Analysis Services при помощи внешних источников данных в «1С:Предприятии 8.3.5»
В предыдущей статье ( Запись во внешние источники данных в «1С:Предприятие 8» ) мы познакомились с функционалом записи во внешние источники данных при помощи платформы 8.3.5.823.
Сегодня мы остановимся на еще одной очень интересной возможности работы с внешними источниками данных – взаимодействие с OLAP.
OLAP (от англ. online analytical processing – аналитическая обработка в реальном времени) – технология обработки данных, заключающаяся в подготовке суммарной (агрегированной) информации на основе больших массивов данных, структурированных по многомерному принципу.
Данные в OLAP-системах формируются на основании данных OLTP-систем. OLAP-системы предназначены для быстрой выборки сложных многомерных данных, которые в OLTP-системах из-за сложной табличной структуры базы данных будут выполняться медленно.
Для обеспечения скорости получения данных OLAP-системы используют специальную структуру хранения данных, называемую кубом.
Куб (cube) можно представить в виде пространства, оси которого представляют собой измерения (dimensions), а в узлах этого пространства располагаются некоторые меры (measures). Каждое измерение куба характеризуется определенными членами (members) измерения.
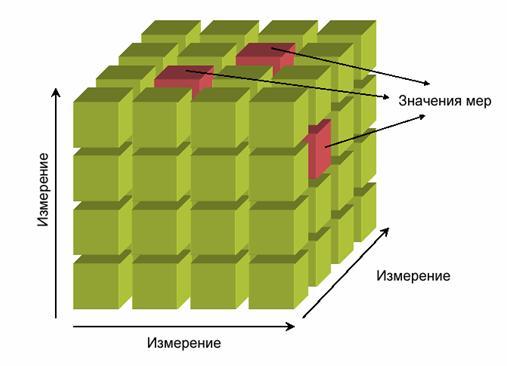
Можно провести аналогию между OLAP-кубом и регистром накопления. Измерение регистра схоже с измерением куба, значения измерения регистра соответствует членам измерения куба, а ресурс регистра представляет меру куба.
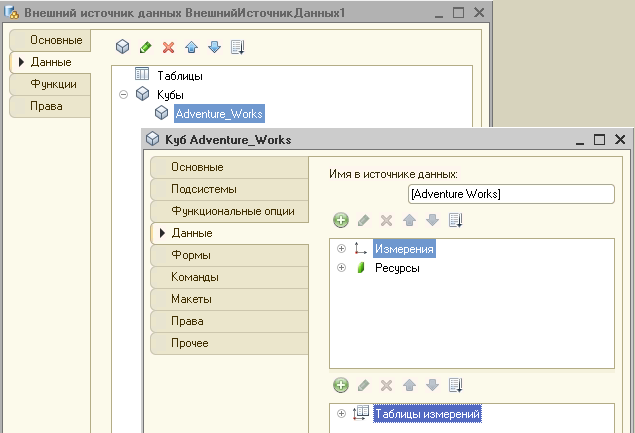
Рассмотрим, как устроен куб OLAP-системы в «1С:Предприятии». Куб состоит из таблиц измерений, измерений и ресурсов.
Таблицы измерений описывают набор членов измерений куба. Измерения объекта метаданных соответствуют измерениям куба в OLAP-системе.
Меры куба в платформе реализованы ресурсами, которые могут принимать значения типа Число и Строка.

Для работы с многомерными внешними источниками данных используется механизм XMLA (XML for Analysis). Платформа получает доступ к данным с помощью HTTP-запросов к веб-серверу.
Рассмотрим пример. Подключимся из информационной базы «1С:Предприятие» к Microsoft Analysis Services. Все действия выполняются на СУБД Microsoft SQL Server 2008 R2 под управлением операционной системы Windows Server 2008 R2.
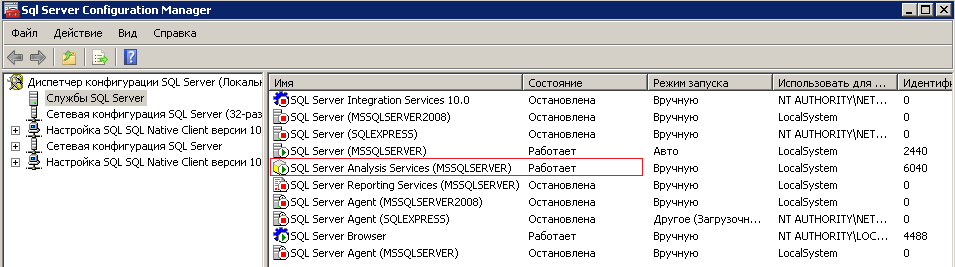
Для начала убедимся, что служба Microsoft SQL Server Analysis Services запущена. Проверяем это в Диспетчере конфигурации SQL Server:
Для экспериментов загрузим тестовую базу данных AdventureWorks и подготовленный куб с сервера http://msftdbprodsamples.codeplex.com/releases/view/59211.
Присоединим загруженные базы формата MDF при помощи SQL Management Studio:

Далее подключившись к серверу Analysis Services мы восстанавливаем базу данных из файла Adventure Works DW 2008R2.abf:
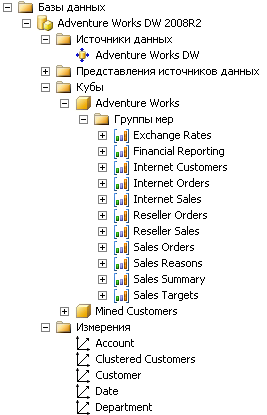
После окончания загрузки проверяем работоспособность куба Adventure Works. Щелкаем по нему правой кнопкой мыши и выбираем Обзор.
В открывшемся конструкторе мышью перетаскиваем поля в строки и столбцы сводной таблицы. Данные выбираются из базы, следовательно, загруженные базы функционируют.
Analysis Services для работы по HTTP требуется IIS. Значит, следующей нашей задачей будет развертывание веб-сервера IIS. При помощи Диспетчера сервера устанавливаем роль Веб-сервер (IIS) со следующими службами ролей:
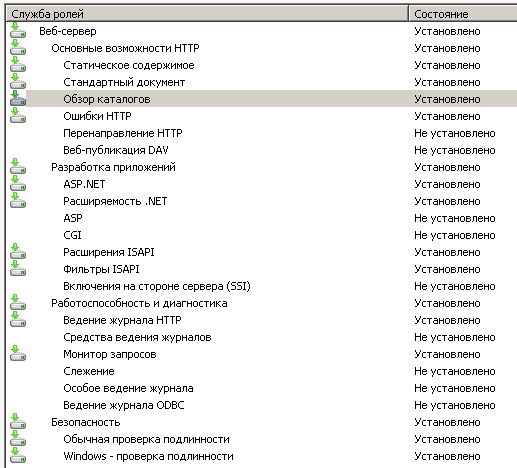
После установки служба веб-сервера может останавливаться с ошибкой:
Каталог, указанный для временных файлов конфигурации пула приложений, или отсутствует, или недоступен для службы активации Windows. Укажите существующий каталог и убедитесь, что флаги доступа установлены должным образом. Поле данных содержит номер ошибки.
Поиск в интернете (http://technet.microsoft.com/en-us/library/cc734935%28v=ws.10%29.aspx) подсказал решение этой проблемы: не была создана папка %SystemDrive%inetpubtempappPools.
После создания папки вручную и установки необходимых прав служба веб-сервера запускается стабильно.
Копируем в новую папку c:inetpubOLAP_HTTP содержимое каталога c:Program FilesMicrosoft SQL ServerMSAS10_50.MSSQLSERVEROLAPbinisapi.
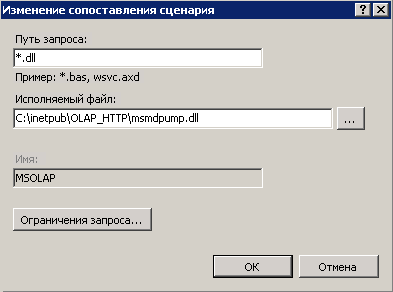
Дальнейшие настройки выполняем при помощи Диспетчера служб IIS. Выбираем пункт Ограничения ISAPI и CGI.
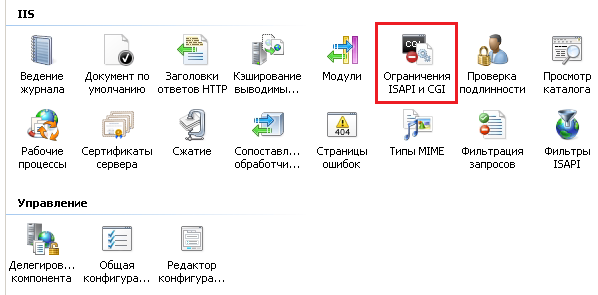
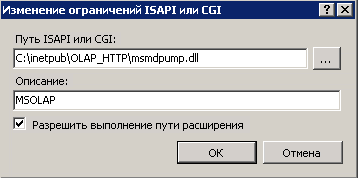
Добавляем новое ограничение, указываем путь к файлу в нашем новом каталоге C:inetpubOLAP_HTTPmsmdpump.dll.
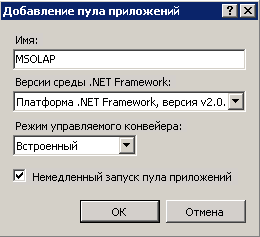
Добавляем новый пул приложений, которому присваиваем имя MSOLAP:
В диспетчере служб IIS в дереве разворачиваем пункт Сайты, в строке Default Web Site при помощи правой кнопки мыши добавляем приложение с именем MSOLAP:
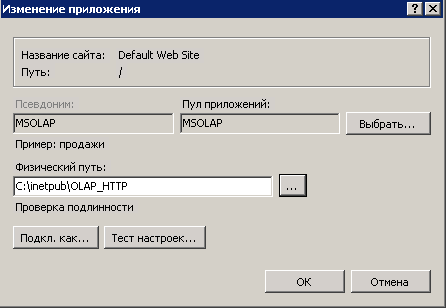
Для появившегося приложения заходим в пункт Сопоставление обработчиков и выбираем Добавить сопоставление сценария:
Далее необходимо настроить аутентификацию. В разделе Проверка подлинности включаем настройку Анонимная проверка подлинности, все остальные способы аутентификации отключаем.
Попробуем подключиться к службам аналитики SQL Server из Excel:
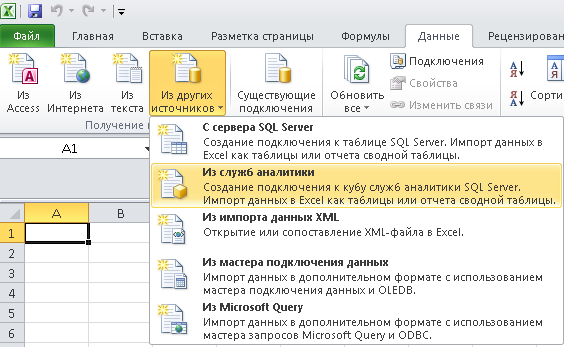
В строке соединения указываем http://localhost/msolap/msmdpump.dll. Имя пользователя и пароль оставляем пустыми, поскольку была настроена анонимная проверка подлинности.
Подключение происходит успешно, выбираем куб Adventure Works для подключения:
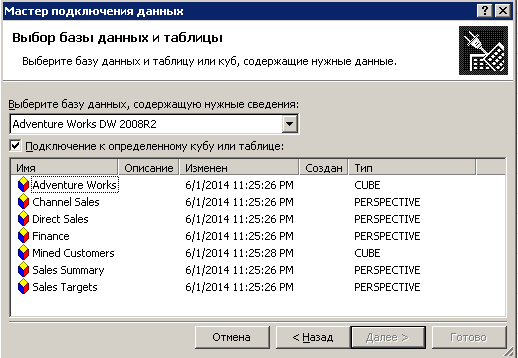
При нажатии кнопки Далее мастер предложит сохранить файл подключения. Соглашаемся, этот файл нам еще понадобится для соединения с кубами из «1С:Предприятия».
А в Excel можно построить сводную таблицу по данным выбранного куба.
Если открыть сохраненный файл подключения в Блокноте, то можно увидеть атрибут ConnectionString:

В конфигураторе добавляем новый внешний источник данных, в него добавляем новый куб.
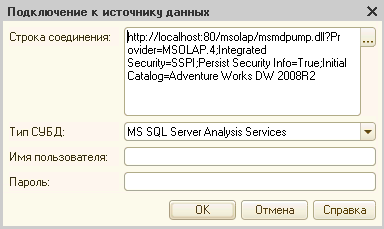
Заполняем строку подключения на основании указанного выше фрагмента файла подключения:
http://localhost:80/msolap/msmdpump.dll?Provider=MSOLAP.4;Integrated
Security=SSPI;Persist Security Info=True;Initial Catalog=Adventure Works DW 2008R2
После успешного подключения будет открыт список кубов с таблицами измерений, полями и ресурсами. Отмечаем необходимые объекты:
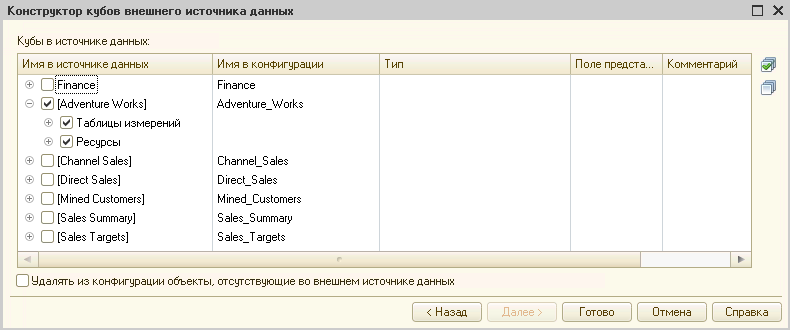
Полученный в конфигурации куб можно использовать как источник данных для запроса, в системе компоновки данных, как источник для динамических списков.
Напишем отчет на СКД, базирующийся на запросе к загруженному кубу:
ВЫБРАТЬ
Adventure_Works.Product_Category_Category,
Adventure_Works.Customer_Customer_Customer,
Adventure_Works.Internet_Sales_Amount
ИЗ
ВнешнийИсточникДанных.ВнешнийИсточникДанных1.Куб.Adventure_Works КАК Adventure_Works
Определим один ресурс – Internet_Sales_Amount.
При выполнении отчета в пользовательском режиме получим следующий результат:

Сравним полученные итоги с аналогичным, сформированным в SQL Server Analysis Services:

Также формируем сводную таблицу в Excel:

Как видим, результаты получились одинаковыми.

PDF-версия статьи для участников группы ВКонтакте
Если Вы еще не вступили в группу – сделайте это сейчас и в блоке ниже (на этой странице) появятся ссылка на скачивание материалов.
Статья в PDF-формате
Если Вы уже участник группы – нужно просто повторно авторизоваться в ВКонтакте, чтобы скрипт Вас узнал. В случае проблем решение стандартное: очистить кеш браузера или подписаться через другой браузер.
Сделал все по инструкции, Эксель пишет: “Не удается получить список баз.” Подключился “Microsoft SQL Server Management Studio” Если подключаюсь указанием сервер баз данных, то все нормально показывает, а через веб базы не показывает и пишет, что прав у меня нет. Это мне где права добавить то?
Источник: xn—-1-bedvffifm4g.xn--p1ai