
Компьютерное Го
AlphaGo — программа играющая в Го, разработанная Google DeepMind в 2015 году. AlphaGo — первая в мире программа, которая выиграла равный матч у профессионала.
Источник: go-game.ru
AlphaGo на пальцах
Итак, пока наши новые повелители отдыхают, давайте я попробую рассказать как работает AlphaGo. Пост подразумевает некоторое знакомство читателя с предметом — нужно знать, чем отличается Fan Hui от Lee Sedol, и поверхностно представлять, как работают нейросети.
Disclaimer: пост написан на основе изрядно отредактированных логов чата closedcircles.com, отсюда и стиль изложения, и наличие уточняющих вопросов
Программа AlphaGo: Как компьютер научился играть в го
Как все знают, компьютеры плохо играли в Го потому, что там очень много возможных ходов и пространство поиска настолько велико, что прямой перебор помогает мало.
Лучшие программы используют так называемый Monte Carlo Tree Search — поиск по дереву с оценкой нодов через так называемые rollouts, то есть быстрые симуляции результата игры из позиции в ноде.
Сначала поговорим про составные кусочки, а потом как они комбинируются
Шаг 1: тренируем нейросеть, которая учится предсказывать ходы людей — SL-policy network
Берем 160K доступных в онлайне игр игроков довольно высокого уровня и тренируем нейросеть, которая предсказывает по позиции следующий ход человека.
Архитектура сети — просто 12 уровней convolution layers с нелинейностью и softmax на каждую клетку в конце. Такая глубина в целом сравнима с сетями для обработки изображений прошлого поколения (гугловский Inception-v1, VGG, все эти дела)
Важный момент — что нейросети дается на вход:
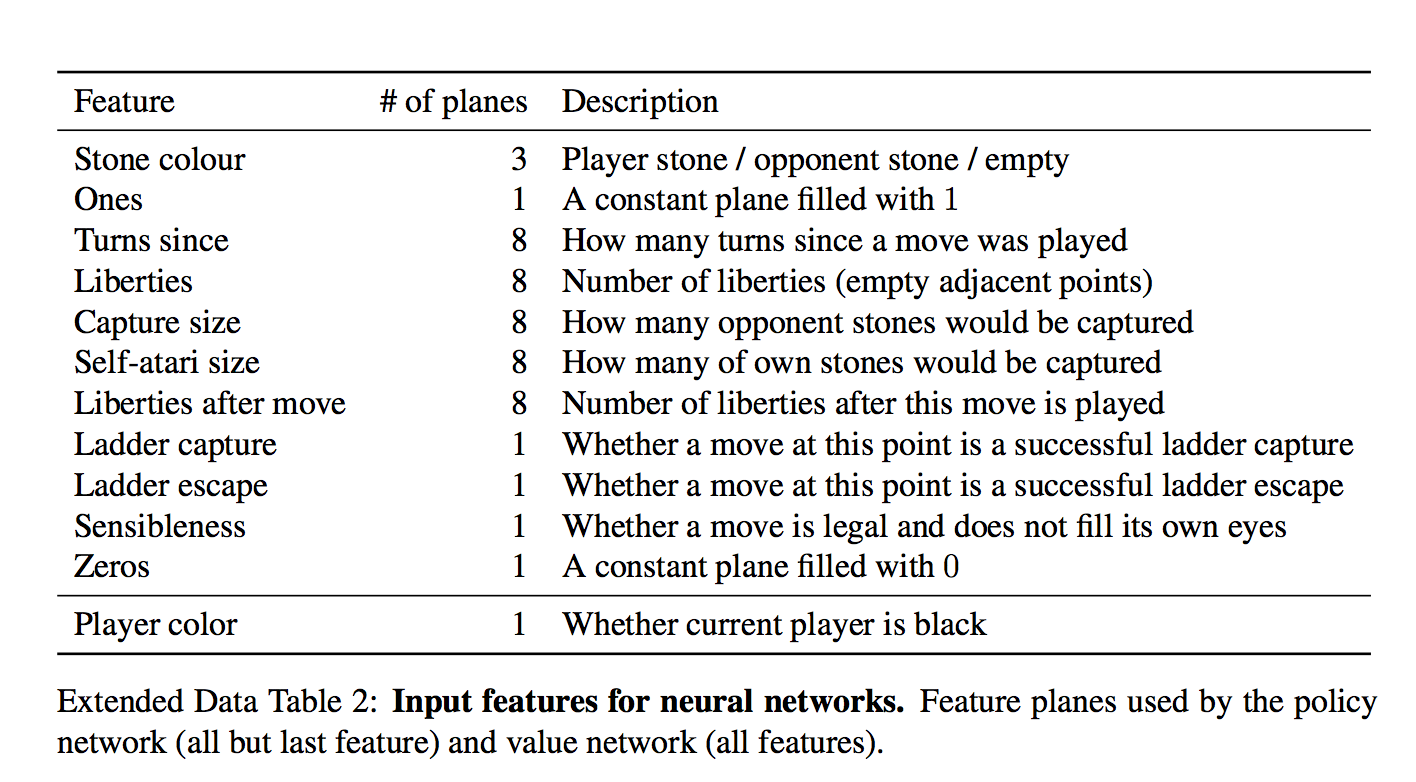
Для каждой клетки на вход дается 48 фич, они все есть в таблице (каждое измерение — это бинарная фича)
Набор интересный. На первый взгляд кажется, сети нужно давать только есть ли в клетке камень и если есть, то какой. Но фиг там!
Есть и тривиально вычисляющиеся фичи типа «количество степеней свободы камня», или «количество камней, которые будут взяты этим ходом»
Есть и формально неважные фичи типа «как давно было сделан ход»
И даже специальная фича для частого явления «ladder capture/ladder escape» — потенциально долгой последовательности вынужденных ходов.
а что за «всегда 1» и «всегда 0»?
Они просто чтобы добить количество фич до кратного 4-м, мне кажется.
И вот на этом всем сетка учится предсказывать человеческие ходы. Предсказывает с точностью 57% и к этому надо относиться осторожно — цель предсказания, человеческий ход, все же неоднозначен.
Новая AlphaGo сама научилась играть еще лучше. И обыграла все предыдущие версии
Разработчики DeepMind создали новый алгоритм для программы AlphaGo — искусственного игрока в го. По сравнению с предыдущими моделями новая AlphaGo при обучении была ориентирована строго на обучение с подкреплением (то есть без обучающей выборки). Новая система одержала абсолютную победу над всеми своими предшественниками. Работа опубликована в Nature.
Го — настольная игра, популярная в странах Азии. Сформулировать основные правила игры можно следующим образом. Два игрока получают камни разных цветов (черного и белого), и задача каждого из них — огородить большую территорию своими камнями на гобане — игровой доске. Одна партия может занимать от 10 минут до нескольких часов, а число возможных комбинаций больше числа атомов во Вселенной. Именно из-за огромного количества данных, необходимых для разработки стратегии эффективной игры, разработка компьютерного игрока в го долгое время оставалась недоступной задачей.
Программа AlphaGo была представлена DeepMind, экспериментальным подразделением Google, в 2015 году. Первая версия работала с использованием двух нейросетей: одна вычисляла вероятность ходов, а вторая — оценивала позицию камня на доске. AlphaGo тогда практически полностью полагалась на обучение с учителем, использовала в качестве обучающей выборки данные об успешных ходах игроков-людей, а также поиск по дереву методом Монте Карло, который часто применяется в создании компьютерных игроков. Задача такого поиска — выбрать наиболее выигрышный вариант, анализируя сыгранные и удачные ходы в игре. Алгоритм показал свою эффективность практически сразу же, обыграв профессионального игрока Фаня Хуэя.
Затем разработчики DeepMind улучшили алгоритм, расширив использование в системе обучения с подкреплением — вида машинного обучения, при котором алгоритм обучается, не имея при этом обучающую выборку в виде пары «входные данные — ответ». Тогда AlphaGo смогла обыграть другого игрока в го — Ли Седоля, которого уже относят к сильнейшим игрокам в мире. После этого разработчики модернизировали алгоритм еще раз: последняя версия AlphaGo обыграла третьего сильнейшего игрока в го, Кэ Цзэ, и ушла из спорта. Тем не менее, разработчики DeepMind не прекратили работу над программой и теперь представили новую версию своего игрока.
В отличие от своих предшественников, новая версия AlphaGo (чтобы обозначить, что противником «игрока» является он сам, авторы статьи добавили к его названию индекс Zero) работает строго благодаря обучению с подкреплением, не используя информацию, полученную от игроков-людей. Вместо этого новый алгоритм учится сам: берет в качестве входных данных положения черных и белых камней и начинает со случайной игры, со временем улучшая качество. На каждом шаге алгоритм подключает поиск по дереву методом Монте Карло, высчитывая вероятность следующего шага, а также подбирает следующий за ним наиболее эффективный ход. Таким образом, новый алгоритм обучился игре сам у себя.
Алгоритм обучался около трех дней и успел за это время сыграть около пяти миллионов партий с самим собой. После этого разработчики сравнили работу AlphaGo Zero со всеми предыдущими версиями, обыгравшими ведущих игроков-людей. Все старые версии проиграли AlphaGo Zero со счетом 0:100.
Таким образом, разработчики AlphaGo показали, что сверхчеловеческий (по словам авторов) уровень игры может быть достигнут и без прямого взаимодействия с информацией, полученной от людей. К сожалению, играть против профессионалов-людей новый алгоритм, скорее всего, не будет.
Помимо го разработчики DeepMind также занимаются разработкой и других игровых алгоритмов. Например, здесь вы можете узнать о нейросети, которая играет в StarCraft — и пока что не очень успешно. Дополнительные подробности об истории создания и существования AlphaGo в профессиональном спорте вы можете прочитать в нашем материале.
Источник: nplus1.ru
ИИ AlphaGo от Google DeepMind стал полностью самообучаемым
Исследования ИИ быстро продвигаются в самых разных областях, от распознавания речи и классификации изображений до генетики и открытия новых видов лекарств. Во многих случаях это специализированные системы, которые используют огромное количество человеческих знаний и данных.
Однако для некоторых задач человеческие знания могут быть слишком дорогостоящими, ненадёжными или просто недоступными. Поэтому давняя цель исследований ИИ заключается в том, чтобы обойти этот шаг, создавая алгоритмы, которые достигают сверхчеловеческой производительности в самых разных и сложных областях без человеческого участия.
Компания DeepMind, британское подразделение Google, опубликовала статью в научно-популярном журнале Nature, демонстрирующую значительные шаги навстречу данной цели.
AlphaGo Zero
Эта статья представляет миру проект AlphaGo Zero, являющийся потомком AlphaGo, первой в мире компьютерной программы, победившей человека-чемпиона в игру го. Zero является еще более мощным и, возможно, самым сильным игроком го в истории.

Предыдущие версии AlphaGo обучались игре по предоставленным им тысячам игр любителей и профессионалов го. Новый ИИ AlphaGo Zero пропускает этот шаг и обучается игре, просто-напросто играя в неё против себя, начиная с совершенно случайной игры. При этом он быстро превзошёл человеческий уровень игры и победил бывшего чемпиона AlphaGo со счётом 100:0.
Сам себе учитель
Подобный результат стал возможным благодаря использованию подхода обучения с подкреплением. Именно в таком виде обучения AlphaGo Zero становится своим собственным учителем. Система начинает самообучение с нейронной сетью, которая ничего не знает о го. Затем ИИ играет против себя, объединяя свою нейронную сеть с мощным алгоритмом поиска. С течением времени нейронная сеть настраивается и обновляется для прогнозирования ходов и возможного победителя игры.
Обучение продолжается несколько итераций подряд, в каждой из которых производительность системы увеличивается, что приводит к появлению более точных нейронных сетей и всё более сильных версий AlphaGo Zero.
Данный подход является более мощным, чем используемые в AlphaGo, потому что он больше не ограничивается пределами человеческого знания. Вместо этого он может научиться всему у самого сильного игрока в мире: чемпиона мира AlphaGo.
Отличия Zero от своего предшественника
- AlphaGo Zero использует только чёрные и белые камни с доски Go в качестве входных данных, тогда как обучение AlphaGo включало в себя небольшое количество функций, написанных программистами специально;
- Zero использует только одну нейронную сеть, а не две. AlphaGo мог обращаться к базе игр мастеров го, в его наборе была нейронная сеть, которая имитировала их стиль, а вторая нейронная сеть оценивала качество позиций для определения победителя в каждый момент игры;
- AlphaGo Zero не использует быстрые, случайные игры, как другие программы и алгоритмы, чтобы предсказать, какой игрок выиграет от текущей позиции на доске. Вместо этого он полагается на свою нейронную сеть для оценки позиций.
Эти алгоритмические изменения делают новую версию системы более мощной и эффективной по сравнению с предыдущей версией алгоритма:
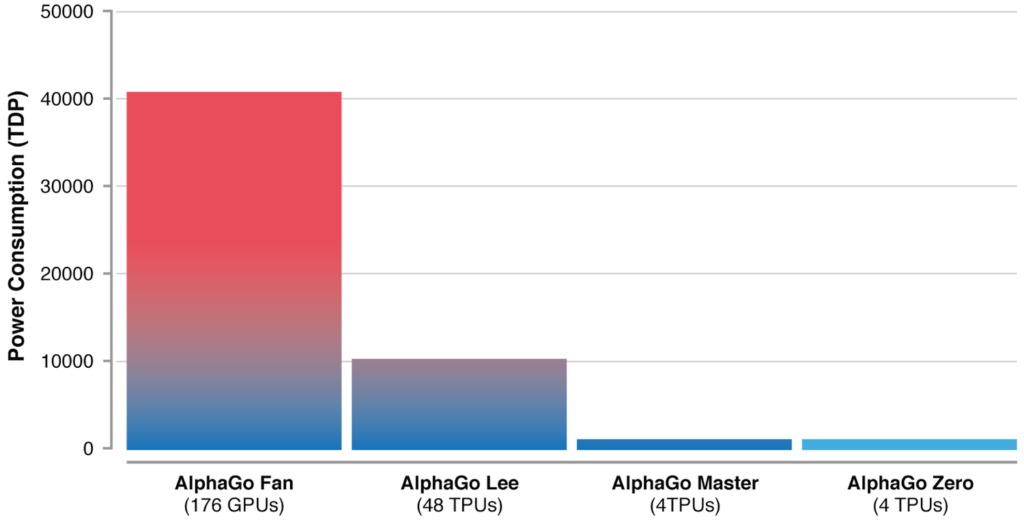
Качественный прорыв
После всего лишь трёхдневного обучения AlphaGo Zero смог победить версию AlphaGo, которая победила 18-кратного чемпиона мира Ли Седоля. После 40 дней самостоятельной подготовки AlphaGo Zero стал даже более сильным, чем версия AlphaGo, известная как «Мастер» и побеждавшая лучших игроков мира, в том числе номера один в рейтинге игроков го Кэ Цзе.
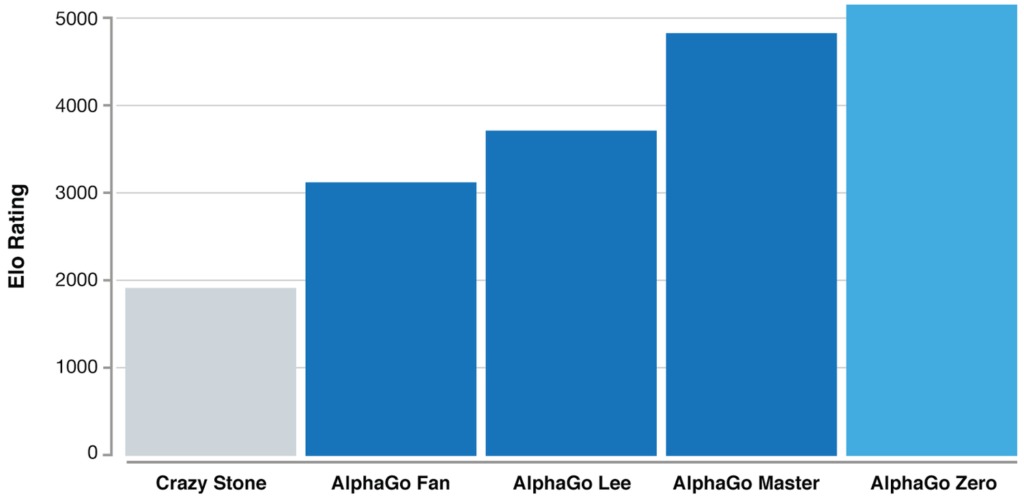
Данный график демонстрирует меру относительных уровней квалификации игроков в таких играх, как го. Это является показателем того, что AlphaGo становится все более сильным с каждым этапом развития проекта.
Польза самообучения
За время миллиона сыгранных партий «AlphaGo против AlphaGo» система постепенно изучила игру го с нуля, накопив тысячи лет человеческих знаний в течение всего лишь нескольких дней. AlphaGo Zero также обнаружил новые знания, разработал нетрадиционные стратегии и необычные подходы к решению задач, которые превзошли те методы, которые AlphaGo использовал в играх против Ли Седоля и Кэ Цзе .
Миссия ИИ
DeepMind говорят, что подобные моменты креатива, продемонстрированные ИИ, доказывают важность его использования. Он способен улучшить человеческую изобретательность и помочь в решении некоторых наиболее важных задач, стоящих перед человечеством.

Если подобные методы смогут быть применены к таким структурированным проблемам, как свёртывание белков, снижение потребления энергии или поиск революционно новых материалов, то достигнутые в этих сферах технологические прорывы положительно повлияют на общество.
Источник: tproger.ru