
Текстовая информация представляет собой набор символов, которыми могут быть буквы, цифры, знаки препинания. В компьютерной технике символы закодированы с помощью чисел, каждый символ кодируется своим набором цифр — кодом.
Существуют специальные таблицы кодировок, в которых хранятся такие наборы кодов символов.
Кодовая таблица — это представление символов в компьютерной технике на внутреннем уровне.
Базой для компьютерных стандартов кодирования является кодировка ASCII . Однако этот стандарт рассчитан на передачу текстовой информации, которая состоит из букв английского алфавита. Таблица ASCII -кодов состоит из двух частей: стандартная (содержит коды от (0) до (127)) и расширенная (содержит символы с кодами от (128) до (255)).
Для русского языка используют чаще всего однобайтовые кодовые таблицы КОИ-(8) , CP-(866) , Windows-(1251) , ISO (8859)-(5) . Первые (128) символов идентичны с таблицей ASCII-кодов , следующие символы (с (128) по (255)) предназначены для русских букв.
Указатели символьные строки и функции. Строки и указатели в c++. C ++ Для начинающих. Урок #63
Стандарт Unicode кодирует все алфавиты современных, мёртвых и вымышленных языков. Современная компьютерная техника и операционные системы работают на базе (16)-битной версии Unicode.
Форматы текстовых файлов
Наиболее распространённый и простой формат текстовых файлов:
Усовершенствованный формат, который позволяет хранить форматирование:
Для документов Microsoft Word:
Позволяет работать с презентациями, формами, анимацией, аудио и видео:
Для документов OpenOffice:
Для чтения электронных книг:
- .fb2;
- .djvu;
- .mobi;
- .epub.
Источник: www.yaklass.ru
Урок 12
Представление нечисловой информации в компьютере

— как в компьютере представляется текстовая информация;
— что такое ASCII и Unicode;
— как в компьютере представляется графическая информация;
— какие форматы используются при хранении графических файлов;
— как в компьютере представляется звуковая информация;
— какие форматы используются при хранении звуковых файлов.
Компьютеры не с самого рождения могли обрабатывать символьную информацию. Лишь с конца 60-х годов они стали использоваться для обработки текстов и в настоящее время большинство пользователей ПК занимаются вводом, редактированием и форматированием текстовой информации.
1. Таблица кодирования ASCII.
А теперь «заглянем» в память компьютера и разберемся, как же представлена в нем текстовая информация.
Текстовая информация состоит из символов: букв, цифр, знаков препинания, скобок и других. Мы уже говорили, что множество всех символов, с помощью которых записывается текст, называется алфавитом, а число символов в алфавите — его мощностью.
С++: лабораторная — решение задач на строки (класс string)
Для представления текстовой информации в компьютере используется алфавит мощностью 256 символов. Мы знаем, что один символ такого алфавита несет 8 битов информации: 2 в 8 степени равно 256. 8 битов = 1 байт, следовательно:
Один символ в компьютерном тексте занимает 1 байт памяти.
Как мы выяснили, традиционно для кодирования одного символа используется 8 бит. И, когда люди определились с количеством бит, им осталось договориться о том, каким кодом кодировать тот или иной символ, чтобы не получилось путаницы, т.е. необходимо было выработать стандарт – все коды символов сохранить в специальной таблице кодов. В первые годы развития вычислительной техники таких стандартов не существовало, а сейчас наоборот, их стало очень много, но они противоречивы. Первыми решили эти проблемы в США, в институте стандартизации. Этот институт ввел в действие таблицу кодов ASCII (AmericanStandardCodeforInformationInterchange – стандартный код информационного обмена США).
Рассмотрим таблицу кодов ASCII.
Пояснение: раздать учащимся распечатанную таблицу кодов ASCII.
Таблица ASCII разделена на две части. Первая – стандартная – содержит коды от 0 до 127. Вторая – расширенная – содержит символы с кодами от 128 до 255.
Первые 32 кода отданы производителям аппаратных средств и называются они управляющие, т.к. эти коды управляют выводом данных. Им не соответствуют никакие символы.
Коды с 32 по 127 соответствуют символам английского алфавита, знакам препинания, цифрам, арифметическим действиям и некоторым вспомогательным символам.
Коды расширенной части таблицы ASCII отданы под символы национальных алфавитов, символы псевдографики и научные символы.
Стандартная часть таблицы кодов ASCII
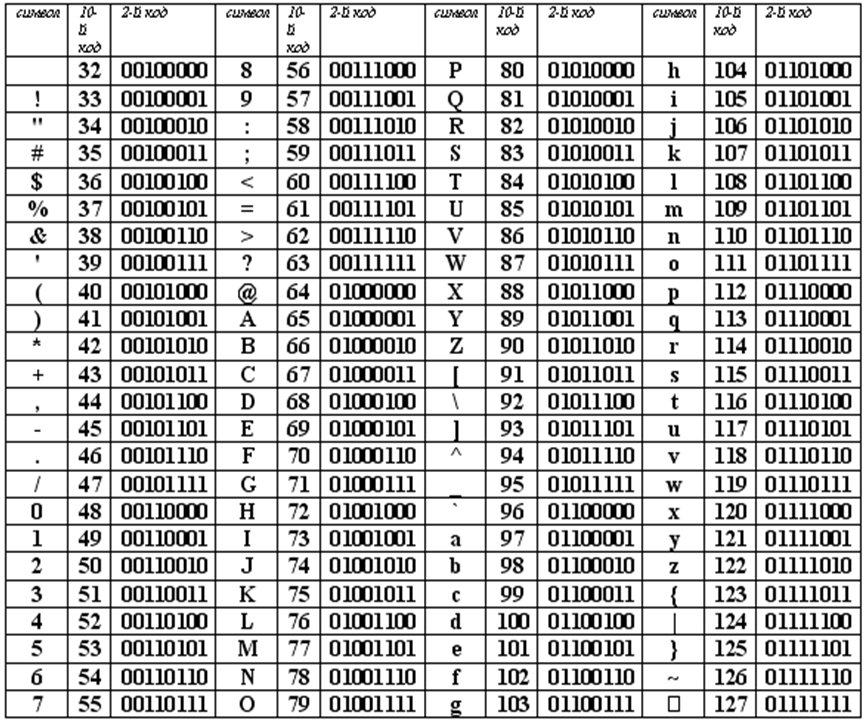
Если вы внимательно посмотрите на обе части таблицы, то увидите, что все буквы расположены в них по алфавиту, а цифры – по возрастанию. Этот принцип последовательного кодирования позволяет определить код символа, не заглядывая в таблицу.
Коды цифр берутся из этой таблицы только при вводе и выводе и если они используются в тексте. Если же они участвуют в вычислениях, то переводятся в двоичную систему счисления.
Коды национального (русского) алфавита расширенной частитаблицы ASCII
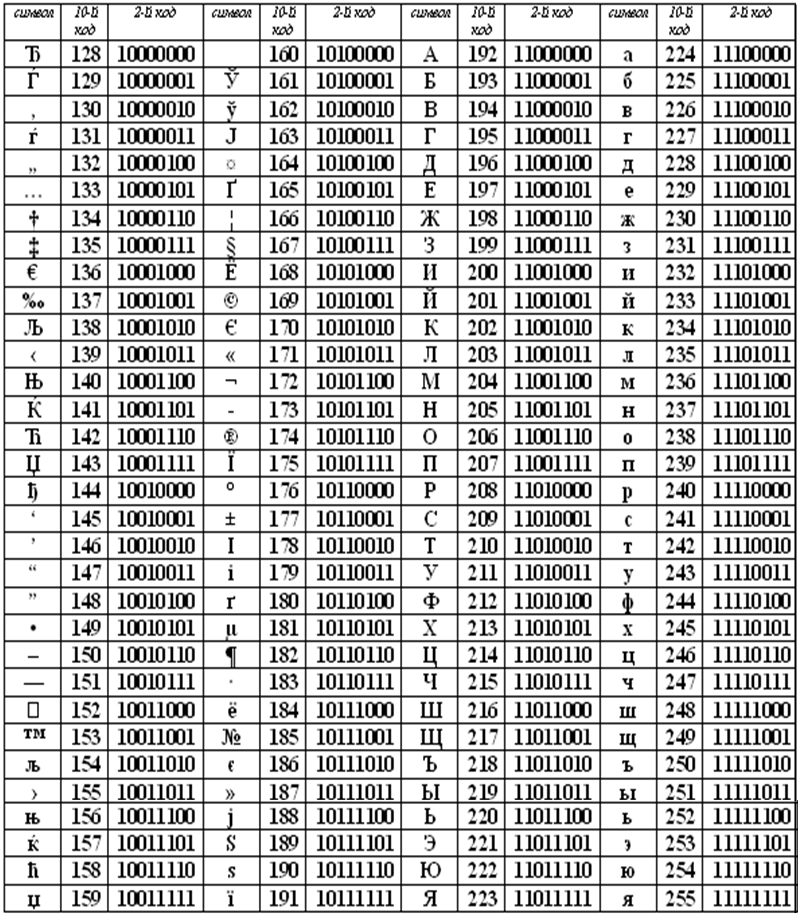
Альтернативные системы кодирования кириллицы.
Тексты, созданные в одной кодировке, не будут правильно отображаться в другой.В настоящее время для поддержки букв русского алфавита (кириллицы) существует несколько кодовых таблиц (кодировок), которые используются различными операционными системами, что является существенным недостатком и в ряде случаев при-водит к проблемам, связанным с операциями декодирования числовых значений символов.
Для разных типов ЭВМ используются различные кодировки:
В настоящее время существует 5 кодовых таблиц для русских букв: Windows (СР(кодовая страница)1251), MS – DOS (СР(кодовая страница)866), KOИ – 8 (Код обмена информацией, 8-битный) (используется в OS UNIX), Mac (Macintosh), ISO (OS UNIX).
Одним из первых стандартов кодирования кириллицы на компьютерах был стан-дарт КОИ-8.
Национальная часть кодовой таблицы стандарта КОИ8-Р
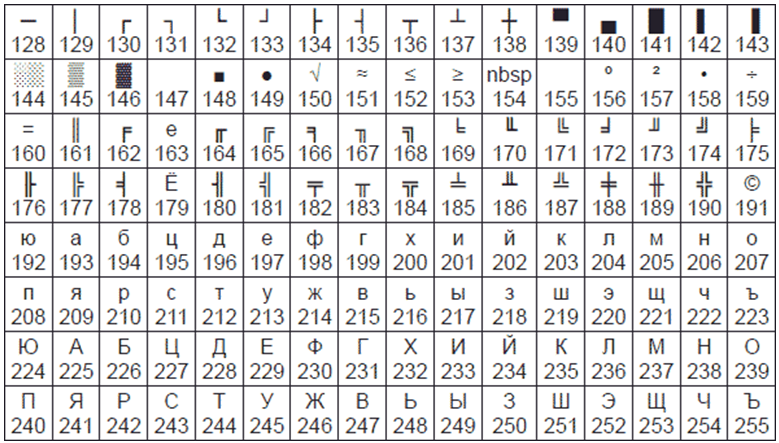
В настоящее время применяется и кодовая таблица, размещенная на странице СР866 стандарта кодирования текстовой информации, которая используется в операционной системе MS DOS или сеансе работы MS DOS для кодирования кириллицы.
Национальная часть кодовой таблицы СР866

В настоящее время для кодирования кириллицы наибольшее распространение получила кодовая таблица, размещенная на странице СР1251 соответствующего стандарта, которая используется в операционных системах семейства Windows фирмы Microsoft.
Национальная часть кодовой таблицы СР1251

Во всех представленных кодовых таблицах, кроме таблицы стандарта Unicode, для кодирования одного символа отводится 8 двоичных разрядов (8 бит).
В мире существует примерно 6800 различных языков. Если прочитать текст, напечатанный в Японии на компьютере в России или США, то понять его будет нельзя. Чтобы буквы любой страны можно было читать на любом компьютере, для их кодировки стали использовать 2 байта (16 бит).
N – мощность алфавита символов в кодовой таблице Unicode.
i – информационный вес символа
Основополагающая таблица использования кодового пространства Unicode
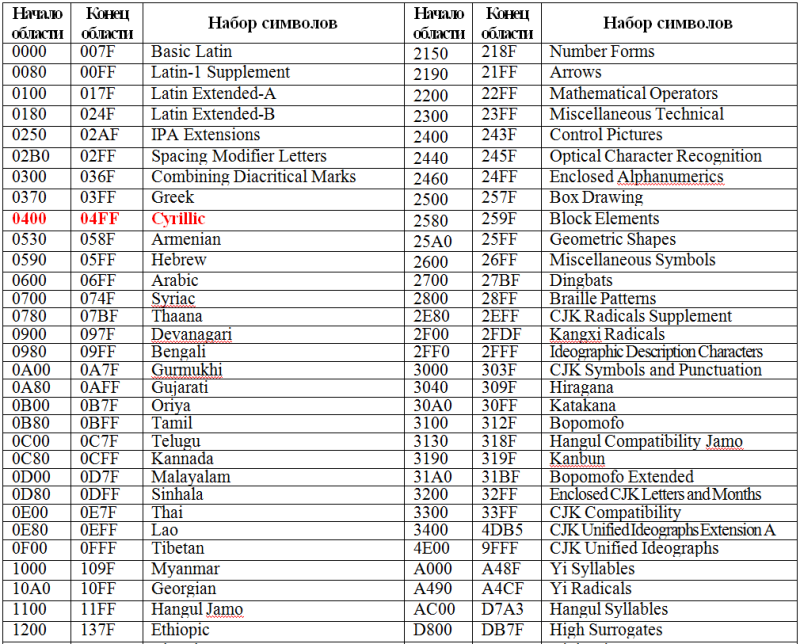
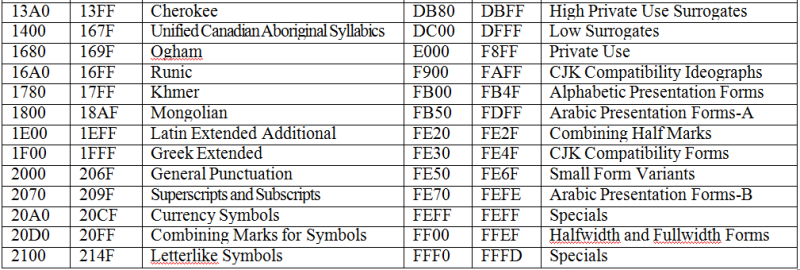
Использование Unicode значительно упрощает создание многоязычных документов, публикаций и программных приложений.
Рассмотрим примеры.
1) Представьте в форме шестнадцатеричного кода слово «ЭВМ» во всех пяти кодировках. Воспользуемся компьютерным калькулятором для перевода чисел из десятичной в шестнадцатеричную систему счисления.
Последовательности десятичных кодов слова «ЭВМ» в различных кодировках составляем на основе кодировочных таблиц:
КОИ8-Р: 252 247 237
СР1251: 221 194 204
СР866: 157 130 140
Мас: 157 130 140
ISO: 205 178 188
Переводим с помощью калькулятора последовательности кодов из десятичной системы в шестнадцатеричную:
2) Определить числовой код символа в кодировке Unicode с помощью тексто-вого редактора MicrosoftWord.
1. В операционной системе Windows запустить текстовый редактор MicrosoftWord.
2. В текстовом редакторе MicrosoftWord ввести команду [Вставка-Символ…]. На экране появится диалоговое окно Символ. Центральную часть диалогового окна занимает фрагмент таблицы символов.
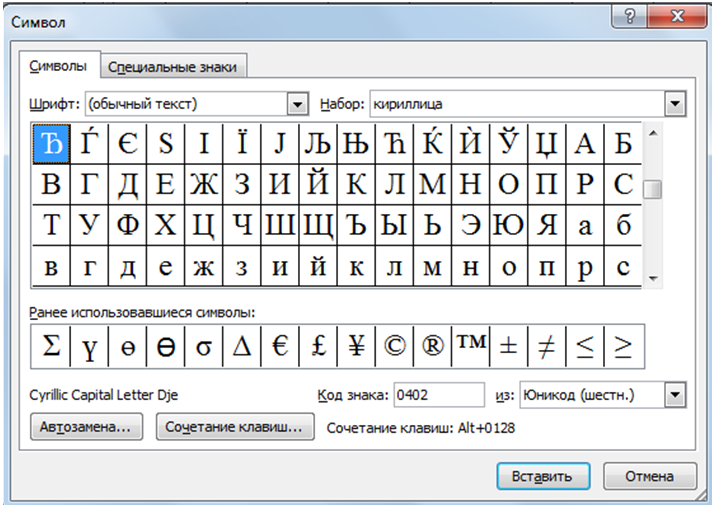
3. Для определения числового кола знака кириллицы с помощью раскрывающегося списка Набор: выбрать пункт кириллица.
4. Для определения шестнадцатеричного числового кода символа в кодировке Unicode с помощью раскрывающегося списка из: выбрать тип кодировки Юникод (шестн.).
5. В таблице символов выбрать символ Э. В текстовом поле кодзнака : появится его шестнадцатеричный числовой код (в данном случае 042D).
Решите задачи:
№1. Закодируйте с помощью таблицы ASCII слова: А) Excel; Б) Access; В) Windows; Г) ИНФОРМАЦИЯ.
№2. Буква «i» в таблице кодов имеет код 105. Не пользуясь таблицей, расшифруйте следующую последовательность кодов: 102, 105, 108, 101.
№3. Десятичный код буквы «е» в таблице ASCII равен 101. Не пользуясь таблицей, составьте последовательность кодов, соответствующих слову help.
№4. Десятичный код буквы «i» в таблице ASCII равен 105. Не пользуясь таблицей, составьте последовательность кодов, соответствующих слову link.
№5. Декодируйте следующие тексты, заданные десятичным кодом:
А) 192 235 227 238 240 232 242 236;
Б) 193 235 238 234 45 241 245 229 236 224;
В) 115 111 102 116 119 97 114 101.
№6. Во сколько раз увеличится информационный объем страницы текста при его преобразовании из кодировки Windows 1251 (таблица кодировки содержит 256 символов) в кодировку Unicode (таблица кодировки содержит 65536 символов)?
№7. Каков информационный объем текста, содержащего слово ПРОГРАММИРОВАНИЕ:
А) в 16-битной кодировке;
Б) в 8-битной кодировке.
№8. Текст занимает ¼ Кбайта. Какое количество символов он содержит?
№9. Текст занимает полных 6 страниц. На каждой странице размещается 30 строк по 80 символов. Определить объем оперативной памяти, который займет этот текст.
№10. Свободный объем оперативной памяти компьютера 320 Кбайт. Сколько страниц книги поместится в ней, если на странице:
А) 32 строки по 32 символа;
Б) 64 строки по 64 символа;
В) 16 строк по 32 символа.
№11. Текст занимает 20 секторов на двусторонней дискете объемом 360 Кбайт. Дискета разбита на 40 дорожек по 9 секторов. Сколько символов содержит текст?
Источник: xn—-7sbbfb7a7aej.xn--p1ai
3. Представление текстовой информации.
Всякий текст состоит из символов — букв, цифр, знаков препинания и т. д., которые человек различает по начертанию. Однако для компьютерного представления текстовой информации такой метод неудобен, а для компьютерной обработки текстов и вовсе неприемлем.
Поскольку текст изначально дискретен — он состоит из отдельных символов, но для компьютерного представления текстовой информации используется другой способ: все символы кодируются числами, и текст представляется в виде набора чисел — кодов символов, его составляющих. При выводе текста на экран монитора или принтер необходимо восстановить изображения всех символов, составляющих данный текст. Для этого используются так называемые кодовые таблицы символов, в которых каждому коду символа ставится в соответствие изображение символа. Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов. На заре компьютерной эпохи, когда США были абсолютным лидером в этой области, стандарты разрабатывались Американским национальным институтом стандартизации (ANSI); впоследствии для разработки и принятия компьютерных стандартов была создана Международная организация стандартизации (ISO).
В программировании наиболее часто используются однобайтовые кодировки: в них код каждого символа занимает ровно 1 байт, или 8 бит. При этом общее количество различаемых символов составляет 2 8 = 256, а коды символов имеют значения от 0 до 255.
Определение 7. Информационным объемом блока информации называется количество бит, байт или производных единиц (килобайт, мегабайт и т. д.), необходимых для записи этого блока путем заранее оговоренного способа двоичного кодирования.
Задание. Оцените в байтах объем текстовой информации в «Современном словаре иностранных слов» из 740 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы).
Решение. Будем считать, что при записи используется кодировка «один символ — один байт». Количество символов во всем словаре равно 80 × 60 × 740 = 3 552 000. Следовательно, объем в байтах равен 3 552 000 байт = 3 468,75 Кбайт или приблизительно 3,39 Мбайт.
Основой для компьютерных стандартов кодирования символов послужил ASCII (American Standard Code for Information Interchange) — американский стандартный код для обмена информацией, разработанный в 1960-х годах и применяемый в США для любых видов передачи информации, в том числе и некомпьютерных (телеграф, факсимильная связь и т. д.). В нем используется 7-битовое кодирование: общее количество символов составляет 2 7 = 128, из них первые 32 символа — управляющие, а остальные — «изображаемые», т. е. имеющие графическое изображение. Управляющие символы должны восприниматься устройством вывода текста как команды, например:
Подача стандартного звукового сигнала
Удаление предыдущего символа
Признак «Конец текстового файла»
End Of File (EOF)
Отмена предыдущего ввода
К изображаемым символам в ASCII относятся буквы английского алфавита (прописные и строчные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Фрагмент кодировки ASCII приведен в табллице
Десятичный код
Двоичный код
Десятичный код
Двоичный код
Хотя в ASCII символы кодируются 7 битами, в памяти компьютера под каждый символ отводится ровно 1 байт, при этом код символа помещается в младшие биты, а старший бит не используется. Главный недостаток стандарта ASCII заключается в том, что он рассчитан на передачу только английского текста. Со временем возникла необходимость кодирования и неанглийских букв.
Во многих странах для этого стали разрабатывать расширения ASCII-кодировки, в которых применялись однобайтовые коды символов; при этом первые 128 символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со 128-го по 255-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п. Из-за несогласованности этих разработок для многих языков было создано по нескольку вариантов кодовых таблиц (например, для русского языка их около десятка!). Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Указав кодовую таблицу, автоматически выбирают и язык, которым можно пользоваться в дополнение к английскому; точнее, выбирается то, как будут интерпретироваться символы с кодами более 127. Для русского языка наиболее распространенными являются однобайтовые кодовые таблицы СР-866, Windows-1251 и КОИ-8. В них первые 128 символов совпадают с ASCII-кодировкой, а русские буквы размещены во второй части таблицы, однако коды русских букв в этих кодировках различны! Вот так будет выглядеть десятичный код слова «Диск» в разных кодировках:
КОИ-8 228 201 211 203
Windows-1251 196 232 241 234
СР-866 132 168 225 170
Однобайтовые кодировки обладают одним серьезным ограничением: количество различных кодов символов в этих кодировках недостаточно велико, чтобы можно было пользоваться одновременно несколькими языками. Для устранения этого ограничения в 1993 году был разработан новый стандарт кодирования символов, получивший название Unicode, который, по замыслу его разработчиков, позволил бы использовать в текстах любые символы любых языков мира.
В Unicode на кодирование символов отводится 32 бит. Первые 128 символов (коды 0-127) совпадают с таблицей ASCII; далее размещены основные алфавиты современных языков: они полностью умещаются в первой части таблицы, их коды не превосходят 65 536 (65 536 = 2 16 ). А в целом стандарт Unicode описывает алфавиты всех известных, в том числе и «мертвых», языков; для языков, имеющих несколько алфавитов или вариантов написания (например, японский и индийский), закодированы все варианты; в кодировку Unicode внесены все математические и иные научные символьные обозначения и даже некоторые придуманные языки (например, письменности эльфов и Мордора из эпических произведений Дж. Р. Р. Толкиена). Потенциальная информационная емкость 32-битового Unicode столь велика, что сейчас используется менее одной тысячной части возможных кодов символов!
В современных компьютерах и операционных системах используется укороченная, 16-битовая версия Unicode, в которую входят все современные алфавиты; эта часть Unicode называется базовой многоязыковой страницей (Base Multilingual Plane, BMP). В UNIX-подобных операционных системах, где работа с Unicode-текстами невозможна из-за особенностей архитектуры, используются особые формы этого стандарта, которые называются UTF (Unicode Transformation Form), в них символы кодируются переменным количеством байтов. Например, в UTF-8 коды символов занимают от 1 до 6 байтов.
Источник: studfile.net