
Я Артём Лисовский, head of learning в IT-компании kt.team. Статья составлена на базе выступления для команды kt.team и может быть полезна и интересна всем разработчикам, которые пишут сервисы с высокими требованиями к отказоустойчивости и масштабируемости.
Сегодня познакомимся с RabbitMQ — программным брокером сообщений на основе стандарта AMQP. Чтобы снизить порог вхождения в тему, я буду объяснять работу с брокером и очередями на наглядном примере. Допустим, мы управляем небольшим заведением общественного питания (пусть это будет ларёк с шаурмой).
Что такое очереди сообщений и зачем они нужны. Варианты реализации очереди сообщений. Брокер очередей
Работа ларька шаурмы очень похожа на работу web-сайта, потому что и там и там посетители выполняют похожие действия:
- предоставляют данные, которые нужно обработать;
- получают какие-то данные в ответ.
В обычной жизни аналог GET-запросов — это меню заведения и всё то, что мы видим, внешняя оболочка.
СЕКРЕТЫ Windows 11 | ТОП НОВЫХ ФИШЕК
А POST-запросы состоят из желания сделать заказ, просьбы дать книгу жалоб и так далее; всё, что мы можем запросить у продавца.
В чём минус обычного меню? Когда покупатель подходит к ларьку, у него нет обратной связи по складу, он не знает, сколько и каких лавашей есть в наличии. Поэтому ему приходится выяснять, есть ли шаурма в толстом лаваше или, наоборот, в тонком. Продавец иногда будет отвечать «да», иногда — «нет», и было бы неплохо всё это автоматизировать, чтобы избавиться от лишних операций.
Для такой автоматизации есть множество систем, но сегодня мы поговорим не о них.
Какой самый простой способ оптимизировать большое количество заказов, например во время бизнес-ланча? Торговцы шаурмой уже вовсю его используют. Нужно обеспечить покупателям возможность заказа по звонку (заказать и забрать через 15 минут). Минус в том, что нам всё ещё нужно обрабатывать эту очередь, и телефонная линия может не справиться с наплывом звонков. Тогда клиенты останутся без заказов, и мы потеряем в выручке.
Другой способ: пригласить друзей и начать готовить шаурму вместе, но тогда у нас возникают новые проблемы. Всё потому, что очередью никто не управляет.
Когда к нам поступает много параллельных заказов и мы не знаем, кто за какой заказ будет отвечать, нам нужен менеджер, который эту очередь заказов распределит по исполнителям.
Если этого не сделать, у нас появляются следующие риски:
- потерять заказ;
- взяться за один заказ нескольким людям одновременно или, наоборот, не взяться вообще;
- заказчик уйдёт, а мы продолжим делать шаурму, за которую никто не заплатит;
- если один и тот же исполнитель и готовит, и принимает оплату, ему придётся слишком часто снимать перчатки, из-за чего будет тратиться слишком много времени, и так далее.
В общем, возникает небольшой хаос, как в типичной модели управления проектами waterfall.
Шоу Иды Галич ЕСТЬ ВОПРОСИКИ — Антон Шастун. Уход с ТНТ, свадьба Джигана и участие в шоу “Холостяк”.
Как можно решить эту проблему?
Первый способ
Самое простое — поставить над всеми исполнителями старшего официанта, менеджера, кипера, который будет распределять заказы. Если так сделать, то до поры до времени всё будет идти вполне неплохо.
В таких целях на маленьких объектах часто делают MySQL-табличку, в которую записывают очередь. Напротив каждой записи проставляют статус «выполнено» / «не выполнено» и далее берут данные для работы из этой таблички. Наиболее явные минусы этого способа:
- очевидно, что мы не блокируем содержимое, т. е. несколько работников (исполнителей) могут взяться за один и тот же заказ;
- если будет много заказов, а MySQL лежит у нас на том же сервере, что и база (а в основном так и бывает), мы можем просто «положить» нашу базу — и всё пойдёт плохо.
Второй способ
Использовать брокер очередей, который будет управлять нашей очередью. Мы можем задать брокеру определённую логику распределения этой очереди, чтобы все сообщения были гарантированно получены и обработаны нужным образом.
Посмотрим, что предлагается в коробке большинства брокеров (и в RabbitMQ тоже), на примере решаемой задачи.
- Заказы (и не только) гарантированно записываются в очередь.
- Заказы распределяются между поварами.
- Если повар, скажем, отошёл или сломал руку, заказ остаётся в очереди. Этот повар может взять заказ позже, или его может взять другой повар.
- Заказ блокируется (чтобы один и тот же заказ не взяли два повара одновременно).
- Есть отдельные очереди на пиццу/роллы.
Реализация брокера очередей в виде RabbitMQ
Плавно переходим к реализации брокера очередей в виде RabbitMQ. Это гибридный брокер, он поддерживает несколько протоколов.
Сегодня наиболее распространённый протокол — это AMQP. О нём по большей части и будем вести речь.
Есть и другие протоколы, например MQTT, когда на TCP/IP повешена возможность подписки и получения, исполнения сообщений.
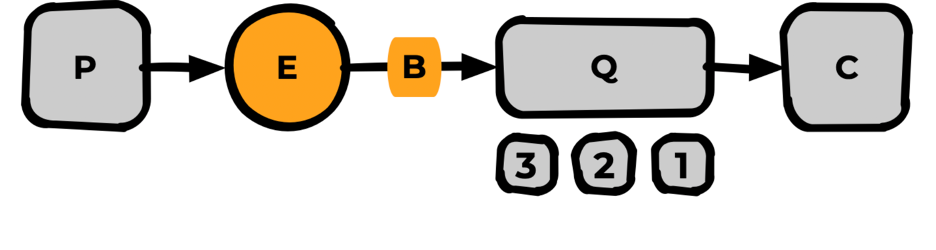
В AMQP есть несколько дефолтных сущностей, с которыми и происходит работа:
- producer — отправитель сообщения;
- message — само сообщение;
- exchange — пункт роутинга сообщений (здесь мы можем указать, куда какое сообщение должно пойти);
- queue — сама очередь из сообщений;
- consumer — исполнитель, который из этой очереди что-то заберёт и что-то сделает.
Если смотреть принципиально (сверху), то AMQP-протокол вообще и RabbitMQ в частности представляют собой следующую модель.
Producer публикует сообщения в брокер, брокер хранит это сообщение в очереди (и понимает, в какой из очередей его надо хранить), затем доставляет его исполнителю. Либо исполнитель подписывается на сообщения и, как только они появляются, пытается их исполнить. Брокер также может возвращать сообщения в очередь, чтобы они оставались там при необходимости.
Самый банальный пример такой модели — создание PDF.
Почему создание PDF и подобных задач имеет смысл закинуть в очередь? Обычно они занимают много времени, и тратить его, пока наш пользователь находится между моментом совершения заказа и моментом отправки файла, не хочется. В большинстве случаев разработчики пишут так: «Спасибо за ваш запрос, мы создадим PDF и отправим его вам на почту».
Если проект небольшой, то логика при этом обычно происходит в MySQL-таблицах. Но как только встаёт вопрос масштабирования, MySQL даёт сбой — возможны блокировки, отсутствие управления очередью, медленная (по сравнению с memory-based) скорость обработки. Реляционная база данных хороша, но лучше хранить сообщения в хранилище побыстрее и более предназначенном для этого. Мы можем записать этот запрос в очередь и уже из очереди выполнять его и отправлять пользователю.
Сообщение — это не интерпретируемая брокером единица сущности. Это может быть как просто строка, так и объект в виде JSON или любая структура, представленная в виде строки.
Неважно, что мы туда запишем; мы можем указать тип сообщения (например application/JSON), и тогда при обработке будет легко узнать, что закладывалось в начале. Сообщение не интерпретируется, оно просто хранится.
Затем оно попадает в exchange, в точку роутинга. Задача точки роутинга — определить, в какую из очередей должно попасть сообщение.
Вместе с сообщением мы можем прислать какой-то ключ. По ключу мы можем понять, в какую из очередей (одну или несколько) должно попасть сообщение.
Соответственно, есть несколько видов точки роутинга, видов работы:
- простейший вариант — fanout, когда сообщение попадает во все доступные очереди;
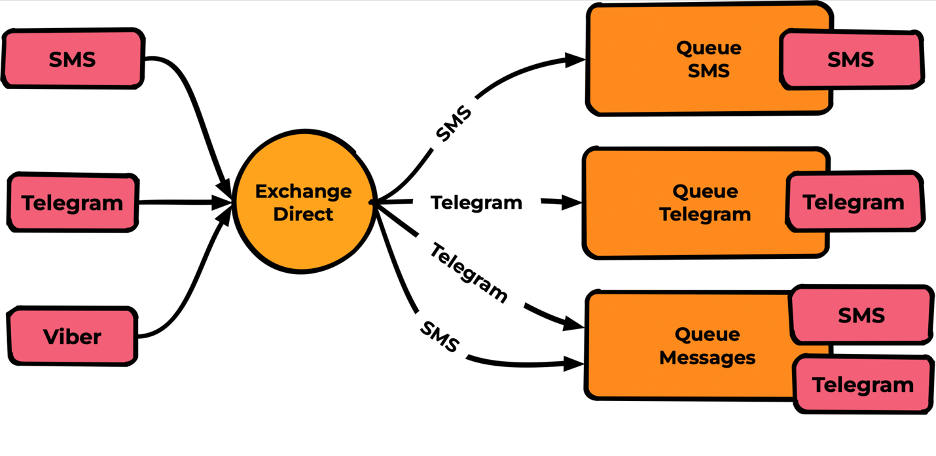
- direct — полное совпадение ключа. Мы можем создать очередь для одного ключа, очередь для другого; у очереди может быть несколько ключей — всё как в обычном STP-роутинге;
- topic — ключ удовлетворяет маске (#*), где * — любое непустое слово (одно), а # — то же самое, что и *, только здесь допустимо и пустое слово;
- headers — мы имеем возможность указать какой-то тип прямо в message и роутиться по нему (используется, когда нет отдельного ключа).
Кроме того, очереди представляют собой обычную модель, в которой нет ничего сложного. Из очереди мы берём сообщение путём подключения к брокеру и запроса из очереди либо путём постоянного подключения и запроса из очереди.
Какие фишки подразумеваются в очереди и уже реализованы в Rabbit’е
1. Durable
Durable — возможность сохранения состояния при перезагрузке сервера. Например, сервер «уронили» (или он «упал» сам), а очередь нужно не потерять. Для скорости работы очередь хранится в RAM (random-access memory), поэтому, чтобы обеспечить её персистентное состояние, мы должны дополнительно сохранять очередь куда-то на диск. Тут логика работы аналогична любому RAM storage типа Redis и т. п. Мы просто делаем дамп, храним его на диске, в случае «падения» поднимаем дамп с диска — и всё возвращается на круги своя (и никакие сообщения мы не потеряли, кроме периода даунтайма).
Есть несколько режимов создания дампов. Например, в версии 3.9 есть lazyload, который делает полный дамп при каждом запросе, но он значительно сажает производительность. Можно поступить проще: «подрубиться» к RabbitMQ через Redis и использовать хранилище Redis как основное.
Кроме того, нужно логировать, создавать отдельную очередь, которая бы писала всеми любимую реляционную базу данных. Best practice для high-load-проектов, когда мы держим только кеш в состоянии памяти (все новые заказы например). Одно сообщение можно отправить в несколько очередей, и одна из очередей будет использоваться для связи с реляционной базой данных и для постоянного хранения в ней — так же, как у тебя, наверно, сделано и везде с Elastic (или MySQL, или PostgreSQL, или чем-нибудь другим, что у тебя используется на backend’е). В случае с Elastic он используется как кеш и связывается с постоянным хранилищем. В случае «смерти» Elastic’а всё будет нормально, мы не потеряем данные, а вот в случае «смерти» базы данных нормально уже не будет.
2. TTL на примере шаурмы — ни один клиент не будет ждать шаурму час), и мы можем задать TTL, чтобы каждое сообщение, которое пролежит больше 60 минут, исчезало из очереди.
3. ACK — acknowledge
Сообщения могут быть нескольких видов, и самые популярные из них два:
- сообщение, которое нужно сразу удалить из очереди, как только оно было взято, не дожидаясь ответа от того, кто его забрал (это и есть ACK);
- сообщение, которое не нужно удалять из очереди, пока не получен нужный ответ. Это сообщение мы помечаем и блокируем, чтобы другие не взяли его. Если нам не вернётся ответ, оно останется у нас, и другие исполнители смогут взять его.
Кейс: актуальные варианты использования ACK.
Например, сайт связан с каким-то сторонним сервисом, есть очередь из оплат или трек-номеров посылок. Мы берём одно сообщение, отправляем его в сторонний сервис, а он оказывается (внезапно) под высокой нагрузкой и недоступен. Если бы у нас не было блокировки, это сообщение исчезло бы из очереди, и мы бы потеряли клиента. Чтобы этого избежать, можно вернуть ответ «не получилось» или разделить таймаут по времени таким образом, чтобы, если ответ от поставщика данных задержался более чем на 15 секунд, сообщение возвращалось в очередь.
4. Dead lettering
Dead lettering — когда наше сообщение вернулось с ошибкой (блек-джеком) в очередь и нам нужно обработать его не сразу, а с задержкой 5–10 секунд. Такое часто бывает, когда провайдер данных не доступен (т. е. провайдер возвращает нам ошибку, скажем, 404, 504 или что-то подобное). В этом нет ничего страшного, мы возвращаем сообщение в очередь и при возврате можем указать, через какое время этот элемент будет доступен для повторного просмотра.
В общем и целом это работает примерно таким образом.
Источник: dzen.ru
RabbitMQ: терминология и базовые сущности

2022-12-02 в 7:40, admin , рубрики:
При работе с инструментом важно знать теоретические основы. Во-первых, вам будет значительно проще искать ответы на вопросы в Google и понимать официальную документацию. Во-вторых, при обращении в профильные чаты вы будете называть вещи своими именами, что позволит быстрее получить ответ (или вообще получить его: если ваши слова и термины будут непонятны другим, вряд ли они смогут ответить на вопрос).
Алексей Барабанов, IT-директор «Хлебница» и спикер курса «RabbitMQ для админов и разработчиков», подготовил конспект, который поможет понять терминологию и базовые сущности RabbitMQ.

Базовая схема всех сущностей RabbitMQ
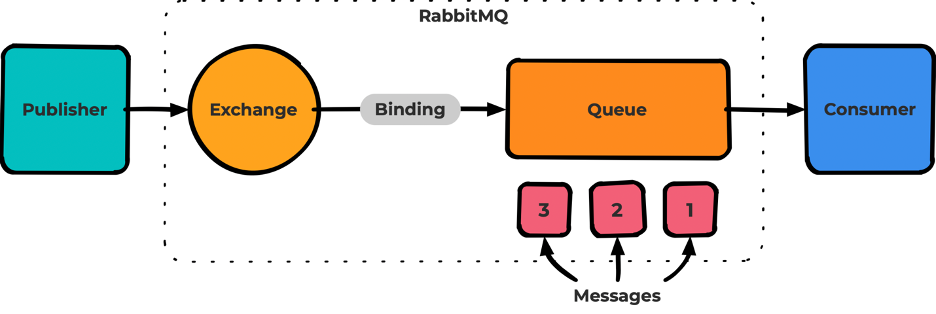
Пробежимся по названиям слева направо:
- Publisher — публикует (паблишит) сообщения в Rabbit.
- Exchange — обменник. Сущность Rabbit, точка входа для публикации всех сообщений.
- Binding — связь между Exchange и очередью.
- Queue — очередь для хранения сообщений.
- Messages — сообщение, атомарная сущность.
- Consumer — подписывается на очередь и получает от Rabbit сообщения.
Также встречаются термины:
- Publishing — процесс публикования сообщений в обменник.
- Consuming — процесс подписывания consumer ***на очередь и получение им сообщений.
- Routing Key— свойство Binding.
- Persistent— свойство сохранения данных при перезагрузке сервиса (также известное как стейт).
Publisher
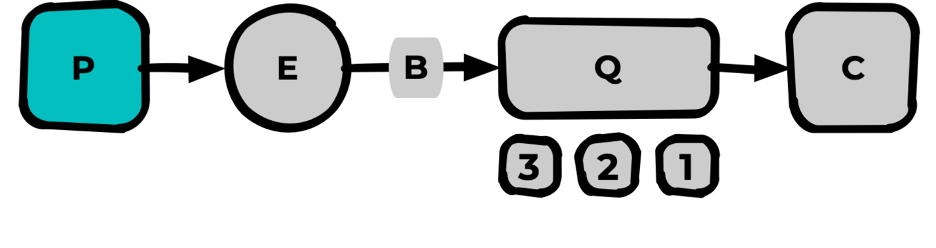
Внешнее приложение (крон/вебсервис/что угодно), генерирующее сообщения в RabbitMQ для дальнейшей обработки.
Создаёт соединение (connection) по протоколу AMQP, в рамках соединения создаёт канал (channel). В рамках одного соединения можно создать несколько каналов, но это не рекомендуется даже официальной документацией RabbitMQ.
«Флаппинг» каналов: если Publisher для каждого сообщения создаёт соединение, канал, отправляет сообщение, закрывает канал, закрывает соединение, это очень плохая история. Rabbit становится плохо уже на ~300 таких пересозданий каналов в секунду. Будьте внимательны. Если нет возможности изменить Publisher, можно использовать amqproxy.
Важное замечание: не следует использовать amqproxy для consumer, есть проблемы одностороннего разрушения соединений.
Publisher может декларировать практически все сущности — exchanges, queues, bindings и др. На практике лучше подходит стратегия декларирования всех нужных сущностей consumer, но решать нужно для каждого проекта индивидуально.
Publisher всегда пишет в exchange. Даже если вы думаете, что он пишет напрямую в очередь, это не так. Он пишет в служебный exchange с routing key, совпадающим с названием очереди.
Publisher определяет delivery_mode для каждого сообщения — так называемый «признак персистентности». Это значит, что сообщение будет сохранено на диске и не исчезнет в случае перезагрузки Rabbit.
- delivery_mode=1 — не хранить сообщения, быстрее.
- delivery_mode=2 — хранить сообщения на диске, медленнее, но надёжнее.
Также publisher определяет Routing Key для каждого сообщения — признак, по которому идёт дальнейшая маршрутизация в Rabbit.

Publisher может выставлять confirm флаг — отправлять указания Rabbitmq через отдельный канал подтверждения об успешной приёмке сообщений. Например, если у Rabbit закончится место на диске, то некоторое время он ещё будет принимать сообщения от Publisher. Publisher будет думать, что всё в порядке, хотя сообщения с высокой долей вероятности не дойдут до Consumer и не сохранятся в очереди для дальнейшей обработки. Полезная вещь, но ощутимо снижает скорость работы и сложно реализуема в однопоточных языках разработки.
Также есть флаг mandatory — указание Rabbit складировать сообщения, не имеющие маршрута в какую-либо очередь в отдельный Exchange. Редкий и мало используемый кейс.
Exchange
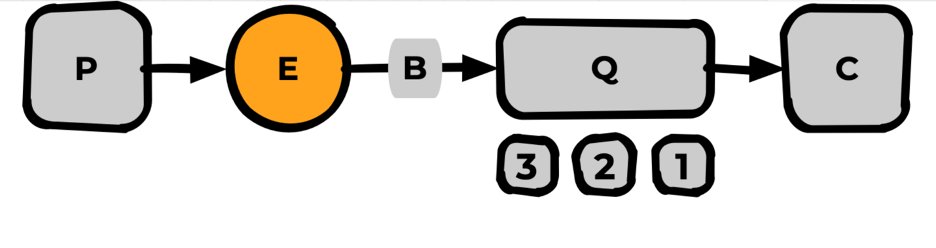
Базовая сущность RabbitMQ. Является точкой входа и маршрутизатором/роутером всех сообщений (как входящих от Publisher, так и перемещающихся от внутренних процессов в Rabbit)
Неизменяемая сущность: для изменения параметров Exchange нужно его удалять и декларировать заново.
Binding: не являются частью Exchange, можно менять отдельно.
Рассылает сообщение во все очереди с подходящими binding (но не более одного сообщения в одну очередь, если есть несколько подходящих binding).
Durable/Transient — признак персистентности Exchange. Durable означает, что exchange сохранится после перезагрузки Rabbit.
Exchange не подразумевает хранения! Это не очередь. Если маршрут для сообщения не будет найден, сообщение сразу будет отброшено без возможности его восстановления.
Binding
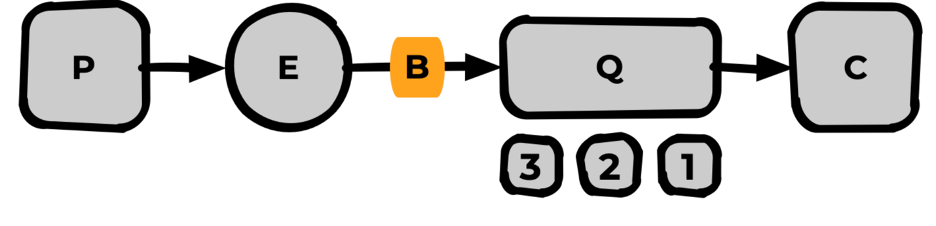
Базовая сущность Rabbit, статический маршрут от Exchange до Queue (от обменника до очереди).
Неизменяемая сущность: если нужно изменить binding, его удаляют и декларируют заново.
Bindings между парой exchange-очередь может быть несколько, но только с разными параметрами.
Параметры binding — или routingkey, или headers — в зависимости от типа Exchange.
Типы Exchange
После разбора binding вернёмся к типам Exchange, так как их работа неразрывно связана.
Выделяют четыре типа Exchange:
Рассмотрим каждый более подробно.
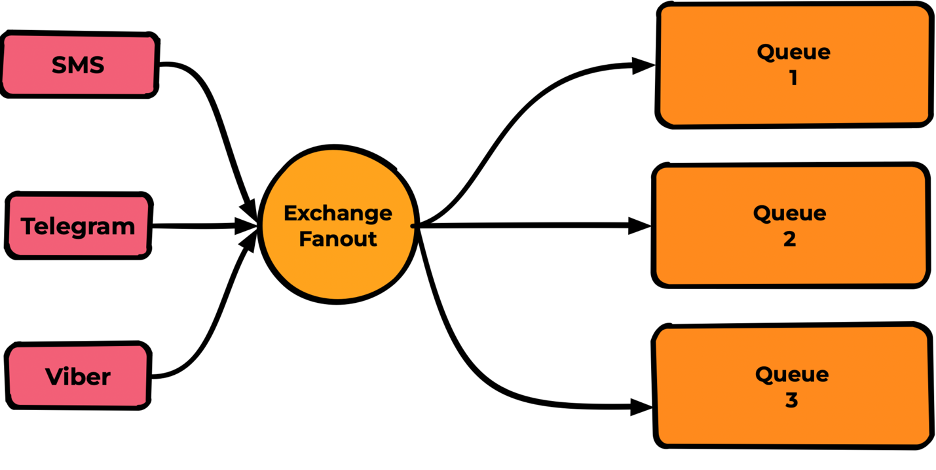
Fanout
Exchange публикует сообщения во все очереди, в которых есть binding, игнорируя любые настройки binding (routing key или заголовки).
Самый простой тип и наименее функциональный. Редко бывает нужен. По скоростям выдает на тестах около 30000mps, но столько же выдает и тип Direct.
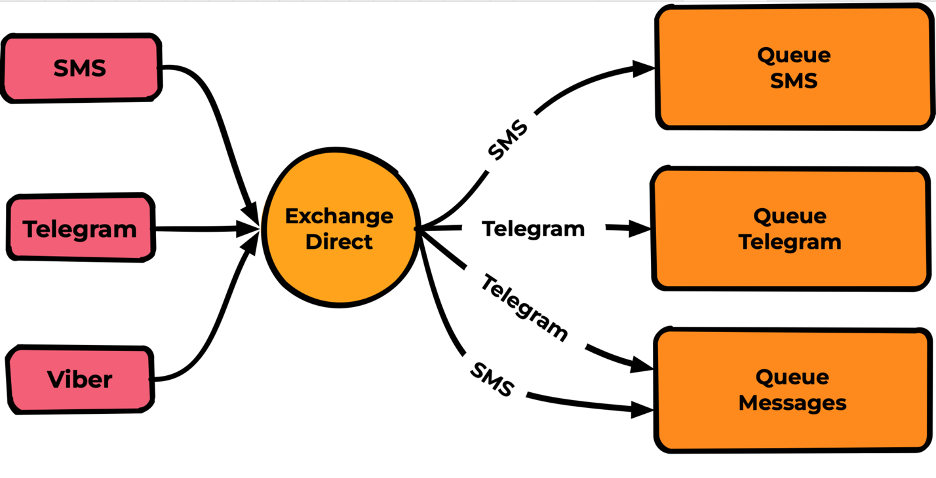
Direct
Exchange публикует сообщения во все очереди, в которых Routing Key binding полностью совпадает с Routing Key Messages.
Наиболее популярный тип, по скорости сравнимый с fanout (на тестах не увидел разницы) и при этом обладающий необходимой гибкостью для большинства задач.
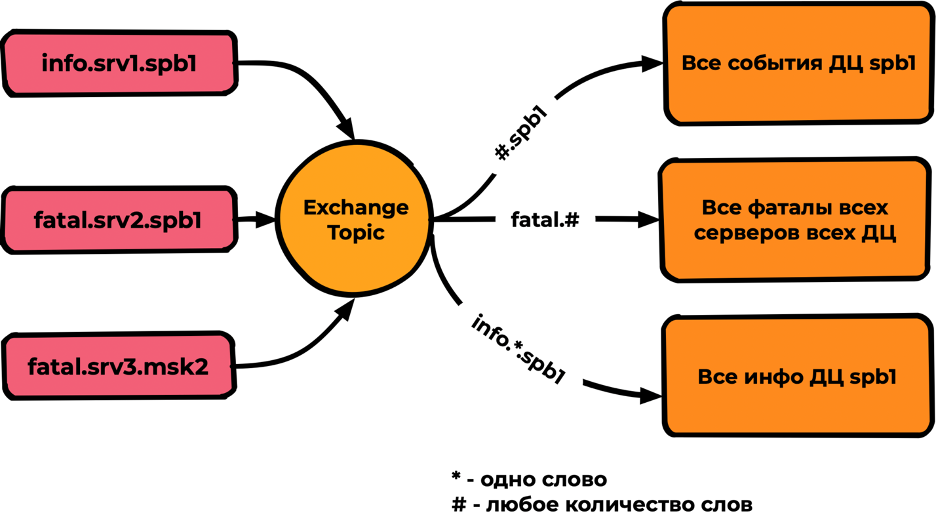
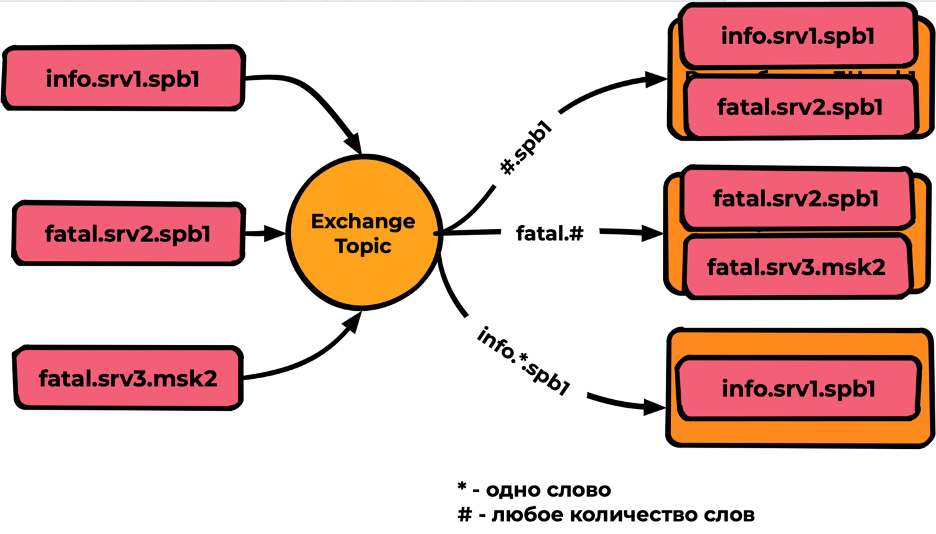
Topic
Тип Exchange, похожий на Direct, но поддерживающий в качестве параметров binding Wildcard * и #, где:
- — совпадение одного слова (слова разделяются точкой);
- # — любое количество слов.
Производительность топика на тестах показала скорости в три раза ниже fanaut/direct — не более 5000-10000mps
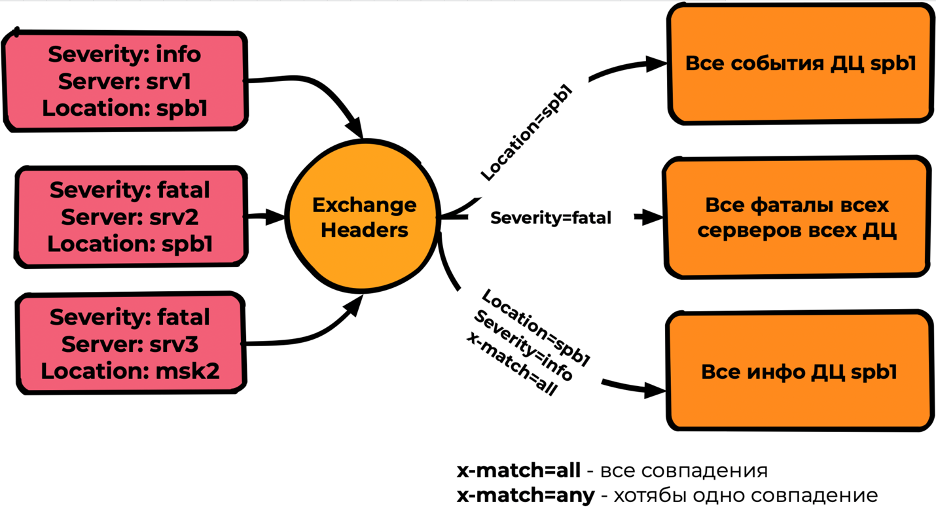
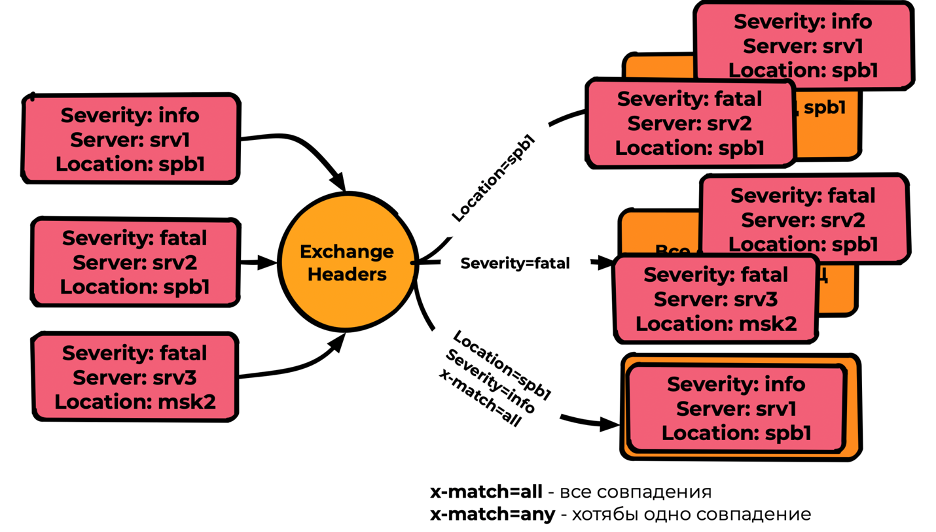
Headers
Наиболее гибкий, но наименее производительный тип. Скорости очень сильно зависят от сложности условий и поэтому труднопрогнозируемы. Оперирует не Routing key, а заголовками сообщений и binding. В binding указываются ожидаемые заголовки, а также признак x-match, где:
- x-match=all — необходимы все совпадения для попадания сообщения;
- x-match=any — необходимо хотя бы одно совпадение.
Queue
Базовая сущность RabbitMQ, представляет из себя последовательное хранилище для необработанных сообщений.
Хранение сообщений на диске (persistent) зависит от флага delivery_mode, назначаемым publisher для каждого сообщения.
Durable/Transient — признак персистентности очереди. Durable значит, что exchange сохранится после перезагрузки Rabbit.
Важно понимать, что даже если вы отправили сообщения с признаком delivery_mode=2 (persistent), но очередь задекларирована не как Durable, то при перезагрузке Rabbit очередь и все содержащиеся в ней сообщения будут безвозвратно утрачены.
Есть три типа очередей:
- Classic — обычная очередь, используется в большинстве случаев.
- Quorum — аналог классической очереди, но с обеспечением гарантий консистентности, достигаемый кворумом в кластере.
- Stream — новый вид очередей (начиная с версии Rabbimq 3.9), пока ещё мало кем используемый, аналог принципов Apache Kafka.
Message
Базовая сущность RabbitMQ — само сообщение, несёт полезную нагрузку (payload), проходит весь путь от Publisher до Consumer.
- payload — полезная нагрузка, может быть как string, так и base64. Можно закидывать туда хоть картинки, но потом не надо удивляться огромным трафикам между сервисами. Теоретический лимит размера одного сообщения — 2Gb, но на практике рекомендуемый размер сообщения 128mb;
- routing key — ключ маршрутизации, может быть только один для одного сообщения;
- delivery_mode — признак персистентности;
- headers — заголовки сообщения. Нужны для работы Exchange типа headers, а также для дополнительных возможностей Rabbit типа TTL.
Consumer
Замыкает обработку Сonsumer — демон, получающий сообщения из Queue и выполняющий ту самую логику, ради которой сообщение проделало весь этот путь. Например, отправка уведомления, запись в базу данных, генерация оффлайн отчёта или отправка сообщения в другую Queue.
Так же, как и Publisher, Consumer создаёт соединение (connection) по протоколу AMQP. В рамках соединения создаёт канал (channel) и уже инициирует consuming в рамках этого канала.
Consumer может декларировать практически все сущности — exchanges, queues, bindings и тд. На практике мы стараемся декларировать все сущности именно Consumer, но решать нужно для каждого проекта индивидуально.
Consumer подписывается только на одну очередь. Если вы хотите получать сообщения из разных очередей, правильнее будет корректно смаршрутизировать их потоки в одну очередь, чем городить пулы Consumer внутри приложения.
Сообщения в Consumer попадают по push-модели — протакливаются Rabbit в канал по мере их появления и (или) освобождения Consumer. Никакой периодики, задержки — это жирный плюс.
Prefetch count — важный параметр Consumer, обозначающий количество неподтверждённых Consumer сообщений в один момент. По умолчанию во многих библиотеках он равен 0 (по сути отключен). В такой ситуации Rabbit проталкивает все сообщения из очереди в Consumer, а тот во многих случаях при достаточном количестве сообщений просто отъезжает.
Если нет понимания, какое значение ставить, лучше ставить «1» — пока Consumer не обработает одно сообщение, следующее к нему не поступит. Как только Rabbit подтвердит обработку, следующее сообщение будет получено незамедлительно.
Когда вы поймёте, что у вас есть мультитред, и вы можете обрабатывать большие нагрузки, вы поднимете этот параметр, но уже осознанно.
Consumer может подтвердить обработку сообщения — механизм Acknowledge (ack). Или вернуть сообщение в Queue при неудачной обработке — механизм Negative acknowledge (nack).
Механизм nack также срабатывает автоматически при разрушении канала к Consumer. Это удобно использовать: если на горячую выключить Consumer, сообщения, которые он обрабатывал, автоматически вернутся в очередь.
AutoAck — флаг автоматического подтверждения всех протакливаемых сообщений (не требует ack от Consumer). Работает быстро, но не даёт никаких гарантий успешной обработки сообщений.
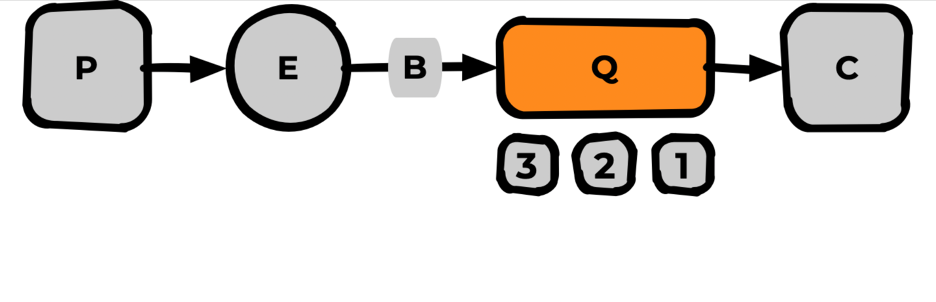
FIFO очереди
Основу Rabbit представляют собой именно такие очереди:
FIFO = first in — first out
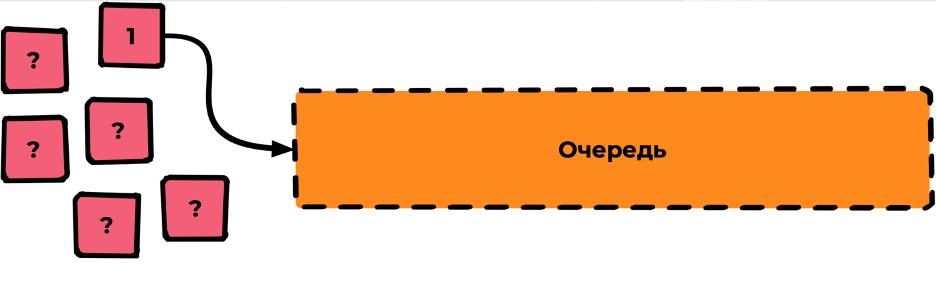
Попадая в очередь, сообщения выходят из неё в той же последовательности, что и вошли. Последовательность определяется моментом попадания сообщения в очередь, не бывает «одновременных сообщений» в рамках одной очереди, у них всегда есть порядок.
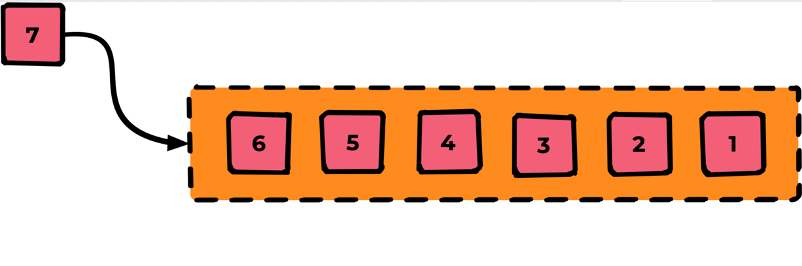
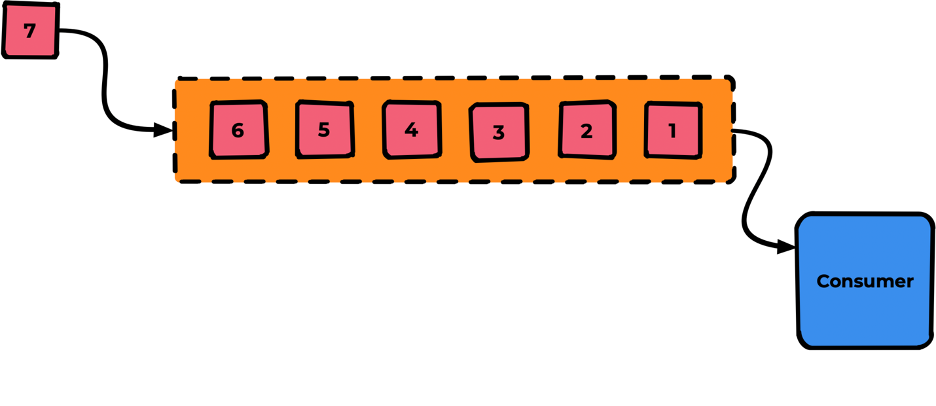
После выстраивания очереди по порядку мы переходим к «обслуживанию» этой очереди. Для этого подключается Consumer (например, как открытие одного кабинета в очереди к врачу).
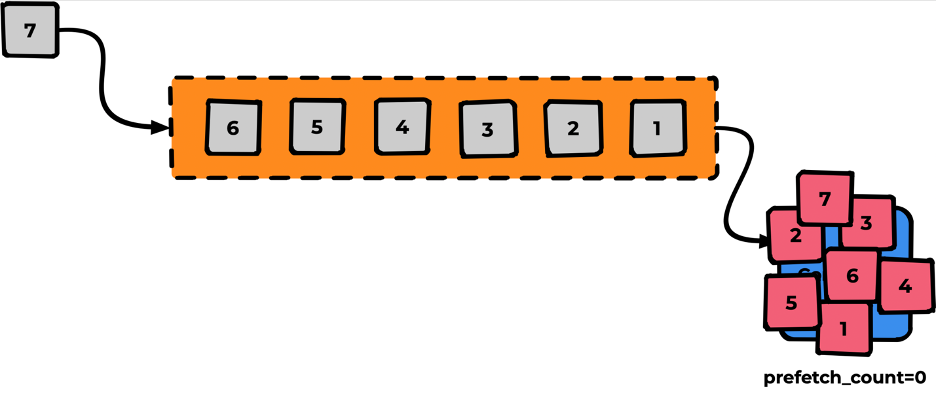
Если мы не укажем prefetch_count, его значение будет равным нулю. Это значит, что все сообщения протолкнутся в Consumer — ничего хорошего обычно в таком поведении нет. Аналогия: открылся кабинет, и все люди в очереди ввалились туда решать свои вопросы.
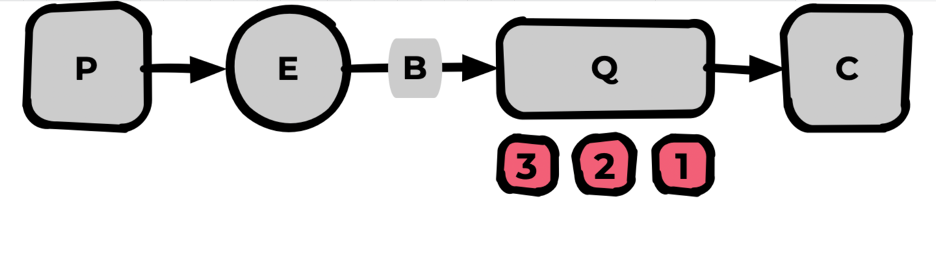
Поэтому мы явно укажем prefetch_count=1. Теперь без подтверждения более одного сообщения в Consumer находится не сможет.
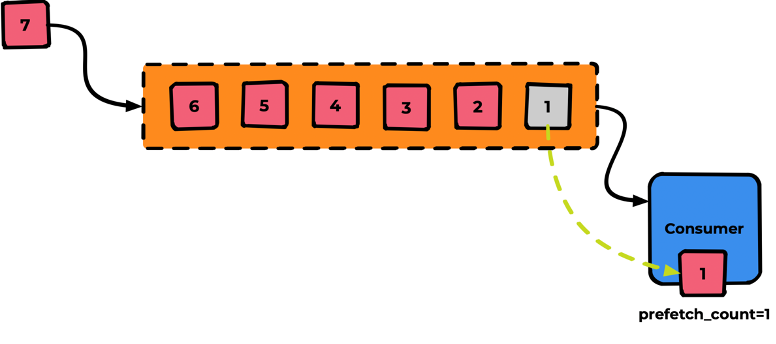
Далее после успешной обработки Consumer выполняет «ack» для данного сообщения:
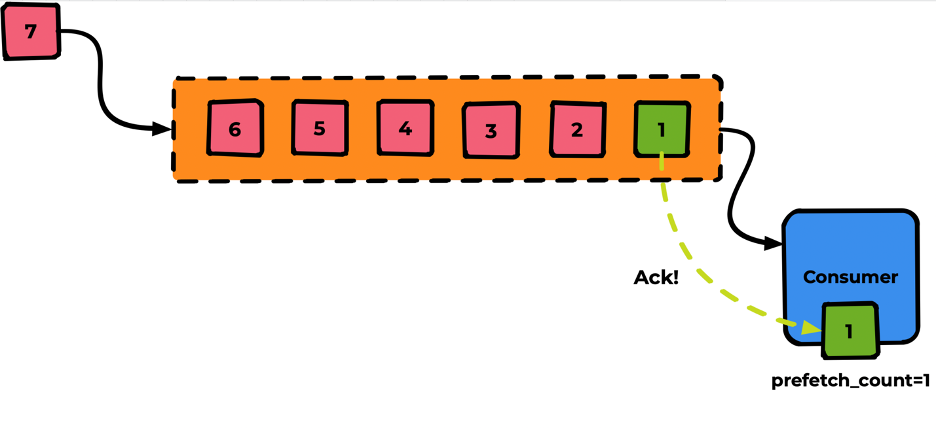
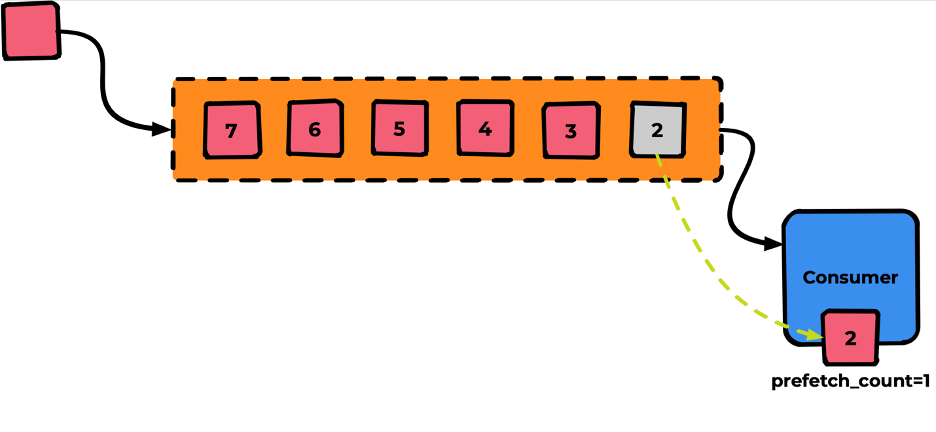
Получив ack, Rabbit удалит сообщение из очереди и незамедлительно протолкнёт в Consumer следующее сообщение (и так далее):
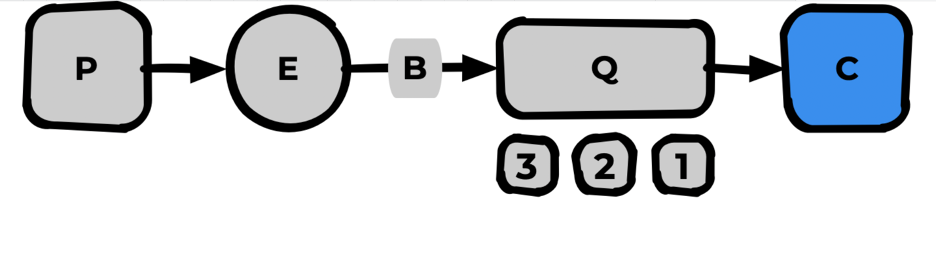
А если мы захотим увеличить скорость обработки? Можем поставить в «кабинете» ещё один «стол с врачом». Для этого укажем prefetch_count=2
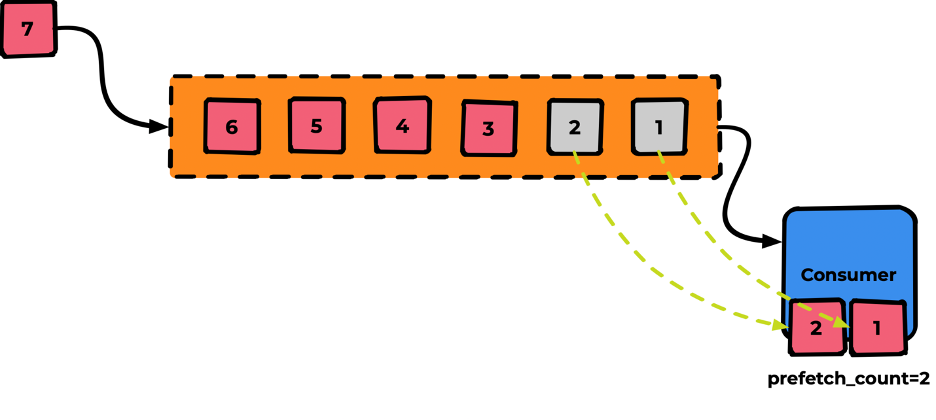
Теперь будет идти обработка сразу двух сообщений. А если мы хотим быстрее? Добавляем ещё один сonsumer-кабинет (например с prefetch_count=1)
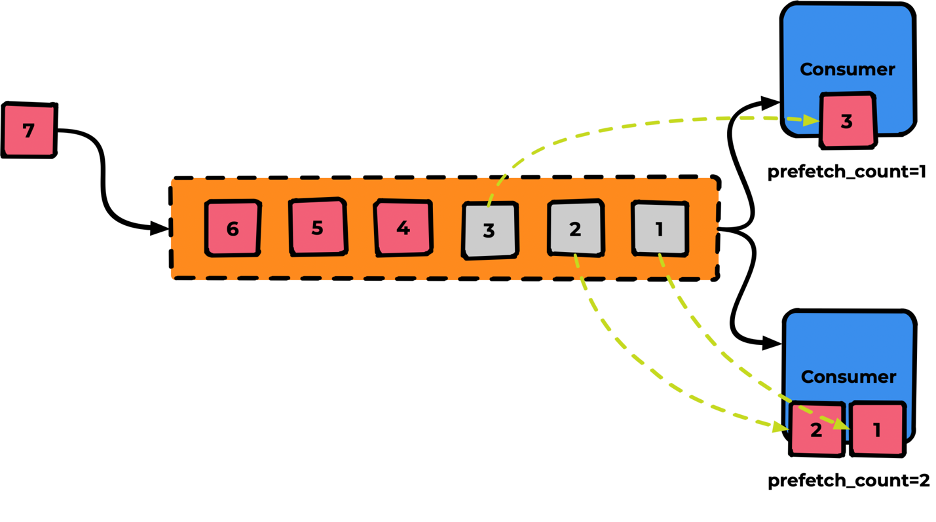
Общая концепция горизонтальной масштабируемости выглядит именно так.
Источник: www.pvsm.ru
11 rabbit это название конкретной программы или класса программ


Главное меню
Соглашение
Регистрация

Английский язык
Астрономия
Белорусский язык
Информатика
Итальянский язык
Краеведение
Литература
Математика
Немецкий язык
Обществознание
Окружающий мир
Русский язык
Технология
Физкультура
Для учителей
Дошкольникам
VIP — доступ
Помещать страницу в закладки могут только зарегистрированные пользователи
Зарегистрироваться

Получение сертификата
о прохождении теста
Источник: testedu.ru