
В наши дни почти все (например, фотографии, музыка, видео) стали цифровыми, и это имеет смысл, поскольку цифровым контентом можно удобно управлять. Так как же текстовые документы могут остаться позади? Благодаря достижениям в Оптическое распознавание символов (OCR) техники, теперь стало проще, чем когда-либо оцифровывать печатные или рукописные тексты.
Для этого вам нужны действительно хорошие приложения для распознавания текста, и именно об этом и рассказывается в этой статье. Это программное обеспечение может либо получать источник со сканирующих устройств, либо вы можете вводить свои собственные изображения или файлы PDF для преобразования в редактируемый текст. Заинтригованный? Ну, тогда давайте не будем биться вокруг, и перейдем к 8 лучшим программам для распознавания текста, которые вы должны использовать в 2020 году.
Лучшее программное обеспечение для распознавания текста для Windows, MacOS и Linux
1. ABBYY FineReader
Когда дело доходит до оптического распознавания символов, вряд ли найдется что-то, что даже близко подходит к ABBYY FineReader. ABBYY FineReader позволяет загружать текст со всех видов изображений на одном дыхании.
Меня они бесят. Альтернатива программам Adobe | VMG ep 12
Несмотря на широкий набор функций, ABBYY FineReader очень прост в использовании. Он может извлекать текст практически из всех популярных форматы изображений, такие как PNG, JPG, BMP и TIFF. И это еще не все. ABBYY FineReader также может извлекать текст из файлов PDF и DJVU.
После загрузки исходного файла или изображения (которое предпочтительно должно иметь разрешение не менее 300 т / д для оптимального сканирования) программа анализирует его и автоматически определяет различные разделы файла, имеющие извлекаемый текст. Вы можете либо извлечь весь текст, либо выбрать только некоторые конкретные разделы. После этого все, что вам нужно сделать, это использовать опцию Сохранить, чтобы выбрать формат вывода, а ABBYY FineReader позаботится обо всем остальном. Поддерживаются многочисленные форматы вывода, такие как TXT, PDF, RTF и даже EPUB.
Программы для Windows, мобильные приложения, игры — ВСЁ БЕСПЛАТНО, в нашем закрытом телеграмм канале — Подписывайтесь:)
Выводимый текст является полностью редактируемым, и текст даже из самых содержательных документов (например, имеющих несколько столбцов и сложные макеты) извлекается безупречно. Другие функции включают в себя обширная языковая поддержка, многочисленные стили шрифтов / размеры и инструменты коррекции изображения для файлов, полученных из сканеров и камер.
Сказав все это, то, что отличает ABBYY FineReader от остальных программ, это его почти идеальная точность. С новым обновлением Finereader 15, теперь программное обеспечение использует AI для улучшения распознавания символов, AI особенно используется при извлечении текстов из документов, написанных на японском, корейском и китайском языках. Таким образом, если вы хотите получить абсолютно лучшее программное обеспечение для оптического распознавания текста с расширенными функциями, расширенным форматом ввода-вывода и поддержкой обработки, выберите ABBYY FineReader.
FineReader. Урок 2: Сканирование и подготовка к распознаванию простого текста
Доступность платформы: Windows и macOS
Цена: Платные версии начинаются с $ 199, доступна 30-дневная бесплатная пробная версия
2. Тессеракт
Тессеракт, пожалуй, самое мощное и передовое программное обеспечение для распознавания текста в этом списке, и я скажу вам почему. Прежде всего, немного истории. Он был разработан HP в 1994 году, но вскоре компания выпустила его под лицензией Apache для разработки с открытым исходным кодом. В 2006 году Google принял проект и спонсировал разработчиков для работы над Tesseract.
Перенесемся вперед, и Tesseract стал самым мощным Механизм распознавания текста, который использует Deep Learning для извлечения текстов из изображений (BMP, PNG, JPEG, TIFF и т. Д.) И файлов PDF., Существует множество онлайн-сервисов, которые используют OCR API Tesseract для распознавания и преобразования больших массивов изображений и файлов PDF. И самое приятное, что он доступен для всех основных операционных систем, включая Windows, macOS и Linux. Не говоря уже о том, что в отличие от ABBYY и Adobe, Tesseract совершенно бесплатно и вы можете использовать его для преобразования тысяч изображений в текст, не платя ни копейки.
Тем не менее, есть одна небольшая проблема. Tesseract не предлагает интерфейс с графическим интерфейсом. Вам придется использовать механизм OCR в командной строке, который не является чашкой чая для всех. Чтобы решить эту проблему, разработчики создали клиенты с графическим интерфейсом использование исходного кода Tesseract для различных операционных систем.
Я протестировал несколько из них и отсортировал лучшие клиенты Tesseract GUI для различных операционных систем. Если вы хотите быстро преобразовать изображения или PDF-файлы в редактируемый текст, используйте OCR Space (ссылка ниже) в веб-браузере. Это очень быстро и делает отличную работу. Если вы на Windows тогда используйте gImageReader; для Linux используйте OCRFeeder, а для macOS — PDF OCR X. Это все, но если вы хотите самостоятельно протестировать больше клиентов с графическим интерфейсом, перейдите к этому ссылка на сайт, Кроме того, если у вас есть опыт, то вы, конечно, можете использовать Tesseract в командной строке.
Доступность платформы: Интернет, Windows, macOS и Linux
Цена: Свободно
3. OmniPage Ultimate от Kofax
OmniPage Ultimate — это профессиональное программное обеспечение для преобразования ваших изображений (JPG и PNG), документов и PDF-файлов в цифровые файлы. Если у вас большая компания и вам нужно надежное программное обеспечение для распознавания текста, я очень рекомендую OmniPage Ultimate от Kofax. Однако для частных лиц это программное обеспечение будет слишком дорогим.
Что касается функций, OmniPage может точно оцифровывать изображения и документы, делая их одновременно редактируемыми и доступными для поиска. Он также поддерживает длинный список форматов изображений, поэтому независимо от расширения файла вы можете легко преобразовать его в любой формат файла, который вам нужен. С точки зрения возможностей, я бы сказал, это очень близко к ABBYY FineReader.
Кроме того, OmniPage Ultimate использует свою запатентованную технологию для определения макета изображений и автоматически поворачивает документ в правильной ориентации. Кроме того, вы можете запланировать большие объемы файлов PDF для пакетной обработки, используя инструмент автоматизации. Не говоря уже о том, что может обнаружить более 120 языков и может обрабатывать изображения и документы соответственно. Что касается форматов выходного файла, он поддерживает PDF, DOC, EXCL, PPT, CDR, HTML, ePUB и другие. Учитывая все вышесказанное, OmniPage Ultimate представляется надежным решением для оптического распознавания текста для корпоративных пользователей.
Доступность платформы: Windows
Цена: Бесплатная пробная версия на 15 дней, платная версия за 183 $
4. Readiris
В поисках чрезвычайно мощного программного обеспечения для оптического распознавания символов, которое имеет множество функций, но не требует ли много усилий, чтобы начать работу? Посмотрите на Readiris, так как это может быть именно то, что вам нужно.
Приложение профессионального уровня Readiris имеет обширный набор функций, который в значительной степени идентичен ранее обсуждавшемуся ABBYY FineReader. Readiris поддерживает несколько форматов изображений: от BMP до PNG и от PCX до TIFF. Кроме этого, PDF и DJVU файлы могут быть обработаны так же хорошо. Изображения могут быть получены из устройств сканера, и приложение также позволяет вам задавать пользовательские параметры обработки для исходных файлов / изображений, такие как сглаживание и регулировка DPI, перед их анализом. Хотя Readiris может обрабатывать изображения с более низким разрешением очень хорошо, оптимальное разрешение должно быть не менее 300 dpi.
Как только анализ завершен, Readiris определяет текстовые разделы (или зоны), и текст может быть извлекается из определенных зон или всего файла, Извлеченный текст доступен для редактирования и поиска и может быть сохранен в различных форматах, таких как PDF, DOCX, TXT, CSV и HTM.
Более того, облачная функция сохранения в Readiris Pro позволяет напрямую сохранять извлеченный текст в различные облачные службы хранения, такие как Dropbox, OneDrive, Google Drive и другие. Существует также множество полезных функций редактирования / обработки текста, и даже штрих-коды можно сканировать.
В общем, вы должны использовать Readiris, если хотите надежные функции извлечения / редактирования текста в простом в использовании пакете, в комплекте с обширной поддержкой формата ввода / вывода. Однако Readiris немного колеблется, когда дело доходит до обработки документов со сложными макетами, такими как несколько столбцов, таблиц и т. Д.
Доступность платформы: Windows и macOS
Цена: Платные версии начинаются с $ 49, доступна 10-дневная бесплатная пробная версия
5. Adobe Acrobat Pro DC
Если вы ищете мощное программное обеспечение для оптического распознавания текста для профессионального использования, я не могу рекомендовать Adobe Acrobat Pro DC. Так как это Adobe — создатель PDF и различных стандартов документов — компания имеет разработал мощный механизм распознавания текста для точного извлечения текстов из файлов PDF, имеющих отсканированные изображения.
Несмотря на то, что он не так многофункциональн, как ABBYY FineReader, Adobe Acrobat, безусловно, превосходит по уровню извлечения. Например, вы можете легко импортировать текстовые PDF-файлы в Adobe Acrobat, а затем использовать технологию распознавания текста для преобразования файла в редактируемый текст. Однако, если вы хотите выбрать изображение, то сначала вам нужно создать PDF-файл изображения, а затем только вы можете импортировать его. В этом отношении есть некоторые ограничения, но кроме этого, Adobe Acrobat является гораздо более мощным программным обеспечением для распознавания текста.
Сказав все это, лучшая часть этого программного обеспечения заключается в том, что оно сохраняет шрифт исходного документа, используя метод создания пользовательских шрифтов. Поскольку у Adobe есть огромный репозиторий фирменных обычных и дизайнерских шрифтов, он автоматически соответствует стилю шрифта исходного документа, а затем преобразует PDF в этот конкретный шрифт. И в случае, если нет доступного шрифта, то это создает собственный шрифт, используя похожую типографику, Это особенность, которую может использовать только Adobe. Проще говоря, если вы хотите конвертировать тысячи страниц отсканированных изображений в виде файлов PDF (например, книг), то Adobe Acrobat Pro DC — лучшее программное обеспечение для распознавания текста, которое вы можете выбрать.
Доступность платформы: Windows и macOS
Цена: Бесплатная пробная версия на 7 дней, платная версия начинается с $ 12.99 / месяц
6. Microsoft OneNote
OneNote — это впечатляющее многофункциональное приложение для создания заметок, с которым легко начать работу. Тем не менее, заметки не единственное, в чем они хороши. Если вы используете OneNote как часть вашего рабочего процесса, вы можете использовать его для основное извлечение текстаБлагодаря доброте OCR, встроенной в него.
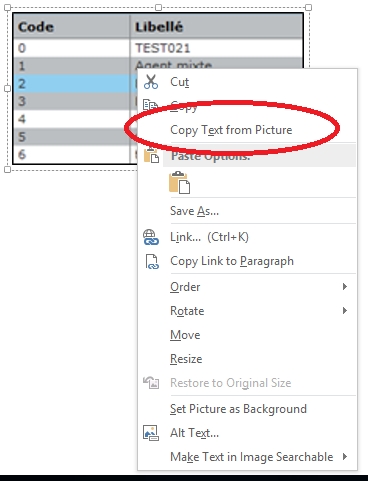
Использование OneNote для извлечения текста из изображений смехотворно просто. Если вы используете настольное приложение, все, что вам нужно сделать, это использовать Вставить Возможность добавить изображение в любой из блокнотов или разделов. Как только это будет сделано, просто щелкните правой кнопкой мыши на изображение и выберите Копировать текст с картинки вариант. Весь текстовый контент с изображения будет скопирован в буфер обмена и может быть вставлен (и, следовательно, отредактирован) куда угодно, согласно требованию. Будь то PNG, JPG, BMP или TIFF, OneNote поддерживает практически все основные форматы изображений.
Однако возможности OneNote по извлечению текста весьма ограничены, и он не может работать с изображениями, имеющими сложные макеты текстового содержимого, такие как таблицы и подразделы. Так что это то, что вы должны иметь в виду.
Доступность платформы: Windows и macOS
Цена: Свободно
7. Amazon Textract
В 2019 году Amazon запустила свое программное обеспечение для оптического распознавания текста Textract, которое имеет модель машинного обучения и обучено использованию миллионов документов. Он может автоматически определять печатный текст из изображений (JPG и PNG) и файлов PDF и отображать его в цифровом виде с почти идеальной точностью.
Хотя Textract в основном доступен в веб-браузере, вы также можете загрузить его и использовать службу через командную строку. Кроме того, Textract кажется довольно мощным программным обеспечением для распознавания текста. он может извлекать не только тексты, но также таблицы, поля, числа и ключевые значения. Мне особенно нравится извлечение таблиц из отсканированных изображений, так как это может упростить процесс редактирования текста. Textract хранит данные таблицы, используя предопределенную схему, где он извлекает все данные в виде строк и столбцов.
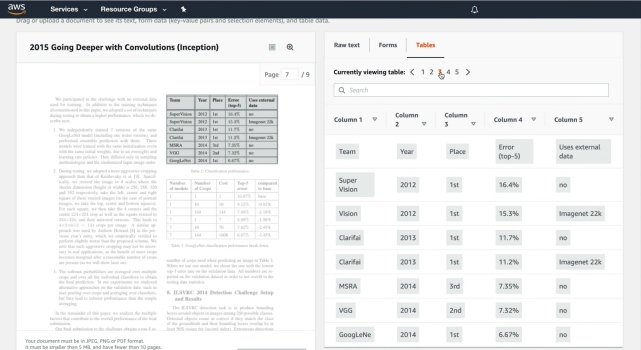
Сказав все это, Amazon Textract предлагает свои услуги как для частных лиц, так и для предприятий. Как домашний пользователь, вы можете зарегистрировать бесплатную учетную запись уровня AWS и использовать эту услугу, но имейте в виду, что вы можете конвертировать только 1000 страниц в месяц. В целом, Amazon Textract делает отличное программное обеспечение для распознавания текста и может использоваться как обычными пользователями, так и предприятиями.
Доступность платформы: Интернет, Windows, macOS, Linux
Цена: Бесплатно в течение первых 3 месяцев, Премиум план начинается с $ 1,50 за 1000 страниц
8. Документы Google
Не многие знают, что в Документах Google есть скрытая функция распознавания текста. Да, вы правильно прочитали, и вам не нужна учетная запись G Suite для использования этой функции. Конечно, это не самый простой подход, но для обычных пользователей, которые хотят конвертировать PDF файлы в редактируемый текст бесплатно тогда Google Docs — лучший, без исключения.
Все, что вам нужно сделать, это загрузить файл PDF на Google Drive. После этого щелкните его правой кнопкой мыши и перейдите к параметру «Открыть с помощью». Наконец, нажмите на Google Docs, и все готово. Теперь файл PDF откроется в Google Docs и автоматически преобразует его в редактируемый текст в течение нескольких секунд. Как это круто?
Теперь вы можете редактировать весь текст, искать его, редактировать и, наконец, сохранять файл в нескольких форматах, которые изначально поддерживаются Документами Google. В моем тестировании это работало довольно хорошо для файлов PDF которые были созданы с помощью текстовых процессоров. Однако имейте в виду, что он не может конвертировать изображения или отсканированные изображения в виде файлов PDF. Итак, если вам нужен бесплатный и простой инструмент OCR для преобразования PDF-файлов в редактируемый текст, Google Docs предоставит вам все необходимое.
Доступность платформы: Интернет, Windows, macOS, Linux
Цена: Свободно
Все готово для преобразования изображений и PDF-файлов в текст?
Оцифровка печатного и рукописного текстового содержимого чрезвычайно полезна, поскольку делает хранение, редактирование и обмен чрезвычайно легкими. И вышеупомянутое программное обеспечение для распознавания текста делает быструю работу по выполнению именно этого, независимо от того, насколько сложны или сложны ваши потребности в извлечении текста.
Нужны функции извлечения текста профессионального уровня с лучшими инструментами пост-обработки? Перейти на ABBYY FineReader, Tesseract или OmniPage. Вы бы предпочли более простое программное обеспечение для оптического распознавания текста, которое только делает основы? Используйте OneNote или Google Docs. Попробуйте их, и посмотрите, как они работают для вас.
Знаете ли вы о каком-либо другом программном обеспечении OCR, которое могло бы быть включено в приведенный выше список? Кричите в комментариях ниже.
Источник: okdk.ru
ВОЗМОЖНОСТИ ПРОГРАММЫ FINEREADER
Основным назначением глобальных вычислительных сетей является обеспечение удобного, надежного доступа пользователя к территориально распределенным общесетевым ресурсам, базам данных, передаче сообщений. Для организации электронной почты, телеконференций, электронной доски объявлений, обеспечения секретности передаваемой информации в различных глобальных сетях используются стандартные (в этих сетях) пакеты прикладных программ.
В качестве примера можно привести программное обеспечение для глобальной сети Интернет:
• средства доступа и навигации — Netscape Navigator, Microsoft internet Explorer;
• почтовые программы для электронной почты (e-mail). Наиболее распространенными в настоящее время являются MS Outlook Express, The Bat, Eudora и почтовая программа из пакета Netscape Communicator — Netscape Messenger.
В банковской деятельности широкое распространение получили стандартные пакеты прикладных программ, обеспечивающие подготовку и передачу данных в международных сетях Swift, Sprint, Reuters. Организации сетей и сетевому программному обеспечению посвящены гл. 13, 14.
Прикладное программное обеспечение
Для организации (администрирования)
вычислительного процесса.
Для этих целей в локальных и глобальных вычислительных сетях более чем в 50 % систем мира используется ППП фирмы Bay Networks (США), управляющий администрированием данных, коммутаторами, концентраторами, маршрутизаторами, трафиком сообщений.
Итак, мы кратко ознакомились с базовым и прикладным программным обеспечением, обеспечивающим как работу самого компьютера, так и деятельность специалиста — пользователя компьютера в своей профессиональной сфере.
На практике иногда встречаются оригинальные задачи, которые нельзя решать имеющимися прикладными программами. В этом ; случае результаты получаются в форме, не удовлетворяющей конечного пользователя. Тогда с помощью систем программирования или алгоритмических языков разрабатываются оригинальные программы, учитывающие требования и условия решения конкретных задач организации.
СИСТЕМЫ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ ИНФОРМАЦИИ
В практической деятельности часто встречаются ситуации, когда необходимо перевести в электронный вид документ, напечатанный на бумаге. В этом случае можно просто набрать документ на компьютере, что довольно трудно, либо воспользоваться сканером — устройством, специально предназначенным для перевода документов в электронный вид. Для организации сканирования изображения помимо непосредственно сканера требуется одна из специальных программ систем оптического распознавания текста.
Системы оптического распознавания текста (Optical Character Recognition — OCR-системы) предназначены для автоматического ввода печатных документов в компьютер.
Современные программы распознавания текста не только ошибаются реже, чем живой человек, но и обеспечивают проверку орфографии, автоматическое форматирование текста и массу других дополнительных удобств.
Последние годы ведущие позиции на российском рынке «распознавалок» удерживают программы FineReader и CuneiForm. Несмотря на свои замысловатые названия, обе программы отечественного производства вполне хорошего качества. По своим возможностям и сервису они примерно равноценны.
ВОЗМОЖНОСТИ ПРОГРАММЫ FINEREADER
Одной из популярных программ оптического распознавания текстов является программа FineReader, созданная компанией ABBYY Software House.
FineReader — омнифонтовая система оптического распознавания текстов. Это означает, что она позволяет распознавать тексты, набранные практически любыми шрифтами. Особенностью программы FineReader является высокая точность распознавания и малая чувствительность к дефектам печати, что достигается благодаря применению технологии «целостного целенаправленного адаптивного распознавания».
Программа позволяет распознавать с высокой точностью тексты более чем на 175 языках, выводить на печать исходное изображение и распознанный текст, сохранять отсканированное изображение в различных форматах, настраивать панели инструментов программы, а также отвечает требованиям совместимости сновыми операционными системами Microsoft и Macintosh. Версия программы FineReader 6.0 Professional совместима с Windows-2000, -ХР, a FineReader 5.0 Pro for Mac предназначена для владельцев компьютеров Apple Macintosh.
Кроме того, отсканированный файл можно сразу же отправить электронным письмом или загрузить в браузер в виде Web-странички.
Программа FineReader, начиная с третьей версии, оказалась настолько удачной, что завоевала широкое признание и в России, и за ее пределами. Именно в связи с выходом на мировую арену фирма получила свое новое имя ABBYY, ранее называясь Bit Software.
Программные продукты ABBYY FineReader представлены в настоящее время следующими программами: FineReader Sprint, FineReader 6.0 Professional, FineReader 6.0 Corporate Edition и ABBYY FineReader 5.0 Pro for Mac.
FineReader Sprint поставляется в комплекте со сканерами. Это продукт для тех, кто только начинает работать с системами распознавания OCR. Версия обладает ограниченной функциональностью по сравнению с версиями Professional и Corporate Edition.
FineReader 6.0 Corporate Edition разработана с учетом запросов корпоративных клиентов и поддерживает такие функции, как работа в локальной сети, пакетный поиск и индексирование, распознавание штрих-кодов и разбивка изображений. FineReader Scripting Edition позволяет создавать интегрированные решения, обладающие всеми возможностями Corporate Edition.
Интерфейс программы ABBYY FineReader 5.0 Pro for Mac, включая панели управления, пиктограммы и диалоговые окна, создавался непосредственно для Mac OS. Поддержаны все основные технологии Apple, включая QuickTime, Speech, Drag and Drop и Navigation Services. Продукт разработан компаниями ABBYY Software House и Sound
• операционная система Microsoft Windows XP/2000/NT 4.0 (SP6 или выше), Windows ME/98/95 (для работы с локализованным интерфейсом операционная система должна обеспечивать необходимую языковую поддержку);
• размер оперативной памяти для Windows ХР/2000 — 64 Мбайт, Windows ME/98/95/NT 4.0 — 32 Мбайт;
• 160 Мбайт свободного места на жестком диске, включая 90 Мбайт для установки системы в минимальной конфигурации и 70 Мбайт для работы системы;
• браузер Microsoft Internet Explorer 5.0 или выше (на компакт-диске находится дистрибутив MS IE 5.5);
• 100%-й Twain-совместимый сканер, цифровая камера или факс-модем;
• дисковод для компакт-дисков;
• дисковод 3,5 дюйма или возможность произвести активацию продукта через Интернет, по электронной почте или по телефону.
Это интересно
FineReader работает с более чем 30 моделями TWAIN-совместимых сканеров таких компаний, как Hewlett-Packard, Canon, Epson, Microtek.
Мастер установки FineReader предельно прост — пользователю предлагается выбрать язык интерфейса, вариант установки и каталог для файлов программы. Для инсталляции на диске должно быть свободно 90 Мбайт. Для удаления программы из компьютера имеются средства деинсталляции.
ТЕХНОЛОГИЯ РАСПОЗНАВАНИЯ
Сложность машинного распознавания текстов заключается в том, что его невозможно построить по жесткому алгоритму хотя бы потому, что для написания одной и той же буквы существует множество вариантов написания. Значит, чтобы компьютер корректно прочитал символы, он должен их «осмыслить».
Иными словами, для распознавания текста требуется моделирование рассуждений человека в подобной ситуации, а это принято обозначать термином «искусственный интеллект».
Это интересно
Технология распознавания, используемая FineReader, базируется на принципах целостности, целенаправленности и адаптивности.
Впервые они были сформулированы и применены на практике в конце 80-х гг. XX в. А.Шамисом в системе распознавания «Графит».
Исходя из принципа целостности распознаваемое изображение рассматривается как единый объект, состоящий из частей, связанных между собой пространственными соотношениями. По принципу целенаправленности распознавание строится как процесс выдвижения и целенаправленной проверки гипотез об объекте, а принцип адаптивности подразумевает способность системы к самообучению.
Каким образом строится распознавание символов?
Для выдвижения гипотез о том, что может представлять собой изображение, применяются так называемые признаковые классификаторы. Они используют ряд признаков, на основе которых программа вычисляет степень близости распознаваемого изображения и известных ей классов изображений, после чего выдает список подходящих классов, т. е. гипотезу о принадлежности объекта к тому или иному классу. Кроме того, признаковые классификаторы применяются также и для повышения точности распознавания изображений с дефектами.
Полученный набор классов последовательно проверяется структурным классификатором, анализирующим каждый символ. Скажем, если FineReader полагает, что на странице изображена буква «Ф», он специально проверяет те признаки, которые должны быть именно у буквы «Ф», а не у какой-либо другой, сравнивая этот символ со структурным эталоном. Структурный эталон описывает символ как комбинацию структурных элементог (отрезок, дуга, кольцо, точка), находящихся в определенных отношениях между собой. Процесс распознавания делится на этапы выделения структурных элементов в изображении и сопоставлении их с эталоном.
Если в окончательный список попало более одной гипотезы, они попарно сравниваются с помощью дифференциальных классификаторов. Если структурный классификатор при распознавании символов не может однозначно выбрать одну из двух букв с похожим написанием, то между этими конкурирующими гипотезами делается дифференциальный выбор. Например, есть две гипотезы: распознаваемый символ представляет собой строчную букву «твердый знак» или «мягкий знак». Чтобы сделать выбор, FineReader целенаправленно проанализирует левый верхний угол буквы, где имеется единственная отличительная деталь между этими буквами.
С завершением работы дифференциального классификатора заканчивается распознавание и начинается этап проверки итогового списка гипотез. Окончательная стадия распознавания осуществляется системой контекста — при наличии некоторого количе-
ства распознанных букв из слова программа, используя словарь, может «догадаться», что это за слово.
Базовые принципы целостности, целенаправленности и адаптации остаются неизменными от версии к версии программы FineReader, ведь именно они позволяют компьютеру приблизиться к логике мышления человека.
Источник: www.megapredmet.ru
ABBYY FineReader с таблеткой (ключом)
ABBYY FineReader скачать Professional Edition бесплатно
Программа для оптического распознавание текста. FineReader является самой продвинутой программой, которая использует оптическое распознание символов во время сканирования текста на фотографиях.
Программа поддерживает множество языков, и сможет отсканировать с фотографии и перевести в текстовый формат даже плохо читаемый текст, с возможностью дальней его корректировки и сохранения в текстовом документе. Программой ABBYY FineReader Поддерживается сто сем десять девять языков которые распознаются, экспортируйте свои документы в Excel/Word/Outlook и PowerPoint, сохраняй в формат HTML, PDF и LIT на компьютере. Программа платная, но мы выкладываем ее с ключом активации так как не все могут позволить сей продукт платным. Программа подойдет как для дома так и для офиса.
| Для простой установки рядовому пользователю достаточно FineReader скачать и запустить бесплатно ABBYY FineReader 11.0.110.122.exe и после выбрать вариант установки как показано на картинке справа. Если выберите автоматический вариант установки, установка произойдет в автоматическом режиме после найдете значок на панели задач или иконку на рабочем столе! | 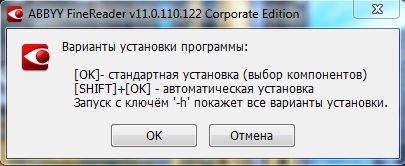 |
Дополнительная информация по файлам в архиве (читать обязательно)
После того как вы нажали скачать бесплатно FineReader в архиве будут находится файлы которые могут быть не понятны, но вот их расшифровка:
(_russian_std.cmd) стандартная установка (русская версия интерфейса)
(_russian_silent.cmd) автоматическая установка (русская версия интерфейса)
(_english_std.cmd) стандартная установка (английский интерфейс)
(_english_silent.cmd) автоматическая установка (английский интерфейс)
(_uninstall.cmd) автоматическое удаление пакета repack’a»
(_help.cmd) отображает весь выше список ключей (для установки через командную строку)
Наименование: ABBYY FineReader 11 Professional Edition
Распространение: Таблетка внутри (бесплатно) или ключ сдесь
Перевод: Русская версия
ОСь: все Windows
Применение языкового пакета в ABBYY FineReader (Languages)
По умолчанию если устанавливать, то установка на русском языке и прекрасно распознаются русские документы если нужны доп. языковые пакеты для распознавания других языков следует запустить комплект* языков «Languages.exe».
Распаковка языков выполняется в %ProgramFiles%\ABBYY FineReader 11ExtendedDictionaries (для x86)
или %ProgramFiles(x86)%\ABBYY FineReader 11ExtendedDictionaries (для x64)
ABBYY FineReader 11 скачать бесплатно с ключом:
Вес программы: 65мб после распаковки (максимальная скорость загрузки!)
Bin.cab а так же DictLang.cab распакованы для лучшего сжатия дистрибутива!
Источник: keyprogram.me