
Контекст: мы начали говорить об алгоритмах сортировки — смысл в том, что есть алгоритмы, которые помогают упорядочить разные неорганизованные данные. И данные, и алгоритмы могут быть разными, поэтому разработчики разбираются в этих алгоритмах, чтобы подобрать лучшее.
Что разбираем: пузырьковую сортировку — самый простой способ отсортировать массив, написав всего 6 строк кода. Она самая простая, но не самая эффективная.
Зачем это нужно: пузырьковая сортировка проще остальных, поэтому изучение всех сортировок лучше начинать именно с неё — так будет легче понять, что происходит в остальных алгоритмах. А ещё пузырьковая сортировка применяется внутри других, более эффективных алгоритмов.
Принцип работы
На каждом шаге мы находим наибольший элемент из двух соседних и ставим этот элемент в конец пары. Получается, что при каждом прогоне цикла большие элементы будут всплывать к концу массива, как пузырьки воздуха — отсюда и название.
Алгоритм выглядит так:
- Берём самый первый элемент массива и сравниваем его со вторым. Если первый больше второго — меняем их местами с первым, если нет — ничего не делаем.
- Затем берём второй элемент массива и сравниваем его со следующим — третьим. Если второй больше третьего — меняем их местами, если нет — ничего не делаем.
- Проходим так до предпоследнего элемента, сравниваем его с последним и ставим наибольший из них в конец массива. Всё, мы нашли самое большое число в массиве и поставили его на своё место.
- Возвращаемся в начало алгоритма и делаем всё снова точно так же, начиная с первого и второго элемента. Только теперь даём себе задание не проверять последний элемент — мы знаем, что теперь в конце массива самый большой элемент.
- Когда закончим очередной проход — уменьшаем значение финальной позиции, до которой проверяем, и снова начинаем сначала.
- Так делаем до тех пор, пока у нас не останется один элемент.
Пример
Возьмём массив из шести чисел и сделаем первый прогон:
Алгоритм сортировка методом пузырька

После первого прогона у нас «всплыл» самый большой элемент массива (число 11) и отправился в конец. После второго прогона на предпоследнем месте будет стоять число 9 — оно «всплывёт» наверх как самое большое число из оставшихся, потому что последние элементы мы не проверяем.
Так, шаг за шагом, мы пройдём все прогоны, каждый раз отправляя ближе к концу массива самый большой на этом этапе элемент. В итоге на последнем прогоне мы сравним первый и второй элементы, найдём из них наибольший и так получим полностью отсортированный массив.
Работает это примерно так:
Эффективность работы
Этот алгоритм считается учебным и в чистом виде на практике почти не применяется. Дело в том, что среднее количество проверок и перестановок в массиве — это количество элементов в квадрате. Например, для массива из 10 элементов потребуется 100 проверок, а для массива из 100 элементов — уже в сто раз больше, 10 000 проверок.
Как работает сортировка пузырьком
Получается, что если у нас в массиве будет 10 тысяч элементов (а это не слишком большой массив с точки зрения реальных ИТ-задач), то для его сортировки понадобится 100 миллионов проверок — на это уйдёт какое-то время. А что, если сортировать нужно несколько раз в секунду?
В программировании эффективность работы алгоритма в зависимости от количества элементов n обозначают так: O(n). В нашем случае эффективность работы пузырьковой сортировки равна O(n²). По сравнению с другими алгоритмами это очень большой показатель (чем он больше — тем больше времени нужно на сортировку).
Реализация в коде
Запустите этот код в консоли браузера, чтобы посмотреть на работу алгоритма целиком:
// исходный массив var arr = [3,1,9,8,11,6] // определяем количество прогонов // перебирать будем всё до предпоследнего элемента, каждый раз сдвигая его ближе к началу for (let j = arr.length — 1; j > 0; j—) < // основной цикл внутри каждого прогона // перебираем все элементы от первого до последнего в прогоне, который мы определили выше for (let i = 0; i < j; i++) < // если текущий элемент больше следующего if (arr[i] >arr[i + 1]) < // запоминаем значение текущего элемента let temp = arr[i]; // записываем на его место значение следующего arr[i] = arr[i + 1]; // а на место следующего ставим значение текущего, тем самым меняем их местами arr[i + 1] = temp; >// выводим текущее состояние массива в консоль // это необязательный шаг, он здесь для наглядности console.log(arr); > >
Что дальше
В следующей статье сделаем красивую визуализацию этого алгоритма на HTML и CSS — покажем, как числа всплывают как пузырьки наверх.
Получите ИТ-профессию
В «Яндекс Практикуме» можно стать разработчиком, тестировщиком, аналитиком и менеджером цифровых продуктов. Первая часть обучения всегда бесплатная, чтобы попробовать и найти то, что вам по душе. Дальше — программы трудоустройства.
Источник: thecode.media
Сортировка пузырьком
Сортировка пузырьком — это метод сортировки массивов и списков путем последовательного сравнения и обмена соседних элементов, если предшествующий оказывается больше последующего (при сортировке по возрастанию).
В процессе выполнения данного алгоритма элементы с большими значениями оказываются в конце списка, а элементы с меньшими значениями постепенно перемещаются по направлению к началу списка. Образно говоря, тяжелые элементы падают на дно, а легкие медленно всплывают подобно пузырькам воздуха. При этом в начале сортировки отсортированным становится конец списка, а не его начало.
В сортировке методом пузырька количество итераций внешнего цикла определяется длинной списка минус единица, так как когда второй элемент становится на свое место, то первый уже однозначно минимальный и не требует сортировки.
Количество итераций внутреннего цикла зависит от номера итерации внешнего цикла, так как конец списка уже отсортирован, и выполнять проход по этим элементам смысла нет.
Пусть имеется список из пяти элементов [6, 12, 4, 3, 8].
За первую итерацию внешнего цикла число 12 переместится в конец. Для этого потребуется 4 сравнения во внутреннем цикле:
- 6 > 12? Нет
- 12 > 4? Да. Меняем местами
- 12 > 3? Да. Меняем местами
- 12 > 8? Да. Меняем местами
Результат: [6, 4, 3, 8, 12]
За вторую итерацию внешнего цикла число 8 переместиться на предпоследнее место. Для этого потребуется 3 сравнения:
- 6 > 4? Да. Меняем местами
- 6 > 3? Да. Меняем местами
- 6 > 8? Нет
Результат: [4, 3, 6, 8, 12]
На третьей итерации внешнего цикла исключаются два последних элемента. Количество итераций внутреннего цикла равно двум:
- 4 > 3? Да. Меняем местами
- 4 > 6? Нет
Результат: [3, 4, 6, 8, 12]
На четвертой итерации внешнего цикла осталось сравнить только первые два элемента, поэтому количество итераций внутреннего равно единице:
Результат: [3, 4, 6, 8, 12]
Реализация сортировки пузырьком на языке программирования Python с помощью циклов for
from random import randint N = 10 a = [] for i in range(N): a.append(randint(1, 99)) print(a) for i in range(N-1): for j in range(N-i-1): if a[j] > a[j+1]: a[j], a[j+1] = a[j+1], a[j] print(a)
Пример выполнения кода:
[63, 80, 62, 69, 71, 37, 12, 90, 19, 67] [12, 19, 37, 62, 63, 67, 69, 71, 80, 90]
С помощью циклов while :
from random import randint N = 10 a = [] for i in range(N): a.append(randint(1, 99)) print(a) i = 0 while i N — 1: j = 0 while j N — 1 — i: if a[j] > a[j+1]: a[j], a[j+1] = a[j+1], a[j] j += 1 i += 1 print(a)
Функция сортировки пузырьком на Python:
from random import randint def bubble(array): for i in range(N-1): for j in range(N-i-1): if array[j] > array[j+1]: buff = array[j] array[j] = array[j+1] array[j+1] = buff N = 10 a = [] for i in range(N): a.append(randint(1, 99)) print(a) bubble(a) print(a)
X Скрыть Наверх
Решение задач на Python
Источник: younglinux.info
Пузырьковая сортировка и все-все-все

Все отлично знают, что из класса обменных сортировок самый быстрый метод – это так называемая быстрая сортировка. О ней пишут диссертации, её посвящено немало статей на Хабре, на её основе придумывают сложные гибридные алгоритмы. Но сегодня речь пойдёт не про quick sort, а про другой обменный способ – старую добрую пузырьковую сортировку и её улучшения, модификации, мутации и разновидности.
Практический выхлоп от данных методов не ахти какой и многие хабрапользователи всё это проходили ещё в первом классе. Поэтому статья адресована тем, кто только-только заинтересовался теорией алгоритмов и делает в этом направлении первые шаги.
Сегодня поговорим о простейших сортировках обменами.
Если кому интересно, скажу, что есть и другие классы – сортировки выбором, сортировки вставками, сортировки слиянием, сортировки распределением, гибридные сортировки и параллельные сортировки. Есть, кстати, ещё эзотерические сортировки. Это различные фейковые, принципиально нереализуемые, шуточные и прочие псевдо-алгоритмы, про которые я в хабе «IT-юмор» как-нибудь напишу пару статей.
Но к сегодняшней лекции это не имеет отношения, нас сейчас интересуют только простенькие сортировки обменами. Самих сортировок обменами тоже немало (я знаю более дюжины), поэтому мы рассмотрим так называемую пузырьковую сортировку и некоторые другие, с ней тесно взаимосвязанные.
Заранее предупрежу, что почти все приведённые способы весьма медленные и глубокого анализа их временной сложности не будет. Какие-то побыстрее, какие-то помедленнее, но, грубо говоря, можно сказать, что в среднем O(n 2 ). Также я не вижу резона загромождать статью реализациями на каких-либо языках программирования. Заинтересовавшиеся без малейшего труда смогут найти примеры кода на Розетте, в Википедии или где-нибудь ещё.
Но вернёмся к сортировкам обменами. Упорядочивание происходит в результате многократного последовательного перебора массива и сравнения пар элементов между собой. Если сравниваемые элементы не отсортированы друг относительно друга – то меняем их местами. Вопрос только в том, каким именно макаром массив обходить и по какому принципу выбирать пары для сравнения.
Начнём не с эталонной пузырьковой сортировки, а с алгоритма, который называется…
Глупая сортировка
Сортировка и впрямь глупейшая. Просматриваем массив слева-направо и по пути сравниваем соседей. Если мы встретим пару взаимно неотсортированных элементов, то меняем их местами и возвращаемся на круги своя, то бишь в самое начало. Снова проходим-проверяем массив, если встретили снова «неправильную» пару соседних элементов, то меняем местами и опять начинаем всё сызнова. Продолжаем до тех пор пока массив потихоньку-полегоньку не отсортируется.
«Так любой дурак сортировать умеет» — скажете Вы и будете абсолютно правы. Именно поэтому сортировку и прозвали «глупой». На этой лекции мы будем последовательно совершенствовать и видоизменять данный способ. Сейчас у него временная сложность O(n 3 ), произведя одну коррекцию, мы уже доведём до O(n 2 ), потом ускорим ещё немного, потом ещё, а в конце концов мы получим O(n log n) – и это будет вовсе не «Быстрая сортировка»!
Внесём в глупую сортировку одно-единственное улучшение. Обнаружив при проходе два соседних неотсортированных элемента и поменяв их местами, не станем откатываться в начало массива, а невозмутимо продолжим его обход до самого конца.
В этом случае перед нами не что иное как всем известная…
Пузырьковая сортировка
Или сортировка простыми обменами. Бессмертная классика жанра. Принцип действий прост: обходим массив от начала до конца, попутно меняя местами неотсортированные соседние элементы. В результате первого прохода на последнее место «всплывёт» максимальный элемент.
Теперь снова обходим неотсортированную часть массива (от первого элемента до предпоследнего) и меняем по пути неотсортированных соседей. Второй по величине элемент окажется на предпоследнем месте. Продолжая в том же духе, будем обходить всё уменьшающуюся неотсортированную часть массива, запихивая найденные максимумы в конец.
Если не только в конец задвигать максимумы, а ещё и в начало перебрасывать минимумы то у нас получается…
Шейкерная сортировка
Она же сортировка перемешиванием, она же коктейльная сортировка. Начинается процесс как в «пузырьке»: выдавливаем максимум на самые задворки. После этого разворачиваемся на 180 0 и идём в обратную сторону, при этом уже перекатывая в начало не максимум, а минимум. Отсортировав в массиве первый и последний элементы, снова делаем кульбит. Обойдя туда-обратно несколько раз, в итоге заканчиваем процесс, оказавшись в середине списка.
Шейкерная сортировка работает немного быстрее чем пузырьковая, поскольку по массиву в нужных направлениях попеременно мигрируют и максимумы и минимумы. Улучшения, как говорится, налицо.
Как видите, если к процессу перебора подойти творчески, то выталкивание тяжёлых (лёгких) элементов к концам массива происходит быстрее. Поэтому умельцы предложили для обхода списка ещё одну нестандартную «дорожную карту».
Чётно-нечётная сортировка
На сей раз мы не будем сновать по массиву взад-вперёд, а снова вернёмся к идее планомерного обхода слева-направо, но только сделаем шире шаг. На первом проходе элементы с нечётным ключом сравниваем с соседями, зиждущимися на чётных местах (1-й сравниваем со 2-м, затем 3-й с 4-м, 5-й с 6-м и так далее). Затем наоборот – «чётные по счёту» элементы сравниваем/меняем с «нечётными».
Затем снова «нечёт-чёт», потом опять «чёт-нечет». Процесс останавливается тогда, когда после подряд двух проходов по массиву («нечётно-чётному» и «чётно-нечётному») не произошло ни одного обмена. Стало быть, отсортировали.
В обычном «пузырьке» во время каждого прохода мы планомерно выдавливаем в конец массива текущий максимум. Если же передвигаться вприпрыжку по чётным и нечётным индексам, то сразу все более-менее крупные элементы массива одновременно за один пробег проталкиваются вправо на одну позицию. Так получается быстрее.
Разберём последнее покращення* для Сортування бульбашкою** — Сортування гребінцем***. Этот способ упорядочивает весьма шустро, O(n 2 ) – его наихудшая сложность. В среднем по времени имеем O(n log n), а лучшая даже, не поверите, O(n). То есть, весьма достойный конкурент всяким «быстрым сортировкам» и это, заметьте, без использования рекурсии. Впрочем, я обещал, что в крейсерские скорости мы сегодня углубляться не станем, засим умолкаю и перехожу непосредственно к алгоритму.

Во всём виноваты черепашки
Небольшая предыстория. В 1980 году Влодзимеж Добосиевич пояснил почему пузырьковая и производные от неё сортировки работают так медленно. Это всё из-за черепашек. «Черепахи» — небольшие по значению элементы, которые находятся в конце списка.
Как Вы, возможно, заметили пузырьковые сортировки ориентированы на «кроликов» (не путать с «кроликами» Бабушкина) – больших по значению элементов в начале списка. Они весьма резво перемещаются к финишу. А вот медлительные пресмыкающиеся на старт ползут неохотно. Подгонять «тортилл» можно с помощью расчёски.
image: виноватая черепашка
Сортировка расчёской
В «пузырьке», «шейкере» и «чёт-нечете» при переборе массива сравниваются соседние элементы. Основная идея «расчёски» в том, чтобы первоначально брать достаточно большое расстояние между сравниваемыми элементами и по мере упорядочивания массива сужать это расстояние вплоть до минимального. Таким образом мы как бы причёсываем массив, постепенно разглаживая на всё более аккуратные пряди.
Первоначальный разрыв между сравниваемыми элементами лучше брать не абы какой, а с учётом специальной величины называемой фактором уменьшения, оптимальное значение которой равно примерно 1,247. Сначала расстояние между элементами равно размеру массива разделённого на фактор уменьшения (результат, естественно, округляется до ближайшего целого). Затем, пройдя массив с этим шагом, мы снова делим шаг на фактор уменьшения и проходим по списку вновь. Так продолжается до тех пор, пока разность индексов не достигнет единицы. В этом случае массив досортировывается обычным пузырьком.
Опытным и теоретическим путём установлено оптимальное значение фактора уменьшения:
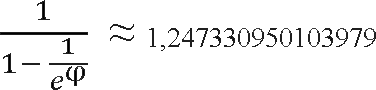
Когда был изобретён этот метод, на него на стыке 70-х и 80-х мало кто обратил внимание. Десятилетие спустя, когда программирование перестало быть уделом учёных и инженеров IBM, а уже лавинообразно набирало массовый характер, способ переоткрыли, исследовали и популяризировали в 1991 году Стивен Лейси и Ричард Бокс.
Вот собственно и всё что я хотел Вам рассказать про пузырьковую сортировку и иже с ней.
* покращення (укр.) – улучшение
** Сортування бульбашкою (укр.) – Сортировка пузырьком
*** Сортування гребінцем (укр.) – Сортировка расчёской
Источник: habr.com