

Мы строили-строили и, наконец, построили!
Как понятно из названия, мы недавно обрелизились. В связи с этим под катом постараемся простым русским языком объяснить, чем хорош FineReader 12, чтобы те, кому он нужен, могли понять, бежать уже сейчас в онлайн-магазин за новой версией или спокойно ждать пару лет появления счастливой тринадцатой.
Про интерфейс

Начну с того, что обязательно бросится в глаза пользователям старых версий. То есть с интерфейса. Нет, мы не достигли идеала, как на левой картинке, но планомерно к нему двигаемся. Очередными шагами в этом движении стали фичи с внутренними именами «немодальность» и «быстрое открытие».
Если в FineReader 11 (и, конечно, более старых версий) вбросить документ на k страниц, то тот задумается на n секунд, прежде, чем в нём можно будет сделать что-нибудь полезное руками. На все эти n секунд за дело возьмутся наши технологии, не желая делиться с пользователями доступом к страницам.
ABBYY FineReader 12 активация-Crack
В 12 версии, для начала, добавленные страницы пользователь увидит сразу . А самое главное, что возможность править блоки/делать специальные ручные предобработки изображений при наличии такой необходимости (возникает она обычно, когда на входе плохой, негодный, без преувеличения страшный документ) появляется мгновенно . Более того, в это время распознавание уже может идти. Короче, почти все наши механизмы могут работать одновременно с пользователем, чтобы последний не терял время на ожидание. Непокорёнными вершинами на пути к полной немодальности остались процессы, которые у нас зовутся документным синтезом и экспортом. Особенность этих процессов в том, что они обрабатывают документ целиком, а не постранично, поэтому работать параллельно с пользователем никак не могут. Однако, эти процессы от общего времени занимают обычно меньше 10%, да и происходят на последних этапах, когда пользователь, скорее всего, уже сделал всё, что хотел.

Кроме того, в новой версии предусмотрен сценарий цитирования. Он предполагает, что пользователю нужен не весь документ в виде файла(/-ов), а только отдельные его куски для дальнейшего их копипащения куда-нибудь.
Честно говоря, если в вашей обычной работе речь идёт о цитировании одного-двух абзацев, то я бы рекомендовал использовать наш Screenshot Reader (кстати, он не только продаётся отдельно, но и входит в состав FineReader в виде бонуса). Однако, если из 100-страничного документа надо получить 15 конкретных абзацев, то новая фича будет как нельзя кстати. Ощутимым плюсом в таком сценарии будет то, что FineReader вполне прилично выделяет блоки, а значит, остаётся только найти нужную страницу и нажать Copy на целевом блоке. Если у вас не Pentium 3, а что-нибудь посвежее, то, скорее всего, дело займёт не больше секунды.
Справку мы теперь держим в онлайне. Продукт, как справедливо заметил aram_pakhchanian, нашпигован возможностями, а это очевидным образом обязывает справку быть точной и актуальной. Онлайновость тут — идеальный выход: сегодня тестируем встраивание доперевода, а завтра любой пользователь уже пользуется актуализированной информацией.
Кроме того, у нас теперь есть механизм автообновления. Конечно же, скачивать придётся не целый дистрибутив, а только патч (единицы мегабайт). FineReader сам всё сделает, разве что уточнит, хочет ли пользователь обновиться.
Я, вообще-то тестированием занимаюсь, поэтому продукт вижу уже давно и, честно говоря, даже не знаю, что ещё добавить — привык я уже к его новому виду и новым фичам. В связи с этим вот вам обзор на 3dnews, а я передаю микрофон 57ded, который поведает о том, почему качество распознавания растёт с 98% уже много лет на 30-40% в продуктовый цикл, но всё ещё не достигло 200%.
Про технологии

Про новые или хорошо забытые старые функции обработки изображений всё понятно. С одной стороны, мы, наконец, сделали удаление цветных печатей на офисных документах как на картинке справа, что, IMHO, вполне приемлемо и соответствует нынешнему уровню достижений науки и технологий.
С другой стороны сдули толстый слой нафталина с функций восстановления баланса белого и прочего «визуального улучшения» изображения, впервые представленных ещё в далёком 2007 в рамках FineReader 8. Помимо этого официально объявлено об улучшении работы на документах с таблицами и диаграммами. Насчёт диаграмм замечу, что, скорее всего, здесь к диаграммам из-за какого-то то ли недоразумения, то ли нежелания разбираться в деталях, отнесли документы с картинками, где на картинке был скриншот – эту-то задачу мы как раз решали целенаправленно.
Как гласит анонс FineReader’ а (ссылку давать не будем, анонсам тут не место, правда) достигнуты улучшения в “up to” 33% на диаграммах со скриншотами и «до» 40% на таблицах. Ни один нормальный заинтересованный скептик не пропустит просто так эти цифры, потому поясним, откуда они взялись. Капитан Очевидность подсказывает, что точность распознавания обычно меряют, сравнивая результат работы программы OCR с неким эталоном «как должно быть». Если мы меряем точность распознавания текста, когда уже известно, где именно этот текст расположен (задача, пленяющая многих своих красотой и так и зовущая применить всю мощь теории классификаций), то измерить, насколько результат близок к оригиналу, не представляет вообще никаких проблем.
Для задачи выделения текстовых зон так просто результат померить не получится: к примеру, потому, что можно как объединять текст и заголовок к нему в один блок, так и делать на этом два текстовых блока. Сейчас в мире многим нужно измерить качество работы выделителя текстовых зон, все меряют немного по-разному, но общая идея очень проста.
В эталоне храним все таблицы, тексты и картинки на страницы. Следим, чтобы в результатах распознавания таблицы и картинки оказались на месте, а текст оказался внутри текстовых зон. И далее разными хитрыми способами запрещаем разное нехорошее. Скажем, нельзя объединять две колонки в один блок (потеряется порядок чтения), нельзя разрывать строки посерёдке и отрывать буквицу от текста (по той же причине), не надо объединять в один блок чёрный текст на белом фоне и белый на чёрном.
Теперь, чтобы померить точность для таблиц и диаграммо-скриншотиков, осталось всего ничего: посмотреть, сколько таблиц не находила предыдущая версия, сравнить с количеством таблиц, с которыми не справилась нынешняя, «недостачу» таблиц прошлой версии принять за 100% и получить искомый результат… Упс…, снова не всё так просто.
Во-первых, таблицу нужно не просто найти, её нужно разметить на ячейки. Когда границы ячеек никак не обозначены, это становится непростой задачей. Но, как мы уже упоминали, значительного прогресса здесь мы достигли ещё в прошлой версии, так что в нынешней мы могли позволить себе двигаться «по инерции». Кстати, измерить качество разделения таблиц на ячейки – довольно простая задача. Как правило, можно твёрдо сказать, есть ли в данном месте граница ячеек или нет, так что для оценки качества FineReader’а требуется посчитать количество недостающих границ ячеек и добавить количество излишних.
На самом деле
потерю границы между столбцами таблицы следует считать более значимой ошибкой, чем случайное деление одной ячейки в заголовке таблицы, так что мы считаем именно что границы каждой ячейки – то есть вес вертикального разделителя равен количеству ячеек, которые он делит.
Во-вторых, довольно сложно разметить достаточно большую базу изображений. Немного поясним здесь, в чём именно трудность. Предположим, мы разметили одну страницу из какого-то документа. На ней размещено хорошо если одна табличка, может быть пара картинок и довольно много текста.
Для измерения точности распознавания мы получим несколько тысяч символов и сотни слов, а для задачи поиска таблиц – да, всего одну таблицу. Вряд ли здесь имеет смысл дальше ныть на тему, как всё непросто, вы уже и сами всё поняли.
В-третьих (вы что, всерьёз полагаете, что загвоздки у меня уже кончились?), в некоторых случаях человечество не может точно сказать, таблица перед нами, или текст. Скажем, как на картинке справа.
В таких случаях примем соломоново решение «И так, и так правильно».
Применив упомянутое колдунство, мы пришли к выводу, что на нашей базе…
«Стоп!» — справедливо возмутится любой оппонент, — «Использовать обучающую базу в качестве тестовой – это за гранью добра и зла. ». Что ж, придётся с ним согласиться. Действительно, сравнительное тестирование нужно проводить на совершенно новой базе свежескачанных или свежеотсканированных изображений, чтобы была гарантия, что программисты на них и не пытались настроиться. Но тут-то как раз мы и вспоминаем, что размечать эту базу недёшево. Пока что решение состоит в следующем:
- Уж какую смогли базу, ту и приспособили для честного тестирования;
- Точно измерить цифры улучшения не получится – так и пишем «улучшили на треть» или «улучшили на две пятых» — что в маркетинговых материалах превращается в 30-33-40 % (иногда мне кажется, что их авторы соревнуются в частоте употребления слова «процент»). Оттуда и наши стыдливые «до» или “up to”.
- Но зато раз уж база маленькая – можем провести «субъективный» тест – глазами просмотреть эту пару сотен изображений и сказать, какая из версий лучше на них отработала. Упомянутые цифры нашли субъективное подтверждение, что укрепляет нас в уверенности, что это правда.
На этом разрешите откланяться, предложив на прощание ознакомиться с триалом нашего чудо-продукта.
Источник: habr.com
ABBYY FineReader 12.0.101.496 Professional Сохранение структуры и форматирования документа;
Поддерживаемые форматы файлов:
- Входные форматы файлов: BMP; PCX; DCX; JPEG; JPEG 2000; JBIG2; PNG; TIFF; PDF; XPS*; DjVu; GIF;
- Сохранение в документах: DOC, DOCX; XLS, XLSX; PPTX; RTF; PDF, PDF/A; HTML; CSV; TXT; ODT; EPUB; FB2; DjVu;
- Сохранение в изображениях: BMP; TIFF; PCX; DCX; JPEG; JPEG 2000; JBIG2; PNG.
Интеграция с другими приложениями

- Microsoft Word 2003 (11.0), 2007 (12.0), 2010 (14.0) и 2013 (15.0);
- Microsoft Excel 2003 (11.0), 2007 (12.0), 2010 (14.0) и 2013 (15.0);
- Microsoft PowerPoint 2003 (11.0) (с использованием Microsoft Office Compatibility Pack для форматов Word, Excel и PowerPoint 2007), 2007 (12.0), 2010 (14.0) и 2013 (15.0);
- Apache OpenOffice 3.4, 4.0;
- Corel WordPerfect X5, X6;
- Adobe Acrobat/Reader (8.0 и позднее).
Видеообзор ABBYY FineReader
Источник: shelmedia.ru
ABBYY FineReader 12 русская версия c ключом

Сканирование и распознавание бумажных документов по-прежнему является актуальной задачей. Качественно оцифровать текст позволяют профессиональные приложения. Одним из таких является «герой» данного обзора. У нас вы можете ознакомиться с возможностями и процедурой установки программы. Также в конце страницы можно бесплатно скачать русскую версию ABBYY FineReader 12 Professional Rus вместе с ключом для активации.
Описание и возможности
Разберем функционал программного обеспечения, который позволит вам получать максимально качественный результат:
- автоматический захват изображения со сканера, веб-камеры, фотоаппарата;
- распознавание содержимого сохраненных файлов;
- преобразование в файлы популярных текстовых и мультимедийных форматов;
- создание шаблонов для распознавания документов с одинаковым расположением контента;
- отправка готовых документов в текстовые редакторы;
- выделение области для распознавания отдельных блоков;
- создание и редактирование эталонов;
- обработка изображений (цветокоррекция, обрезка, отражение и так далее).
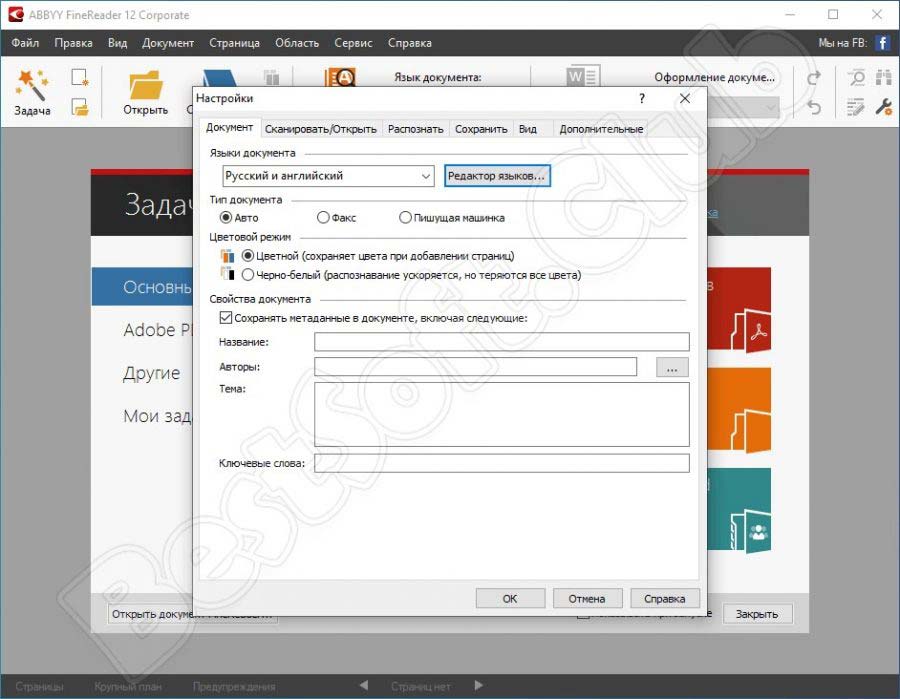
Приложение используется во многих сферах деятельности. Например, для оцифровки старых документов, создания электронных книг, сканирования фотографий в высоком разрешении.
Как пользоваться
Чтобы вам было проще разобраться с установкой и использованием, мы кратко рассмотрим данные операции.
Загрузка и установка
Сначала перейдите к концу страницы и скачайте torrent-файл программы. Загрузите архив вместе с установщиком и Crack-файлом, затем распакуйте их на жесткий диск. Чтобы установить софт, выполните ряд простых действий:
- Запустите инсталлятор и выполните начальные шаги по инструкции.
- На этапе выбора директории оставьте параметры по умолчанию!
- Дождитесь окончания процедуры и закройте установщик.
Если ранее вы искали того, кто может подсказать серийный ключик, или подумывали купить лицензию, то теперь вам достаточно следовать инструкции:
- После установки не запускайте приложение. Скопируйте активатор в корневой каталог.
- Запустите кряк через режим с правами администратора.
- Нажмите кнопку Patch и подождите некоторое время.
- После сообщения об успешной активации закройте приложение.
Теперь на вашем компьютере стоит крякнутый ABBYY FineReader 12 Pro, который уже не потребует от вас ввода лицензионного кода.
Инструкция по работе
Разберемся, как пользоваться софтом для распознавания:
- Выберите источник. Можно загрузить сохраненное изображение или подключить сканер. В первом случае качество будет выше.
- Проведите распознавание всего документа или выделенной области. Программа найдет картинки, текст и другие элементы.
- Проверьте, что нужно отредактировать или удалить с помощью встроенных инструментов.
- Конвертируйте итоговый результат в нужный формат. Это может быть DOCX, XLS, PPTX, PDF, TXT, FB2, BMP, JPEG и другие разрешения в зависимости от распознанного контента.
Достоинства и недостатки
Положительные и отрицательные стороны помогут определиться с выбором софта для сканирования и распознавания.
- интерфейс на русском языке;
- имеется portable-версия;
- поддержка большинства форматов изображений и текстовых документов;
- удобный редактор для обработки текста;
- прямой захват с устройства чтения изображений;
- выбор области захвата вручную;
- высокая скорость обработки;
- множество языковых пакетов для распознавания.
- множество тонких настроек, в которых сложно разобраться новичку.
Похожие приложения
Если вас не устраивает ABBYY FineReader 12, то присмотритесь к следующим аналогам:
- CuneiForm;
- SimpleOCR;
- Img2txt;
- VueScan;
- Scanitto Pro.
Системные требования
Для работы с программой потребуется приблизительно следующий компьютер:
- Центральный процессор: Intel или AMD с частотой 1 ГГц или выше;
- Оперативная память: от 1 Гб;
- Пространство на жестком диске: от 850 Мб;
- Платформа: Microsoft Windows x32/x64.
На вашем компьютере должна быть установлена актуальная версия .NET Framework и фирменные драйвера для эксплуатации сканера!
Скачать
Кликнув на кнопку внизу, вы скачаете торрент-файл для загрузки инсталлятора ABBYY FineReader 12 вместе с активатором. После использования кряка вы получите бессрочную лицензию на софт.
| Версия: | 12.0.101.264 |
| Разработчик: | ABBYY Software |
| Год выхода: | 2014 |
| Название: | ABBYY FineReader 12 Professional Edition |
| Платформа: | Microsoft Windows XP, Vista, 7, 8.1, 10 |
| Язык: | Русский, Английский |
| Лицензия: | Платно (можно активировать кряком или лицензионным ключом) |
| Пароль к архиву: | bestsoft.club |
Видеообзор
Предлагаем ознакомиться с видеороликом, в котором показываются основные функции софта в действии.
Вопросы и ответы
Скачивайте программу для распознавания документов без регистрации с нашего портала и пользуйтесь без ограничений! Мы ответим на все вопросы по поводу ошибок или трудностей в работе. Пишите комментарии к статье с помощью специальной формы.
Источник: bestsoft.club
ABBYY FineReader 12.0.101.388

ABBYY FineReader 12 Professional – это одна их лучших программ, которая предназначена для распознавания текста, а также с возможностью перевода изображений документов и любых типов PDF файлов в электронные редактируемые форматы. FineReader имеет возможность восстанавливать структуру документа в его электронной копии.

Скачать программу ABBYY FineReader 12 Professional бесплатно можно по ссылкам ниже:
ABBYY_FineReader_12.zip [402,22 Mb] Пароль к архиву: 123
Источник: softomania.net