
Для создания электронных библиотек и архивов путем перевода книг и документов в цифровой вариант и при необходимости редактирования полученного по факсу документа используются специальные системы распознавания символов.
С помощью сканера можно получить изображение страницы с текстом в графическом формате.
Но работать с этим текстом невозможно, потому что любое сканирование – это всего лишь изображение
Текст можно будет читать, распечатывать, но только не редактировать.
Для перевода графического документа в текстовый файл необходимо провести распознавание текста.
Преобразование графического изображения в текст занимаются программы оптического распознавания текста (Optical Character Recognition, OCR).
Современные OCR умеют:
- распознавать тексты, набранные не только разными шрифтами, но и самыми экзотическими, в том числе и рукописных
- корректно работать с текстами, содержащими слова на нескольких языках
- распознавать таблицы
- распознавать нечетко набранные или написанные тексты
Само собой, распознать текст — это еще полдела. После этого нужно обеспечить сохранение результата в файле текстового формата, например Microsoft Word.
Программа для распознавания текста: топ-7 лучших утилит
В процессе распознавания документов в плохом качестве (машинописный текст, факс) используется метод распознавания символов по наличию определенных структурных элементов — отрезков, колец, дуг.
Любой символ легко описывается с помощью набора значений, определяющих расположение его частей. Например, обе буквы «Н» и буква «И» состоят из трех отрезков. Два из них расположены параллельно друг другу, а третий их соединяет. А различие – лишь в величине углов отрезков.
Самые распространенные системы оптического распознавания текста — ABBYY FineReader и CuneiForm.
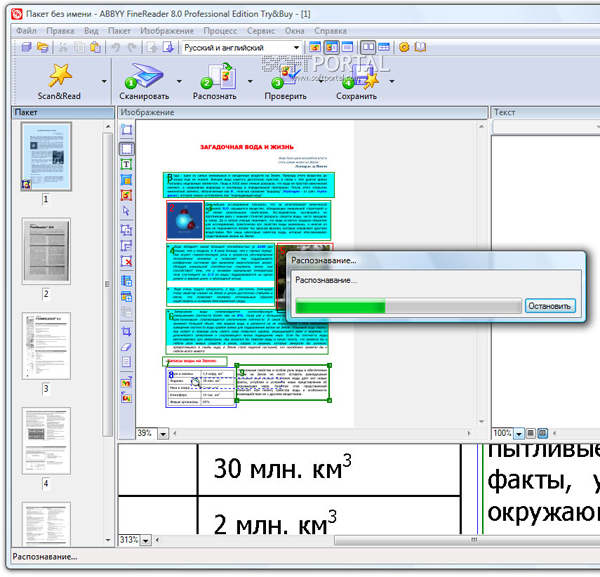
FineReader является омнифонтовой системой распознавания текстов. Это значит, что она позволяет распознавать тексты, набранные практически любыми шрифтами.
Одним из козырей FineReader является поддержка огромного (для таких программ) количества языков распознавания — более 176 (экзотические, древние языки, популярные языки программирования).
Для запуска процесса распознавания достаточно положить лист бумаги в сканер и нажать кнопку Scan Сократ Персональный» и Pragma. Первая была специально разработана для перевода электронных текстов, вторая стала популярна благодаря своей компактности и простоте в использовании, последняя владеет широкими возможностями и вариантами перевода.
Параметры машинных переводчиков должны удовлетворять четырем основным требованиям:
- оперативность
- гибкость
- скорость
- точность
Оперативность заключается в возможности постоянного обновления словарного запаса и тематических разделов.
Гибкость рассчитана на конкретную предметную область.
Программа для распознавания текста. Как распознать текст с картинки
Скорость — возможность автоввода и обработки текстовой информации с бумаги. Одна такая система (OCR-System) ежедневно заменяет больше десяти опытных машинисток.
Точность заключается грамотности и адекватной передачи смысла переводимого текста на язык перевода.
Улучшение качества перевода
Существуют способы улучшения результатов машинного перевода:
1. Перед началом перевода, нужно определить тип текста, то есть из какой области жизнедеятельности человека он представлен (экономика, спорт, наука и т.д.). Ведь каждая сфера имеет свои нюансы и термины.
2. Часто причиной неправильного перевода являются опечатки переводимом тексте. Это касается и распознанных текстов. Слова с ошибками помечаются переводчиками как незнакомые, потому что в таком виде их нет в словарях. Хуже, если есть ошибки в пунктуации — одна неправильно поставленная запятая способна исказить перевод всего предложения.
3. Работайте с фрагментами текста. Никогда не переводите весь текст сразу. В нем всегда найдутся слова, отсутствующих в словаре и такие, которые система переводит неправильно.
Вопросы
1. Зачем нужны программы распознавания текста?
2. Как происходит распознавание текста?
3. Какие программы распознания текста вы знаете?
4. Требования к параметрам машинных переводчиков.
5. Методы улучшения качества перевода текста
Список использованных источников
1. Журавлев Ю.И. Об алгебраическом подходе к решению задач распознавания или классификации // Проблемы кибернетики. М.: Наука, 2005. — Вып. 33. С. 5-68
2. Растригин Л. А., Эренштейн Р. Х. Метод коллективного распознавания. 79 с. ил. 20 см., М. Энергоиздат, 2006. – 80 с.
3. Потапов А.С. Распознавание образов и машинное восприятие. — С-Пб.: Политехника, 2007 г.
4. А. Васильев. Компьютер на месте переводчика // Подводная лодка. – № 6.
5. Система перевода текста PROMT Internet. Руководство пользователя. — С.-Петербург, фирма «ПРОМТ.
6. www.free-ocr.сom
7. img2txt.ru
8. www.translate.ru
Отредактировано и выслано преподавателем Киевского национального университета им. Тараса Шевченко Соловьевым М. С.
Над уроком работали
Поставить вопрос о современном образовании, выразить идею или решить назревшую проблему Вы можете на Образовательном форуме, где на международном уровне собирается образовательный совет свежей мысли и действия. Создав блог, Вы не только повысите свой статус, как компетентного преподавателя, но и сделаете весомый вклад в развитие школы будущего. Гильдия Лидеров Образования открывает двери для специалистов высшего ранга и приглашает к сотрудничеству в направлении создания лучших в мире школ.
Источник: edufuture.biz
OCR — определение, преимущества, проблемы и варианты использования [инфографика]

OCR — это технология, позволяющая машинам считывать печатный текст и изображения. Он часто используется в бизнес-приложениях, таких как оцифровка документов для хранения или обработки, и в потребительских приложениях, таких как сканирование квитанции для возмещения расходов.
OCR означает оптическое распознавание символов. Термин «символ» относится как к буквам, так и к цифрам. Программное обеспечение OCR может распознавать, содержит ли данное изображение символы или нет, а затем идентифицировать символы внутри него.

Область распознавания
Ожидается, что в ближайшие годы мировой рынок оптического распознавания символов будет быстро расти. Размер рынка OCR был оценен в 8.93 млрд долларов США в 2021 году. Ожидается, что он будет расти на CAGR 15.4% в период с 2022 по 2030 год. Этот рост обусловлен растущим спросом на OCR в различных отраслях конечного использования, таких как здравоохранение, автомобилестроение и другие.
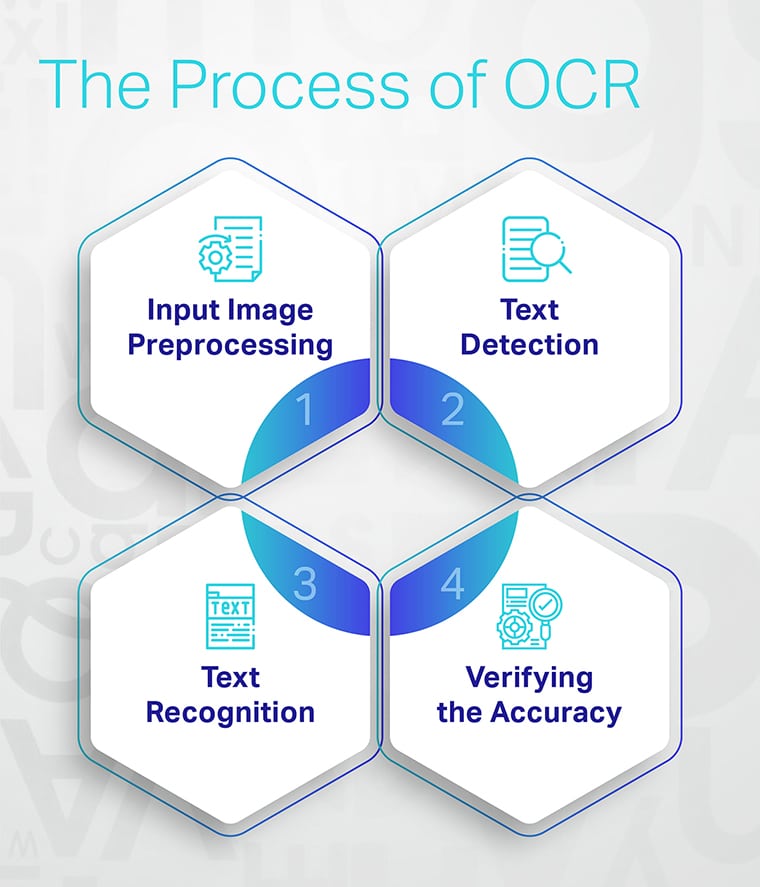
Процесс оптического распознавания символов
OCR — это подробный процесс, который помогает извлекать текст из изображений с помощью NLP.
- Первым шагом в OCR является обработка входного изображения. Это включает в себя очистку изображения и делает его пригодным для дальнейшей обработки.
- Затем механизм OCR ищет области, содержащие текст на изображении. Механизм сегментирует эти области на отдельные символы или слова, чтобы впоследствии их можно было идентифицировать при распознавании текста.
- Используя результаты обнаружения текста, механизм OCR идентифицирует каждый символ по его форме и размеру. Вы часто будете видеть сверточные и рекуррентные нейронные сети, иногда в комбинации, используемые для этой задачи.
- После того, как программное обеспечение OCR закончит распознавание текста в файле изображения, его необходимо проверить на точность, прежде чем его можно будет использовать.
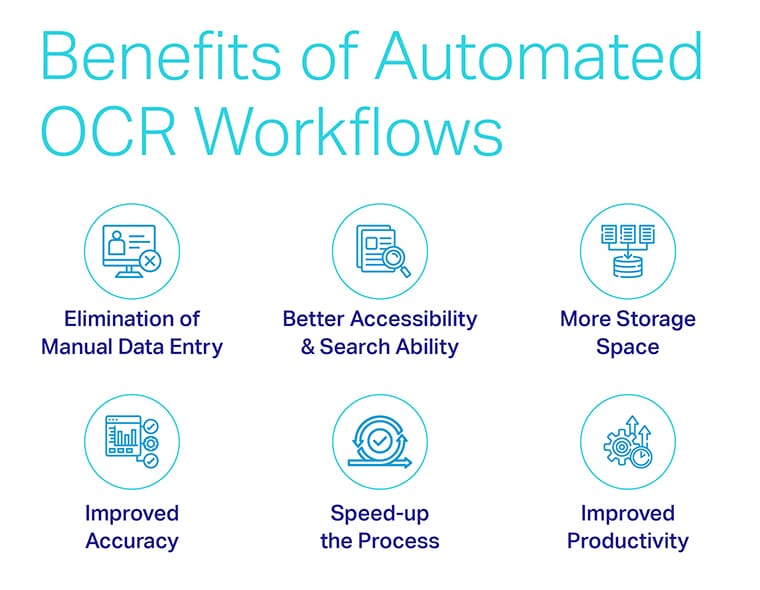
Преимущества автоматизированных рабочих процессов OCR
Ключевые преимущества автоматизированных рабочих процессов OCR включают в себя:
- Более быстрые и точные автоматические результаты при исключении человеческого фактора.
- Более низкая стоимость входа для малого бизнеса благодаря более быстрой обработке данных и эффективному использованию данных.
- Более стабильные результаты для нескольких пользователей и проектов.
- Улучшенное хранение данных и безопасность данных.
- Огромные возможности для масштабирования.

Вызовы
Основная проблема OCR заключается в том, что она не идеальна. Если вы представите, что читаете текст на этой странице с помощью камеры, а затем преобразуете эти изображения в слова, вы поймете, почему OCR может быть проблематичным. Некоторые из проблем OCR включают в себя:
- Размытый текст искажен тенями.
- Цвет фона и текста имеют схожие цвета.
- Части изображения обрезаются или полностью обрезаются (например, нижняя часть «этого»).
- Слабые знаки поверх некоторых букв (например, «i») могут сбить с толку программное обеспечение OCR, думая, что они являются частью буквы, а не знаками сверху.
- Различие типов и размеров шрифтов может быть затруднено при идентификации.
- Условия освещения при фотографировании или сканировании документа.

Случаи использования
- Автоматизация ввода данных: OCR можно использовать для автоматизации процесса ввода данных в базу данных.
- Сканирование штрих-кода: OCR позволяет компьютеру сканировать штрих-коды на продуктах и извлекать информацию о них из баз данных.
- Распознавание номерных знаков: OCR анализирует номерные знаки и извлекает из них такую информацию, как регистрационные номера и названия штатов.
- Проверка паспорта: OCR можно использовать для проверки подлинности паспортов, виз и других проездных документов.
- Распознавание этикеток магазинов: Магазины могут использовать OCR для автоматического считывания этикеток своих продуктов и сравнения их со своими каталогами продуктов, чтобы определить, какие продукты в настоящее время находятся на полках магазинов, какие товары отсутствуют на складе или есть ошибки на складе.
- Обработка страховых случаев: Программное обеспечение OCR может сканировать документы и проверять подписи, даты, адреса и другую информацию в формах, отправленных клиентами, которые подали иски о возмещении ущерба, причиненного стихийными бедствиями, пожарами или кражами.
- Чтение сигналов светофора: Систему OCR можно использовать для считывания цветов светофоров и определения того, являются ли они красными или зелеными.
- Считывание коммунальных счетчиков: Коммунальные предприятия используют OCR для считывания счетчиков электроэнергии, газа и воды, чтобы выставлять клиентам счета за правильные суммы.
- Мониторинг социальных сетей – Компании используют OCR для идентификации и классификации упоминаний компании или бренда в сообщениях социальных сетей, твитах и даже обновлениях Facebook.
- Проверка правоустанавливающих документов: Адвокатское бюро может сканировать такие документы, как контракты, договоры аренды и соглашения, чтобы убедиться, что они разборчивы и точны, прежде чем отправлять их клиентам.
- Многоязычные документы: Компании, которая продает товары в других странах, может потребоваться перевести свои маркетинговые материалы на несколько языков, а затем использовать их в качестве шаблонов для будущих проектов.
- Маркировка медицинских препаратов: OCR широко используется для извлечения значимой информации из этикеток лекарств, чтобы компьютерные системы могли анализировать и обрабатывать ее.

Индустрия
- Розничная: В розничной торговле используется OCR для сканирования штрих-кодов, информации о кредитных картах, квитанций и т. д.
- БФИ: Банки используют OCR для чтения чеков, депозитных ордеров и банковских выписок для проверки подписей и добавления транзакций к счетам. Они также могут анализировать большие объемы данных, чтобы принимать решения о счетах клиентов, инвестициях, кредитах и многом другом с помощью OCR.
- Правительство: OCR можно использовать для сканирования и оцифровки юридических документов, таких как свидетельства о рождении, водительские права и другие официальные записи.
- Образование: Учителя могут использовать OCR для создания цифровых копий книг и других студенческих документов. Учителя также могут сканировать документы на свои компьютеры и использовать технологию OCR для создания электронной копии, к которой учащиеся могут получить доступ в любое время.
- Здравоохранение: Врачам часто необходимо быстро ввести информацию о пациенте в компьютерную систему. Отрасль здравоохранения может использовать OCR для бизнес-процессов, таких как выставление счетов и обработка претензий.
- Производство – Производственным предприятиям часто требуется сканировать такие документы, как счета-фактуры или заказы на поставку. OCR можно использовать для «считывания» серийных номеров на компонентах продукта, когда они проходят по конвейерной ленте или по сборочной линии.
- Наши технологии: Программное обеспечение OCR используется во многих параметрах, связанных с ИТ, включая интеллектуальный анализ данных, анализ изображений, распознавание речи и многое другое. В разработке программного обеспечения OCR используется для преобразования отсканированных документов обратно в цифровые файлы.
- Транспорт и логистика: OCR можно использовать для чтения отгрузочных этикеток или контроля складских запасов. Он также может обнаруживать мошенничество, когда поставщики выставляют счета на оплату.
Вердикт
Процесс OCR относительно прост, требуется всего несколько шагов для преобразования изображения в текст. Есть некоторые ошибки и нестыковки, но технология бесспорно впечатляет, учитывая то, как все это работает.
Источник: ru.shaip.com
Презентация на тему Системы распознавания текста
Необходимость в системах распознавания символовС помощью сканера достаточно просто получить изображение страницы текста в графическом файле. Однако работать с таким текстом невозможно: как любое сканированное изображение, страница с текстом представляет собой
- Главная
- Разное
- Системы распознавания текста
Слайды и текст этой презентации
Слайд 1Системы распознавания текста
Технология обработки текстовой информации

Слайд 2Необходимость в системах распознавания символов
С помощью сканера достаточно просто получить
изображение страницы текста в графическом файле. Однако работать с таким
текстом невозможно: как любое сканированное изображение, страница с текстом представляет собой графический файл — обычную картинку. Текст можно будет читать и распечатывать, но нельзя будет его редактировать и форматировать. Для получения документа в формате текстового файла необходимо провести распознавание текста, то есть преобразовать элементы графического изображения в последовательности текстовых символов.

Слайд 3Программы распознавания текста
Преобразованием графического изображения в текст занимаются специальные программы
распознавания текста (Optical Character Recognition — OCR).
Наиболее распространенные системы оптического
распознавания символов:
BBYY FineReader
CuneiForm от Cognitive

Слайд 4Получение электронного документа
Отсканировать изображение (с помощью ПО сканера);
Распознать структуру размещения
текста на странице: выделить колонки, таблицы, изображения и т.д.
Выделенные
текстовые фрагменты графического изображения страницы необходимо преобразовать в текст;
Проверка орфографии (если необходимо);
Сохранение в файл или передача текста в другое приложение, например в Word.

Слайд 5Методы распознавания символов
Если исходный документ имеет типографское качество то задача
распознавания решается методом сравнения с растровым шаблоном.
При распознавании документов
с низким качеством печати используется метод распознавания символов по наличию в них определенных структурных элементов (отрезков, колец, дуг и др.).

Слайд 6ABBYY FineReader
FineReader — омнифонтовая система оптического распознавания текстов. Это означает,
что она позволяет распознавать тексты, набранные практически любыми шрифтами, без
предварительного обучения. Особенностью программы FineReader является высокая точность распознавания и малая чувствительность к дефектам печати.
FineReader имеет массы дополнительных функций и удобный интерфес.

Слайд 7Оптимальное разрешение при сканировании
Оптимальным разрешением для обычных текстов является —
300 dpi и 400-600 dpi для текстов, набранных мелким шрифтом
(9 и менее пунктов).
Сканирование в сером является оптимальным режимом для системы распознавания. В случае сканирования в сером режиме осуществляется автоматический подбор яркости. Если Вы хотите, чтобы содержащиеся в документе цветные элементы (картинки, цвет букв и фона) были переданы в электронный документ с сохранением цвета, необходимо выбрать цветной тип изображения. В других случаях используйте серый тип изображения.
Источник: theslide.ru